机器学习第二十五周周报 ConvLSTM
文章目录
- week 25 ConvLSTM
- 摘要
- Abstract
- 一、李宏毅机器学习
- 二、文献阅读
-
- 1. 题目
- 2. abstract
- 3. 网络架构
-
- 3.1降水预报问题的建模
- 3.2Convolutional LSTM
- 3.3编码-预测结构
- 4. 文献解读
-
- 4.1 Introduction
- 4.2 创新点
- 4.3 实验过程
-
- 4.3.1Moving-MNIST Dataset
- 4.3.2雷达回波数据集
- 4.4 结论
- 三、基于pytorch实现ConvLSTM
-
- 1.实验内容
- 2.实验结果
- 3.实验数据集
-
- 3.1数据集处理
- 4.模型及训练过程实现
- 小结
- 参考文献
week 25 ConvLSTM
摘要
本文主要讨论ConvLSTM的模型。本文简要介绍了自注意力机制运行逻辑。其次本文展示了题为Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting的论文主要内容。该论文将降水预报问题建模为时空序列预测问题,并根据FC-LSTM结构进行扩展,提出了ConvLSTM。该结构改善了FC-LSTM的缺点,通过其局部邻域的输入和过去状态来确定网格中某个单元的未来状态。该文在多个数据集上进行实验,从数据角度证明了该网络的优越性。最后,本文基于pytorch实现了ConvLSTM模型并在KTH数据集上进行验证。
Abstract
This article mainly discusses the model of ConvLSTM. This article briefly introduces the operating logic of the self-attention mechanism. Secondly, this paper presents the main content of the paper entitled Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. In this paper, this paper models the precipitation prediction problem as a spatiotemporal series prediction problem, and proposes the ConvLSTM by extending it according to the FC-LSTM structure. This structure improves on the shortcomings of FC-LSTM by determining the future state of an element in the grid through the input and past state of its local neighborhood. In this paper, experiments are carried out on multiple datasets to prove the superiority of the network from the perspective of data. Finally, this article implements the ConvLSTM model based on pytorch and validates on the KTH dataset.
一、李宏毅机器学习

二、文献阅读
1. 题目
题目:Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting
作者:Xingjian Shi, Zhourong Chen, Hao Wang, Dit-Yan Yeung, Wai-kin Wong, Wang-chun Woo
链接:https://arxiv.org/pdf/1506.04214.pdf
发布:NIPS’15: Proceedings of the 28th International Conference on Neural Information Processing Systems - Volume 1December 2015Pages 802–810
2. abstract
在本文中,将降水临近预报表述为时空序列预测问题,其中输入和预测目标都是时空序列。通过扩展全连接 LSTM (FC-LSTM) 以在输入到状态和状态到状态转换中都具有卷积结构,提出了卷积 LSTM (ConvLSTM) 并用它来构建端到端降水临近预报问题的可训练模型。实验表明,ConvLSTM 网络可以更好地捕获时空相关性,并且始终优于 FC-LSTM 和最先进的降水临近预报操作 ROVER 算法。
This paper formulates precipitation nowcasting as a spatiotemporal sequence forecasting problem in which both the input and the prediction target are spatiotemporal sequences. By extending the fully connected LSTM (FC-LSTM) to have convolutional structures in both the input-to-state and
state-to-state transitions, this paper proposes the convolutional LSTM (ConvLSTM) and uses it to build an end-to-end trainable model for the precipitation nowcasting problem. Experiments show that ConvLSTM network captures spatiotemporal correlations better and consistently outperforms FC-LSTM and the state-of-the-art operational ROVER algorithm for precipitation nowcasting.
3. 网络架构
3.1降水预报问题的建模
对流降水临近预报一直是天气预报领域的一个重要问题。该任务的目标是准确、及时地预测局部区域在相对较短的时间内(例如0-6小时)的降雨强度。
假设在一个由M行和N列组成的 M × N M\times N M×N网格表示的空间区域内观测到一个动态系统。在网络个的每个单元格内,都有随着时间变化的P个观测值。因此,任何时刻的观测值都可以使用张量 X ∈ R P × M × N \mathcal X\in \mathbf R^{P\times M\times N} X∈RP×M×N来表示,其中 R \mathbf R R表示观测到的特征的域。如果定期记录观测值,将得到 X ^ 1 , X ^ 2 , … , X ^ t \mathcal {\hat X}_1,\mathcal {\hat X}_2,\dots, \mathcal {\hat X}_t X^1,X^2,…,X^t。时空序列预测问题是在给定前J个观测值的情况下,预测未来最可能的长度K序列:
X ^ t + 1 , … , X ^ t + K = argmax X t + 1 , … , X t + K p ( X t + 1 , … , X t + K ∣ X ^ t − J + 1 , X ^ t − J + 2 , … , X t ) (1) \mathcal {\hat X}_{t+1},\dots,\mathcal {\hat X}_{t+K}=\text{argmax}_{\mathcal X_{t+1},\dots, \mathcal X_{t+K}}p(\mathcal {X_{t+1}},\dots, \mathcal{X}_{t+K}|\mathcal {\hat X}_{t-J+1},\mathcal {\hat X}_{t-J+2},\dots, \mathcal {X}_t) \tag{1} X^t+1,…,X^t+K=argmaxXt+1,…,Xt+Kp(Xt+1,…,Xt+K∣X^t−J+1,X^t−J+2,…,Xt)(1)
对于降水预报,每个时间戳的观测都是一幅二维雷达回波图。若将地图划分为平铺的、不重叠的贴片,并将贴片内的像素作为其测量值。
LSTM不再赘述直接描述网络结构
3.2Convolutional LSTM
FC-LSTM在处理时空数据中的主要缺点是它在输入到状态和状态到状态转换中的全连接的使用,其中没有空间信息被编码。为了克服这个问题,进行针对性设计,
- 输入是 X 1 , X 2 , … , X t \mathcal {X}_1,\mathcal {X}_2,\dots, \mathcal {X}_t X1,X2,…,Xt
- 单元输出 C 1 , C 2 , … , C t \mathcal C_1,\mathcal C_2,\dots, \mathcal C_t C1,C2,…,Ct
- 隐藏状态 H 1 , … , H t \mathcal H_1,\dots, \mathcal H_t H1,…,Ht
- ConvLSTM的门: i t , f t , o t i_t,f_t,o_t it,ft,ot
以上均为3D张量,其最后两个维度是空间维度
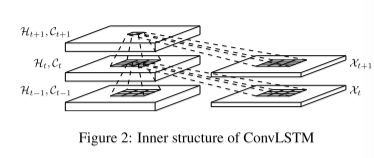
ConvLSTM 通过其局域邻域的输入和过去状态来确定网格中某个单元的未来状态。通过在状态到状态和输入到状态转换中使用卷积算子轻松实现,如上图。ConvLSTM的关键方程如下面,*为卷积算子, ∘ \circ ∘为卷积算子

若将状态视为移动对象的隐式表示,则具有较大内核的ConvLSTM应该能够捕获更快的运动,而具有较小卷积核的可以捕获较慢的运动。此外,FC-LSTM可以看作所有特征均在一个单元格上的ConvLSTM。
为了确保状态具有与输入相同的行数和相同数量的列,在应用卷积操作之前需要padding。在这里,隐藏状态的embedding在可以将边界点视为使用外部世界的状态进行计算。
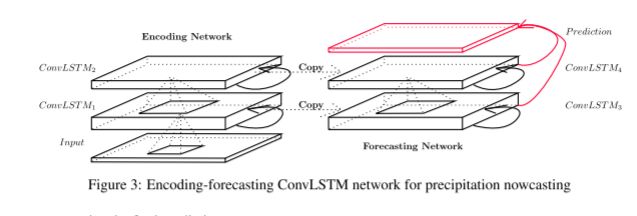
3.3编码-预测结构
ConvLSTM可以作为更为复杂结构的模块。对于时空序列预测问题,使用下图所示的结构。两个网络、一个编码网络和一个预测网络。预测网络的初始状态和单元输出均是从编码网络的最后一个状态复制得到。这两个网络都是通过堆叠几个ConvLSTM层来形成的,由于预测目标具有与输入相同的位数,故将预测网

4. 文献解读
4.1 Introduction
对流降水临近预报一直是天气预报领域的一个重要问题。该任务的目标是准确、及时地预测局部区域在相对较短的时间内(例如0-6小时)的降雨强度。ROVER算法是领域现有的最先进算法。深度学习的最新进展,特别是循环神经网络 (RNN) 和长短期记忆 (LSTM) 模型,提供了一些关于如何解决这个问题的途径。[2]中提出的开创性的 LSTM 编码器-解码器框架通过训练时间级联的 LSTM。但以往的模型均采用的全连接LSTM(FC-LSTM)层没有考虑空间相关性。
在本文中,提出了一种用于降水临近预报的新型ConvLSTM网络。将降水临近预报表述为一个时空序列预测问题,可以在[2]中提出的通用序列到序列学习框架下解决。为了更好地模拟时空关系,将FC-LSTM的思想扩展到在输入-状态和状态-状态转换两者中具有卷积结构的COVLSTM。当对合成Moving-MNIST数据集和雷达回波数据集进行评估时,ConvLSTM模型始终优于FC-LSTM和最先进的操作ROVER算法。
4.2 创新点
- 将降水预报问题建模为时空序列预测问题,从而在[2]中提出的框架内解决。
- 根据FC-LSTM结构进行扩展,提出了ConvLSTM,该结构改善了FC-LSTM的缺点,通过其局部邻域的输入和过去状态来确定网格中某个单元的未来状态。
- 将ConvLSTM网络与一个合成MovingMNIST数据集中的FC-LSTM网络进行比较。建立了一个新的雷达回波数据集,并将该模型与基于几种常用降水预报指标的最先进的ROVER算法进行了比较。
4.3 实验过程
首先将ConvLSTM网络与一个合成MovingMNIST数据集中的FC-LSTM网络进行比较,以获得对模型的行为的一些基本理解。用不同的规格运行模型根据[3]中的层和内核大小,并研究一些“域外域”情况。为了验证模型在更具有挑战性的降水预报问题上的有效性,建立了一个新的雷达回波数据集,并将模型与基于几种常用降水预报指标的最先进的ROVER算法进行了比较。
在python环境下实现了该模型,并在配备了单个NVIDIA K20 GPU的计算机上运行所有实验。
4.3.1Moving-MNIST Dataset
数据预处理以及部分训练参数:使用类似[3]中描述的生成过程。数据集中所有数据实例长20帧(输入10帧,预测10帧),并包含在 64 × 64 64\times 64 64×64patch内的手写数字。移动数字从MNIST数据集中500位子集中随机选择。开始位置和速度方向都是随机选择的,速度振幅是随机选择的。该生成过程重复了15000次,得到了包含10000条训练序列、2000条验证序列和3000条测试序列的数据集。通过使用反向传播时间(BPTT)最小化交叉熵损失来训练所有LSTM模型,并且RMSProp,学习速率为10×3,衰减率为0.9。此外,在验证集上执行early-stop。
实验中使用的网络框架:对于FC-LSTM网络,使用了与[3]中具有两个2048节点的LSTM层的无条件未来预测器模型相同的结构。对于ConvLSTM网络,将patch size设置为4×4,这样每个64×64帧由16×16×16张量表示。用不同的层数测试模型的三种变体。
- 1层网络包含一个包含256个隐藏状态的ConvLSTM层
- 2层网络有两个ConvLSTM层,每个层有128个隐藏状态
- 3层网络在三个ConvLSTM层中分别有128、64和64隐藏状态
所有输入到状态和状态到状态的内核大小为5×5
实验表明,ConvLSTM 网络的性能始终优于 FC-LSTM 网络,更深层的网络结构可以提供更好的结果
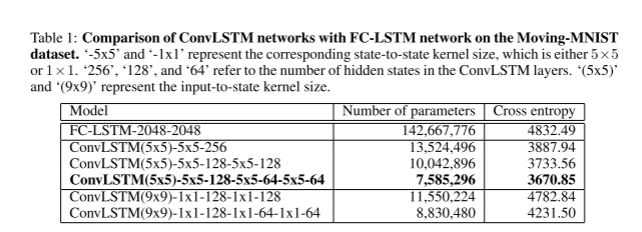
上图为ConvLSTM 网络与 FC-LSTM 网络在 Moving-MNIST 数据集上的比较结果,即各算法在测试集上的平均交叉熵损失。‘-5x5’和‘-1x1’表示相应的状态到状态内核大小,即5×5或1×1。 “256”、“128”和“64”指的是 ConvLSTM 层中隐藏状态的数量。 ‘(5x5)’和‘(9x9)’表示输入到状态的内核大小。
可以看出ConvLSTM在参数更少的情况下,达到了更好的结果
4.3.2雷达回波数据集
所使用的雷达回波数据集是2011年至2013年在香港收集的3年天气雷达强度的子集。由于不是每天都下雨,预报目标是降水,选择前97个雨天形成数据集。
数据预处理:首先通过设置 P = Z − min ( Z ) max ( Z ) − min ( Z ) P=\frac{Z-\min(Z)}{\max(Z)-\min(Z)} P=max(Z)−min(Z)Z−min(Z)将强度值Z转换为灰度像素P,并在中心 330 × 330 330\times 330 330×330区域裁剪雷达图。之后将带有半径10的磁盘过滤器应用至 100 × 100 100\times 100 100×100范围内,并调整雷达图的大小。为了减少测量仪器带来的噪声,进一步去除了一些噪声区域的像素值,这些区域是通过将K-Means聚类方法应用于每月像素平均值来确定的。天气雷达数据每6分钟记录一次,因此每天有240帧。为了获得不相交的训练、测试和验证子集,将每个日序列划分为40个不重叠的帧块,并随机分配4个块进行训练,1块用于测试并且1块用于验证。数据实例是使用一个20帧宽的滑动窗口从这些块中分割出来的。因此,雷达回波数据集包含8148个训练序列,2037个测试序列和2037个验证序列,所有序列都有20帧长(输入5帧,预测15帧)。
训练以及模型参数设置:
-
patch size设置为2,并训练一个包含64个隐藏状态和3×3个内核的2层ConvLSTM网络
-
对于ROVER算法,在验证集上调整光流估计器的参数,并使用最佳参数报告测试结果。
此外,还尝试了三种不同的Rover初始化方案:
- ROVER 1计算最后两个观测帧的光流,然后进行半拉格朗日平流;
- ROVER 2以最后两个流场的平均值初始化速度;
- ROVER 3给出最后三个流场的加权平均值(权重分别为0.7、0.2和0.1)初始化
-
此外,还训练了一个具有两个 2000 节点 LS TM层的 FC-LSTM 网络。
无论是 ConvLSTM 网络还是 FC-LSTM 网络都优化了 15 个预测的交叉
使用几种常用的降水预报指标,即雨量均方误差(雨量均方误差)、关键成功指数(CSI)、虚警率(Far)、检测概率(POD)以及相关性来评价这些方法。
降雨量 MSE 指标定义为预测降雨量与实际降雨量之间的平均平方误差。
三个技能分数定义为
-
C S I = h i t s h i t s + m i s s e s + f a l s e a l a r m s CSI=\frac{hits}{hits+misses+falsealarms} CSI=hits+misses+falsealarmshits
-
F A R = f a l s e a l a r m s h i t s + f a l s e a l a r m s FAR=\frac{falsealarms}{hits+falsealarms} FAR=hits+falsealarmsfalsealarms
-
P O D = h i t s h i t s + m i s s e s POD=\frac{hits}{hits+misses} POD=hits+misseshits
预测框架P与地面真框架T的相关性定义为:
∑ i , j P i , j T i . j ( ∑ i , j P i , j 2 ) ( ∑ i , j T i , j 2 ) + ϵ \frac{\sum_{i,j}P_{i,j}T_{i.j}}{\sqrt{(\sum_{i,j}P_{i,j}^2)(\sum_{i,j}T_{i,j}^2)+\epsilon}} (∑i,jPi,j2)(∑i,jTi,j2)+ϵ∑i,jPi,jTi.j
其中 ϵ = 1 0 − 9 \epsilon=10^{-9} ϵ=10−9
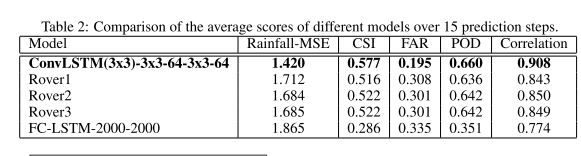
下图为比较不同模型 15 个预测步骤的平均得分
下图为基于四种降水临近预报指标的不同模型随时间的比较结果

ConvLSTM能够更准确地预测未来的降水等高线,特别是在边界上。虽然 ROVER2 可以给出比 ConvLSTM 更清晰的预测,但它会触发更多的虚假警报,而且通常比 ConvLSTM 更不精确。另外,ConvLSTM的模糊效应可能是由于任务本身的不确定性造成的。
4.4 结论
在这两个数据集上进行的实验结果得出以下结论:
- ConvLSTM在处理时空相关性方面优于FC-LSTM.
- 使得状态到状态卷积核的大小大于1对于捕获时空运动模式是必要的。
- 更深层次的模型可以较少的参数产生更好的结果。
- ConvLSTM在降水预报方面的性能优于ROVER。
三、基于pytorch实现ConvLSTM
1.实验内容
基于pytorch实现ConvLSTM并使用KTH数据集进行测试
2.实验结果
训练过程如下
Epochs[1/50]--batch[0/402]--Acc: 0.1562--loss: 1.7924
Epochs[1/50]--batch[50/402]--Acc: 0.4375--loss: 1.6179
Epochs[1/50]--batch[100/402]--Acc: 0.375--loss: 1.3734
Epochs[1/50]--batch[150/402]--Acc: 0.3438--loss: 1.2532
Epochs[1/50]--batch[200/402]--Acc: 0.4375--loss: 1.2269
Epochs[1/50]--batch[250/402]--Acc: 0.5625--loss: 0.925
Epochs[1/50]--batch[300/402]--Acc: 0.5938--loss: 0.8918
Epochs[1/50]--batch[350/402]--Acc: 0.5--loss: 1.085
Epochs[1/50]--Acc on val 0.5182
Epochs[30/50]--Acc on val 0.6551
3.实验数据集
本实验使用KTH数据集,共有六个类别,包括Boxing(拳击)、Handclapping(鼓掌)、Handwaving(挥手)、Jogging(慢跑)、Running(快跑)和Walking(行走)。共计600个视频文件。
3.1数据集处理
is_gray:是否转换为灰度图
frame_len以该长度对视频进行分割
transforms:进行图像增强
__init__:初始化操作
def load_avi_frames:数据载入;
- 创建一个视频捕获对象,用于读取视频文件;
- 循环读取视频帧,直到视频结束;
- 检查是否成功读取到帧图像数据;
- 将原始图片转换为灰度图,因为后续数据集用作分类所以转换为单通道的灰度图可以降低计算量;
- 返回得到一个4维数组
def data_process:样本构建
- 缓存预处理结果的修饰器
- 循环遍历每个目录下的视频文件,并得到该目录下所有视频文件的名称
- 开始遍历当前文件夹中的每个视频文件
- 根据文件名获取对应的人物编号
- 读取得到原始的视频数据;
- 根据每个视频以固定长度进行采样构造样本,其中sub_frames
的形状为[frame_len,120,160,channels]`; - 返回最后构造完成的样本数据。
def generate_batch:实现一个辅助函数来处理每个小批量样本的数据
- 遍历小批量样本中的每个样本;
- 循环对视频里的每一帧进行图像增强,其中
frame的形状为[height, width, channels],在进行图像增强经过ToTensor()变换后形状会变成[channels,height,width]且每个像素值的范围会被缩放至 - 将所有样本堆叠构造得到一个小批量标准数据,其形状为
[batch_size, frame_len, channels, height, width]。
def load_train_val_test_data:编码实现迭代器的构建
- 返回
data_process方法采样得到的原始样本数据; - 构建得到测试集对应的迭代器,其中
generate_batch方法将作为参数传入到类DataLoader中进行使用; - 构建得到训练集和验证集对应的迭代器。
class KTHData(object):
"""
载入KTH数据集,下载地址:https://www.csc.kth.se/cvap/actions/ 一共包含6个zip压缩包
"""
DATA_DIR = os.path.join(DATA_HOME, 'kth')
CATEGORIES = ["boxing", "handclapping", "handwaving", "jogging", "running", "walking"]
TRAIN_PEOPLE_ID = [1, 2, 4, 5, 6, 7, 9, 11, 12, 15, 17, 18, 20, 21, 22, 23, 24] # 25*0.7 = 17
VAL_PEOPLE_ID = [3, 8, 10, 19, 25] # 25*0.2 = 5
TEST_PEOPLE_ID = [13, 14, 16] # 25*0.1 = 3
FILE_PATH = os.path.join(DATA_DIR, 'kth.pt')
def __init__(self, frame_len=15,
batch_size=4,
is_sample_shuffle=True,
is_gray=True,
transforms=None):
self.frame_len = frame_len # 即time_step, 以FRAME_LEN为长度进行分割
self.batch_size = batch_size
self.is_sample_shuffle = is_sample_shuffle
self.is_gray = is_gray
self.transforms = transforms
@staticmethod
def load_avi_frames(path=None, is_gray=False):
"""
用来读取每一个.avi格式的文件
:param path:
:return:
"""
import cv2
logging.info(f" ## 正在读取原始文件: {path}并划分数据")
video = cv2.VideoCapture(path)
frames = []
while video.isOpened():
ret, frame = video.read() # frame: (120, 160, 3) 4.模型及训练过程实现
参照论文实现ConvLSTM
ConvLSTMCell:记忆单元
class ConvLSTMCell(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, bias):
"""
Initialize ConvLSTM cell.
Parameters
----------
in_channels: int 输入特征图的通道数
out_channels: int 输出特征图的通道数
kernel_size: (int, int) 卷积核的宽和高
bias: bool 是否使用偏置
"""
super(ConvLSTMCell, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = kernel_size
self.padding = kernel_size[0] // 2, kernel_size[1] // 2
# 需要强制进行padding以保证每次卷积后形状不发生变化
# 根据之前第4.3.2节内容的介绍,在stride=1的情况下,padding = kernel_size // 2
# 如:卷积核为3×3则需要padding=1即可
# 在下面的卷积操作中stride使用的是默认值1
self.bias = bias
self.conv = nn.Conv2d(in_channels=self.in_channels + self.out_channels,
out_channels=4 * self.out_channels,
kernel_size=self.kernel_size,
padding=self.padding,
bias=self.bias)
def forward(self, input_tensor, last_state):
"""
:param input_tensor: 当前时刻的输入x_t, 形状为[batch_size, in_channels, height, width]
:param last_state: 上一时刻的状态c_{t-1}和h_{t-1}, 形状均为 [batch_size, out_channels, height, width]
:return:
"""
h_last, c_last = last_state
combined_input = torch.cat([input_tensor, h_last], dim=1)
# [batch_size, in_channels+out_channels, height, width]
combined_conv = self.conv(combined_input) # [batch_size, 4 * out_channels, height, width]
cc_i, cc_f, cc_o, cc_g = torch.split(combined_conv, self.out_channels, dim=1)
# 分割得到每个门对应的卷积计算结果,形状均为 [batch_size, out_channels, height, width]
i = torch.sigmoid(cc_i)
f = torch.sigmoid(cc_f)
o = torch.sigmoid(cc_o)
g = torch.tanh(cc_g)
c_next = f * c_last + i * g # [batch_size, out_channels, height, width]
h_next = o * torch.tanh(c_next) # [batch_size, out_channels, height, width]
return h_next, c_next
def init_hidden(self, batch_size, image_size):
"""
初始化记忆单元的C和H
:param batch_size:
:param image_size:
:return:
"""
height, width = image_size
return (torch.zeros(batch_size, self.out_channels, height, width, device=self.conv.weight.device),
torch.zeros(batch_size, self.out_channels, height, width, device=self.conv.weight.device))
ConvLSTM:模型
class ConvLSTM(nn.Module):
"""
Parameters:
in_channels: 输入特征图的通道数,为整型
out_channels: 每一层输出特征图的通道数,可为整型也可以是列表;
为整型时表示每一层的输出通道数均相等,为列表时则列表的长度必须等于num_layer
例如 out_channels =[32,64,128] 表示3层ConvLSTM的输出特征图通道数分别为
32、64和128,且此时的num_layer也必须为3
kernel_size: 每一层中卷积核的长和宽,可以为一个tuple,如(3,3)表示每一层的卷积核窗口大小均为3x3;
也可以是一个列表分别用来指定每一层卷积核的大小,如[(3,3),(5,5),(7,7)]表示3层卷积各种的窗口大小
此时需要注意的是,如果为列表也报保证其长度等于num_layer
num_layers: ConvLSTM堆叠的层数
batch_first: 输入数据的第1个维度是否为批大小
bias: 卷积中是否使用偏置
return_all_layers: 是否返回每一层各个时刻的输出结果
Input:
A tensor of size B, T, C, H, W or T, B, C, H, W
[Batch_size, Time_step, Channels, Height, Width] or [Time_step, Batch_size, Channels, Height, Width]
Output:
当return_all_layers 为 True 时:
layer_output_list: 每一层的输出结果,包含有num_layer个元素的列表,
每个元素的形状为[batch_size, time_step, out_channels, height, width]
last_states: 每一层最后一个时刻的输出结果,同样是包含有num_layer个元素的列表,
列表中的每个元素均为一个包含有两个张量的列表,
如last_states[-1][0]和last_states[-1][1]分别表示最后一层最后一个时刻的h和c
layer_output_list[-1][:, -1] == last_states[-1][0]
shape: [Batch_size, Channels, Height, Width]
当return_all_layers 为 False 时:
layer_output_list: 最后一层每个时刻的输出,形状为 [batch_size, time_step, out_channels, height, width]
last_states: 最后一层最后一个时刻的输出,形状为 [batch_size, out_channels, height, width]
Example:
>> model = ConvLSTM(in_channels=3,
out_channels=2,
kernel_size=(3, 3),
num_layers=3,
batch_first=True,
bias=True,
return_all_layers=True)
x = torch.rand((1, 4, 3, 5, 5)) # [batch_size, time_step, channels, height, width]
layer_output_list, last_states = model(x)
"""
def __init__(self, in_channels, out_channels, kernel_size, num_layers,
batch_first=False, bias=True, return_all_layers=False):
super(ConvLSTM, self).__init__()
self._check_kernel_size_consistency(kernel_size)
# 检查kernel_size是否符合上面说的取值情况
# Make sure that both `kernel_size` and `out_channels` are lists having len == num_layers
kernel_size = self._extend_for_multilayer(kernel_size, num_layers)
out_channels = self._extend_for_multilayer(out_channels, num_layers)
# 将kernel_size和out_channels扩展到多层时的情况
if not len(kernel_size) == len(out_channels) == num_layers:
raise ValueError('len(kernel_size) == len(out_channels) == num_layers 三者的值必须相等')
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = kernel_size
self.num_layers = num_layers
self.batch_first = batch_first
self.bias = bias
self.return_all_layers = return_all_layers
cell_list = []
for i in range(0, self.num_layers): # 实例化每一层的ConvLSTM记忆单
cur_in_channels = self.in_channels if i == 0 else self.out_channels[i - 1]
# 当前层的输入通道数,除了第一层为self.in_channels之外,其它的均为上一层的输出通道数
cell_list.append(ConvLSTMCell(in_channels=cur_in_channels, out_channels=self.out_channels[i],
kernel_size=self.kernel_size[i], bias=self.bias))
self.cell_list = nn.ModuleList(cell_list)
# 必须要放到nn.ModuleList,否则在GPU上云运行时会报错张量不在同一个设备上的问题
def forward(self, input_tensor, hidden_state=None):
"""
Parameters
----------
input_tensor: todo
5-D Tensor: [Batch_size, Time_step, Channels, Height, Width] or
[Time_step, Batch_size, Channels, Height, Width]
hidden_state: todo
None. todo implement stateful
Returns
-------
last_state_list, layer_output
"""
if not self.batch_first:
# 将(t, b, c, h, w) 转为 (b, t, c, h, w)
input_tensor = input_tensor.permute(1, 0, 2, 3, 4)
batch_size, time_step, _, height, width = input_tensor.size()
# Implement stateful ConvLSTM
if hidden_state is not None:
raise NotImplementedError()
else:
# Since the init is done in forward. Can send image size here
hidden_state = self._init_hidden(batch_size=batch_size,
image_size=(height, width))
layer_output_list = [] # 保存每一层的输出h,每个元素的形状为[batch_size, time_step, out_channels, height, width]
last_state_list = [] # 保存每一层最后一个时刻的输出h和c,即[(h,c),(h,c)...]
cur_layer_input = input_tensor # [batch_size, time_step, in_channels, height, width]
for layer_idx in range(self.num_layers):
h, c = hidden_state[layer_idx] # 开始遍历每一层的ConvLSTM记忆单元,并取对应的初始值
# h 和 c 的形状均为[batch_size, out_channels, height, width]
output_inner = []
cur_layer_cell = self.cell_list[layer_idx] # 为一个ConvLSTMCell记忆单元
for t in range(time_step): # 对于每一层的记忆单元,按照时间维度展开进行计算
h, c = cur_layer_cell(input_tensor=cur_layer_input[:, t, :, :, :], last_state=[h, c])
output_inner.append(h) # 当前层,每个时刻的输出h, 形状为 [batch_size, out_channels, height, width]
layer_output = torch.stack(output_inner, dim=1) # [batch_size, time_step, out_channels, height, width]
cur_layer_input = layer_output # 当前层的输出h,作为下一层的输入
layer_output_list.append(layer_output)
last_state_list.append([h, c])
if not self.return_all_layers:
layer_output_list = layer_output_list[-1:]
last_state_list = last_state_list[-1:]
return layer_output_list, last_state_list
def _init_hidden(self, batch_size, image_size):
"""
init_states中的每个元素为一个tuple,包含C和H两个部分,如 [(h,c),(h,c)...]
形状均为 [batch_size, out_channels, height, width]
:param batch_size:
:param image_size:
:return:
"""
init_states = []
for i in range(self.num_layers): # 初始化每一层的初始值
init_states.append(self.cell_list[i].init_hidden(batch_size, image_size))
return init_states
@staticmethod
def _check_kernel_size_consistency(kernel_size):
if not (isinstance(kernel_size, tuple) or
(isinstance(kernel_size, list) and all([isinstance(elem, tuple) for elem in kernel_size]))):
raise ValueError('`kernel_size` must be tuple or list of tuples')
@staticmethod
def _extend_for_multilayer(param, num_layers):
if not isinstance(param, list):
param = [param] * num_layers
return param
ConvLSTMKTH:针对数据集进行改进
class ConvLSTMKTH(nn.Module):
def __init__(self, config=None):
super().__init__()
self.conv_lstm = ConvLSTM(config.in_channels, config.out_channels,
config.kernel_size, config.num_layers, config.batch_first)
self.max_pool = nn.MaxPool2d(kernel_size=(5, 5), stride=2, padding=2)
self.hidden_dim = (config.width * config.height) // 4 * self.conv_lstm.out_channels[-1]
# 除以4是因为长宽均要除以stride, 使用self.conv_lstm.out_channels[-1]
# 主要是为了兼容out_channels传入整型或列表的情况,因为传入整型的话在ConvLSTM的初始化方法中_extend_for_multilayer()
# 方法也会将其扩充一个list
self.classifier = nn.Sequential(nn.Flatten(),
nn.Linear(self.hidden_dim, config.num_classes))
def forward(self, x, labels=None):
"""
:param x: [batch_size, time_step, channels, height, width]
:param labels: [batch_size,]
:return: logits: [batch_size, num_classes]
"""
_, layer_output = self.conv_lstm(x)
# layer_output: [h:[batch_size, out_channels, height, width], c:[batch_size, out_channels, height, width]]
pool_output = self.max_pool(layer_output[-1][0]) # [batch_size, out_channels, height//2, width//2]
logits = self.classifier(pool_output) # [batch_size, num_classes]
if labels is not None:
loss_fct = nn.CrossEntropyLoss(reduction='mean')
loss = loss_fct(logits, labels)
return loss, logits
else:
return logits
ModelConfig:模型参数设置
class ModelConfig(object):
def __init__(self):
self.batch_size = 32
self.epochs = 30
self.learning_rate = 3e-3
self.num_classes = 6
self.in_channels = 1
self.out_channels = [32,32]
self.kernel_size = [(3, 3), (3, 3)]
self.num_layers = len(self.out_channels)
self.height = 60 # 原始大小为120
self.width = 80 # 原始大小为160
self.time_step = 15
self.num_warmup_steps = 200
self.model_save_path = 'model.pt'
self.summary_writer_dir = "runs/model"
self.device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# 判断是否存在GPU设备,其中0表示指定第0块设备
logging.info("### 将当前配置打印到日志文件中 ")
for key, value in self.__dict__.items():
logging.info(f"### {key} = {value}")
训练过程
def train(config):
trans = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((config.height, config.width)),
transforms.RandomHorizontalFlip(0.5)])
data_load = KTHData(frame_len=config.time_step,
batch_size=config.batch_size,
transforms=trans)
train_iter, val_iter = data_load.load_train_val_test_data(is_train=True)
model = ConvLSTMKTH(config)
if os.path.exists(config.model_save_path):
logging.info(f" # 载入模型{config.model_save_path}进行追加训练...")
checkpoint = torch.load(config.model_save_path)
model.load_state_dict(checkpoint)
optimizer = torch.optim.Adam(model.parameters(), lr=config.learning_rate)
writer = SummaryWriter(config.summary_writer_dir)
model = model.to(config.device)
max_test_acc = 0
steps = len(train_iter) * config.epochs
scheduler = optimization.get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=config.num_warmup_steps,
num_training_steps=steps, num_cycles=2)
for epoch in range(config.epochs):
for i, (x, y) in enumerate(train_iter):
x, y = x.to(config.device), y.to(config.device)
loss, logits = model(x, y)
optimizer.zero_grad()
loss.backward()
optimizer.step() # 执行梯度下降
scheduler.step()
if i % 50 == 0:
acc = (logits.argmax(1) == y).float().mean()
logging.info(f"Epochs[{epoch + 1}/{config.epochs}]--batch[{i}/{len(train_iter)}]"
f"--Acc: {round(acc.item(), 4)}--loss: {round(loss.item(), 4)}")
writer.add_scalar('Training/Accuracy', acc, scheduler.last_epoch)
writer.add_scalar('Training/Loss', loss.item(), scheduler.last_epoch)
test_acc = evaluate(val_iter, model, config.device)
logging.info(f"Epochs[{epoch + 1}/{config.epochs}]--Acc on val {test_acc}")
writer.add_scalar('Testing/Accuracy', test_acc, scheduler.last_epoch)
if test_acc > max_test_acc:
max_test_acc = test_acc
state_dict = deepcopy(model.state_dict())
torch.save(state_dict, config.model_save_path)
模型评估
def evaluate(data_iter, model, device):
model.eval()
with torch.no_grad():
acc_sum, n = 0.0, 0
for x, y in data_iter:
x, y = x.to(device), y.to(device)
logits = model(x)
acc_sum += (logits.argmax(1) == y).float().sum().item()
n += len(y)
model.train()
return acc_sum / n
使用模型进行预测
def inference(config, ):
trans = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((config.height, config.width)),
transforms.RandomHorizontalFlip(0.5)])
data_load = KTHData(frame_len=config.time_step,
batch_size=config.batch_size,
transforms=trans)
test_iter = data_load.load_train_val_test_data(is_train=False)
model = ConvLSTMKTH(config)
model.to(config.device)
model.eval()
if os.path.exists(config.model_save_path):
logging.info(f" # 载入模型进行推理……")
checkpoint = torch.load(config.model_save_path)
model.load_state_dict(checkpoint)
else:
raise ValueError(f" # 模型{config.model_save_path}不存在!")
first_batch = next(iter(test_iter))
with torch.no_grad():
logits = model(first_batch[0].to(config.device))
y_pred = logits.argmax(1)
logging.info(f"真实标签为:{first_batch[1]}")
logging.info(f"预测标签为:{y_pred}")
小结
本文主要介绍了自注意力机制以及ConvLSTM,在上周的学习中论文将二者结合,从而实现了时空序列预测领域中较好的结果。本文在KTH数据集上实现了该结构,根据数据集构造了迭代器以及进行了模型重构。最后在该环境下进行了模型有效性验证,得到了较好的结果。
下周将继续阅读序列预测相关论文
参考文献
[1] Shi, X.; Chen, Z.; Wang, H.; Yeung, D.-Y.; Wong, W.-K.;and Woo, W.-c. 2015. Convolutional lstm network: A machine learning approach for precipitation nowcasting. In NIPS 2015, 802–810.
[2]I. Sutskever, O. Vinyals, and Q. V. Le. Sequence to sequence learning with neural networks. In NIPS, pages 3104–3112, 2014.
[3]N. Srivastava, E. Mansimov, and R. Salakhutdinov. Unsupervised learning of video representations using lstms. In ICML, 2015.