【论文精读】SimCLR2
摘要
本文提出了一个半监督学习框架,包括三个步骤:无监督或自监督的预训练;有监督微调;使用未标记数据进行蒸馏。具体改进有:
- 发现在半监督学习(无监督预训练+有监督微调)中,对于较大的模型只需采用少量有标签数据就可实现良好的结果
- 证明了SimCLR中用于半监督学习的卷积层之后非线性变换(投影头)的重要性。更深的投影头能提高分类线性评估指标,也能提高从投影头的中间层进行微调时的半监督性能
- 对于特定目标,过大的模型容量不必要。故通过针对特定任务使用无标签数据蒸馏将大型模型转移到更小的网络中,可以进一步提高模型的预测性能
框架

提出的半监督学习框架归纳为三个主要步骤:预训练、微调和蒸馏(上图)。算法以任务无关或任务特定的方式利用无标记数据。
- 第一步使用与任务无关的未标记的数据,通过无监督预训练学习一般特征表示
- 第二步使用前一步的特征表示通过有监督学习微调来调整通用特征表示以适应特定任务
- 第三步使用特定于任务的未标记的数据,采用模型蒸馏方法,进一步提高预测性能并获得更小的模型。本文用微调后的教师网络的估算标签,在未标记数据上训练学生网络
对SimCLR的改进
无监督算法采用SimCLR方法,但做出如下改进:
- 对于编码器网络 f ( ⋅ ) f(\cdot) f(⋅),采用更大的一个152层ResNet模型及SKNet
- 加深了非线性转换网络 g ( ⋅ ) g(\cdot) g(⋅)层,在微调阶段,不完全丢弃 g ( ⋅ ) g(\cdot) g(⋅),而是从中间层进有监督训练
- 纳入了MoCo的记忆机制,但由于batchsize设置的很大,这部分改进带来的提升相对较小
该方法称为SimCLRv2。
Loss
SimCLR中一张图像经过数据增强 τ τ τ、编码器网络 f ( ⋅ ) f(\cdot) f(⋅)、非线性转换网络 g ( ⋅ ) g(\cdot) g(⋅)后会产生对比损失 z 2 k − 1 z_{2k−1} z2k−1和 z 2 k z_{2k} z2k,一对正例 i i i、 j j j(从同一图像增强)之间的对比损失如下:
l i , j N T − X e n t = − log exp ( s i m ( z i , z j ) / τ ) ∑ k = 1 2 N 1 [ k ≠ i ] exp ( s i m ( z i , z k ) / τ ) l^{NT-Xent}_{i,j}=-\log \frac {\exp(sim(z_i,z_j)/\tau)} {\sum^{2N}_{k=1}1_{[k \not = i]}\exp(sim(z_i,z_k)/\tau)} li,jNT−Xent=−log∑k=12N1[k=i]exp(sim(zi,zk)/τ)exp(sim(zi,zj)/τ)
其中 s i m ( ⋅ , ⋅ ) sim(·, ·) sim(⋅,⋅)是两个向量之间的余弦相似度, τ τ τ是temperature参数,通过教师学生网络得到对比学习来训练网络,在预训练,微调阶段时采用上述loss。
在知识蒸馏阶段,将微调网络用作教师来估算标签以训练学生网络。具体来说,在没有使用真实标签的情况下,最小化以下蒸馏损失:
L d i s t i l l = − ∑ x i ∈ D [ ∑ y P T ( y ∣ x i ; τ ) log P S ( y ∣ x i ; τ ) ] L^{distill}=-\sum_{x_i\in D}[\sum_yP^T(y|x_i;\tau)\log P^S(y|x_i;\tau)] Ldistill=−xi∈D∑[y∑PT(y∣xi;τ)logPS(y∣xi;τ)]
其中 P ( y ∣ x i ) = e x p ( f t a s k ( x i ) [ y ] / τ ) / ∑ y ′ e x p ( f t a s k ( x i ) [ y ′ ] / τ ) P(y|x_i)=exp(f^{task}(x_i)[y]/τ)/\sum_{y'}exp(f^{task}(x_i)[y']/τ) P(y∣xi)=exp(ftask(xi)[y]/τ)/∑y′exp(ftask(xi)[y′]/τ), τ τ τ是temperature参数。教师网络 P T ( y ∣ x i ) P^T(y|x_i) PT(y∣xi)在蒸馏过程中固定,用于训练学生网络 P S ( y ∣ x i ) P^S(y|x_i) PS(y∣xi)。
当标记样本的数量很大时,也可以使用加权组合将蒸馏损失与标记样本相结合训练,如下:
L = − ( 1 − α ) ∑ ( x i , y i ) ∈ D L [ log P S ( y i ∣ x i ) ] − α ∑ x i ∈ D [ ∑ y P T ( y ∣ x i ; τ ) log P S ( y ∣ x i ; τ ) ] L=-(1-\alpha)\sum_{(x_i,y_i)\in D^L}[\log P^S(y_i|x_i)]-\alpha \sum_{x_i \in D}[\sum_yP^T(y|x_i;\tau)\log P^S(y|x_i;\tau)] L=−(1−α)(xi,yi)∈DL∑[logPS(yi∣xi)]−αxi∈D∑[y∑PT(y∣xi;τ)logPS(y∣xi;τ)]
实验
实验配置
在ImageNet ILSVRC-2012数据集上评估了所提出的方法。数据集有128万张图像可用,但只随机抽样的1%或10%的图像与标签相关联,其余只采样图像。使用LARS优化器(动量为0.9)进行预训练、微调和蒸馏。
对于预训练,batchsize大小为4096,采样全局批归一化,epoch为800。学习率在前5%的epoch线性增加,达到最大值6.4,然后以余弦衰减方法衰减,使用了1e−4的权重衰减。在ResNet编码器上使用一个3层的MLP投影。内存缓冲区设置为64K,指数移动平均(EMA)衰减设置为0.999。使用与SimCLR相同的简单增强集,即随机裁剪,颜色失真和高斯模糊。
对于微调,默认情况下,从投影头的第一层对1%/10%的标记样本进行微调,用1%的标签数据进行60个epoch进行微调,用10%的标签进行30个epoch;但当存在100%的标签时,从投影头的输入进行微调。使用全局批量归一化,但删除了 权重衰减、学习率预热,学习率为标准ResNets的0.16,和更大的ResNets变体的0.064。批量大小设置为1024。
对于蒸馏,使用无标签的数据。考虑两种类型的蒸馏:自蒸馏,学生与教师具有相同的模型结构(不包括投影头);以及从大到小的蒸馏,其中学生是一个小得多的网络。对于自蒸馏,将 τ τ τ设置为0.1,对于从大到小的蒸馏,将 τ τ τ设置为1.0。使用相同的学习率调度、权重衰减、批量大小作为预训练,模型被训练了400个epoch。在微调和蒸馏期间,只应用随机裁剪和水平翻转训练图像。
对比实验

上图比较了不同模型大小和评估方法下的自监督学习和监督学习模型,包括微调和线性评估。 可以看到,增加编码器网络 f ( ⋅ ) f(\cdot) f(⋅)宽度和深度以及使用SK都可以提高性能。这些架构对标准监督学习的影响相对有限(最小模型和最大模型的差异为4%),但对于自监督模型,线性评估的精度差异可达8%,对1%的标记图像进行微调的精度差异可达17%。证明了自监督学习相对于监督学习的优势。
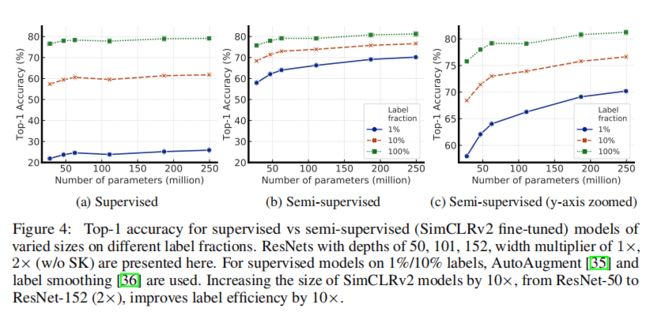
上图显示了不同模型大小在不同标签样本占比时的性能。结果表明,更大的模型对于监督和半监督学习都具有更好的学习能力,但半监督学习性能提升幅度更大。

上图显示了在不同标签样本占比下通过增加模型大小,监督学习和半监督学习(即SimCLRv2)都能从更大的模型中提升性能。
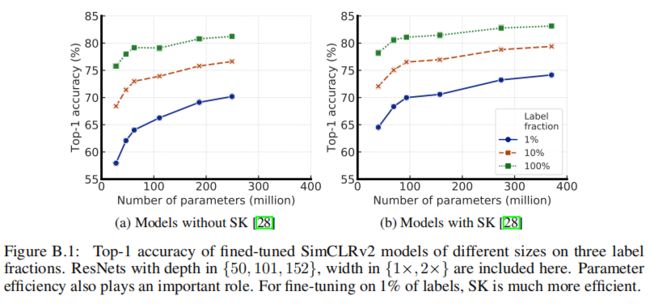
上图显示了不同尺寸的微调SimCLRv2模型的top-1精度。结果表明模型越大越好;使用SK,在相同的参数数量下可以获得更好的性能。

上图显示将最好的模型与之前最先进的半监督学习方法在ImageNet上进行比较。该方法大大改进了之前的结果,无论是小型的ResNet还是大型的ResNet变体。
消融实验
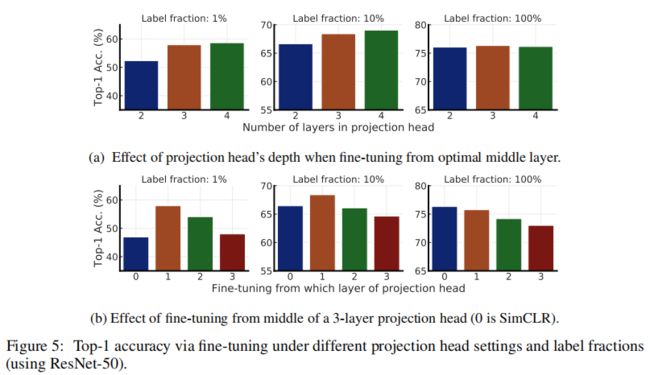
使用具有不同投影头层数(从2到4个全连接层)的SimCLRv2对ResNet-50的预训练,并检查从投影头的不同层进行微调时的性能。从上图观察到,从投影头的最优层(投影头的第一层)进行微调时,在预训练期间使用更深的投影头更好(图5a);在投影头第一层微调效果最优(图5b)。

上图显示2层和3层投影头的不同层微调的效果。结果证实,用少量标记样本在更深的投影头进行预训练和从中间层进行微调,可以提高半监督学习性能。模型尺寸越小,改进越大。

上图显示了在使用蒸馏损失进行训练时使用未标记样本的重要性。当标签样本占比很小时,单独使用蒸馏损失几乎与平衡蒸馏损失效果一样好。
蒸馏未标记的样本以两种方式改进微调模型。
- 一般蒸馏:当学生模型的结构小于教师模型时,它通过将特定任务的知识迁移到学生模型中来提高模型效率
- 自蒸馏:学生模型与教师模型具有相同的结构(不包括ResNet编码器后的投影头),可以提高半监督学习性能。为了使较小的ResNets获得最佳性能,在将大模型蒸馏为较小的模型之前,对其进行自我蒸馏。
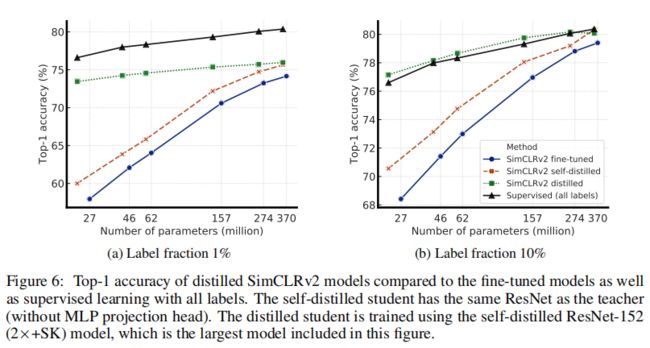
上图显示了不同蒸馏方法组合的线性评估指标,分别为微调模型、自蒸馏模型、基于自蒸馏教师网络的蒸馏模型、监督模型。可以看到蒸馏模型效果最佳。

上图显示了组合蒸馏损失中蒸馏权重 α α α和 τ τ τ的影响。可以看到没有实际标签的蒸馏(即 α α α为1.0)与有实际标签的蒸馏效果相同。此外, τ τ τ为0.1和1.0的效果相似,但2.0的效果明显较差。对于本文的蒸馏实验,当教师模型是微调模型时,默认 τ τ τ为0.1,否则 τ τ τ为1.0。
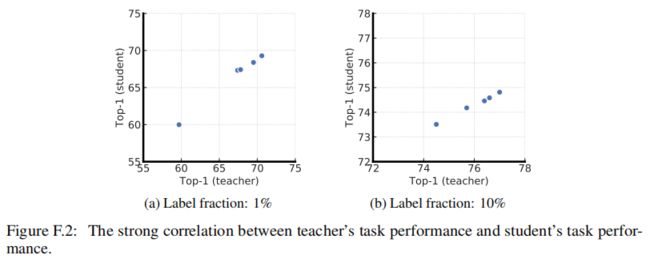
进一步研究了使用不同投影头进行微调的教师网络的蒸馏性能。更具体地说,预训练两个ResNet-50 (2 × +SK)模型,分别具有两层或三层投影头,并从中间层进行微调。这给出5个不同的教师网络,对应不同的投影头设置。上图所示,蒸馏性能与微调teacher的top-1精度密切相关。这表明,更好的微调模型(以其top-1精度衡量),无论其投影头设置如何,都是更好的老师使用未标记数据将特定知识传递给学生。
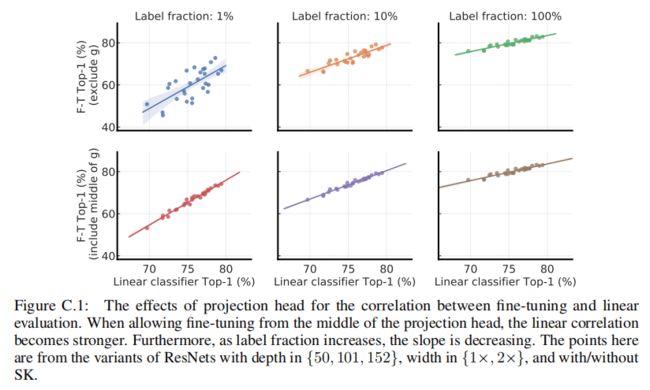
上图研究了微调和线性评估的相关性,显示了两种不同微调策略下的相关性:
- 来自投影头输入的微调(行1)
- 来自投影头中间层的微调(行2)
观察到总体上存在线性相关性。当从投影头的中间层进行微调时,观察到更强的线性相关性。此外,注意到随着用于微调的标记图像数量的增加,相关性的斜率变得更小。
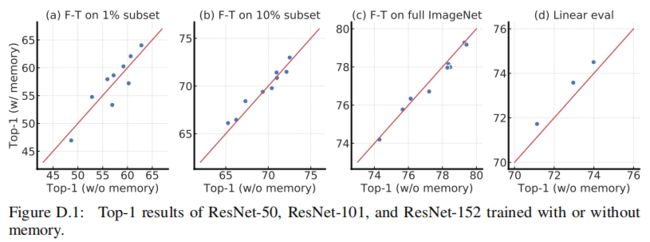
上图显示了有或没有memory(MoCo)训练的SimCLRv2模型的top-1比较。memory在线性评估在微调方面提供了适度的优势,性能提升约1%。大致认为,memory只能提供边际改进的原因是使用了很大的batchsize(即4096)。
reference
Chen, T. , Kornblith, S. , Swersky, K. , Norouzi, M. , & Hinton, G. . (2020). Big Self-Supervised Models are Strong Semi-Supervised Learners. Neural Information Processing Systems.