【CV论文精读】【BEV感知】BEVDet: High-Performance Multi-Camera 3D Object Detection in Bird-Eye-View
【CV论文精读】【BEV感知】BEVDet: High-Performance Multi-Camera 3D Object Detection in Bird-Eye-View
BEVDet:鸟瞰下的高性能多摄像机三维目标检测
0.论文摘要
自动驾驶感知周围环境进行决策,这是视觉感知中最复杂的场景之一。范式创新在解决2D目标检测任务中的成功激励我们寻求一种优雅、可行和可扩展的范式,从根本上推动该领域的性能边界。为此,我们在本文中贡献了BEVDet范式。BEVDet在鸟瞰视图(BEV)中执行3D目标检测,其中大多数目标值被定义,并且可以方便地执行路线规划。我们只是重用现有的模块来构建它的框架,但通过构建一个独占的数据扩充策略和升级非最大抑制策略来实质性地发展它的性能。在实验中,BEVDet在准确性和时间效率之间提供了一个很好的折衷。作为一个快速版本,BEVDet-Tiny在nuScenes val集上获得了31.2%的地图和39.2%的NDS。它与FCOS3D相当,但只需要11%的215.3 GFLOPs计算预算,运行速度为15.6 FPS,快9.2倍。另一个被称为BEVDet-Base的高精度版本获得了39.3%的mAP和47.2%的NDS,大大超过了所有公布的结果。在相当的推理速度下,它以+9.8%的mAP和+10.0%的NDS的大幅度超过了FCOS3D。源代码是公开的,可供进一步研究1。
代码
1.研究背景
2D视觉感知在过去几年中经历了快速发展,并出现了一些杰出的范例,如Mask R-CNN[13],它具有高性能、可扩展性[2,4]和多任务兼容性。然而,对于要求准确性和时间效率的基于视觉的自动驾驶场景,像3D目标检测和地图恢复(即鸟瞰(BEV)语义分割)这样的主要任务仍然在最新的基准中由不同的范例进行。例如,在nuScenes[1]基准,基于图像视图的方法,如FCOS3D[49]和PGD[50]在多摄像机3D目标检测跟踪中具有领先的性能,而BEV语义分割跟踪由基于BEV的方法主导,如PON[39],Lift-Splat-Shoot[33]和VPN[31]。在自动驾驶中,哪个视图空间对感知更合理,我们能在一个统一的框架内处理这些任务吗?针对这些问题,本文提出了BEVDet。通过BEVDet,我们探索了在BEV中检测3D目标的优势,期望与最新的基于图像视图的方法相比具有更好的性能,并与BEV语义分割保持一致。通过这种方式,我们可以进一步验证多任务学习的可行性,这对于时间高效的推理是有意义的。
如图1所示,所提出的BEVDet与最新的BEV语义分割算法[33,39,54]共享类似的框架。它模块化设计有用于在图像视图中编码特征的图像视图编码器、用于将特征从图像视图转换为BEV的视图Transformer model、用于在BEV透视图中进一步编码特征的BEV编码器,以及用于在BEV空间中执行3D目标检测的特定任务头。受益于这种模块化设计,我们可以重用大量在其他领域被证明有效的现有工作,并且仍然期望升级这种特定于3D目标检测任务的范式还有很长的路要走。
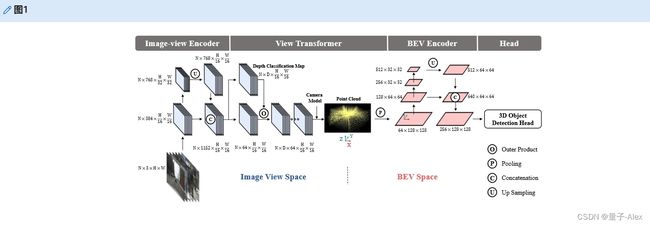
图1。提出的BEVDet范式的框架。BEVDet采用模块化设计,由四个模块组成:图像视图编码器,包括主干和颈部,首先用于图像特征提取。视图Transformer model将该功能从图像视图转换为BEV。BEV编码器进一步编码BEV特征。最后,基于BVE特征构建特定于任务的头,并预测3D目标的目标值。我们以BEVDet-Tiny为例来说明不同模块的通道。
尽管构建BEVDet的框架很简单,但构建其健壮的性能却很重要。在验证BEVDet的可行性时,为了达到合理的性能,BEVDet的数据处理策略和参数设置接近于基于图像视图的三维目标检测器类似FCOS3D[49]和PGD[50]。意外地,在训练过程中观察到严重的过度拟合问题。一些线索显示,魔鬼在BEV空间中BEVDet的过度拟合能力中。首先,过度拟合鼓励我们在图像视图空间中应用复杂的数据增强策略,如Lift-Splat-Shoot[33]以获得正则化效果。然而,只有在BEV编码器不存在的情况下,这种修改才具有积极的效果。否则甚至会降低性能。另一方面,图像视图编码器的批量大小是N(即,像nuScenes[1]中的6个摄像机的数量)乘以子模块。训练数据不足也是BEV空间学习过度拟合的部分原因。此外,我们观察到视图Transformer model以逐像素的方式连接图像视图空间和BEV空间,这从数据增强的角度将它们解耦。这使得图像视图中的数据扩充对子模块(即BEV编码器和3D目标检测头)没有正则化效果。因此,作为补充,在BEV空间中进行额外的数据扩充操作,如翻转、缩放和旋转,以提高模型在这些方面的鲁棒性。这在防止BEVDet过度拟合方面非常有效。
此外,我们改进了经典的非最大抑制(NMS)策略,以提高其在三维目标检测场景中的适应性。通过移除顺序执行的运算符,推理过程被进一步加速。通过这些修改,BEVDet在现有范例中提供了准确性和推理延迟之间的杰出权衡。在nuScenes[1]val set上,高速版本BEVDet-Tiny以704 × 256的图像尺寸实现了卓越的精度(即31.2%的mAP和39.2%的NDS),仅为竞争对手的1/8(即FCOS3D[49]中图像尺寸为1600 × 900的29.5%的mAP和37.2%的NDS)。缩小图像尺寸可将计算预算减少89%,并提供9.2倍的显著加速(即BEVDet具有215.3 GFLOPs和15.6 FPS,而FCOS3D具有2,008.2 GFLOPs和1.7 FPS)。通过构建另一个被称为BEVDet-Base的高精度配置,我们报告了39.3%mAP和47.2%NDS的新记录。此外,与现有的范例相比,在BEV空间中显式编码特征使BEVDet在感知目标的平移、尺度、方向和速度方面具有天赋。在消融研究中可以发现BEVDet的更多特征。
2.相关工作
2.1 基于视觉的二维感知
2.1.1 图像分类
基于视觉的2D感知的深度学习的复兴可以追溯到用于图像分类的AlexNet[19]。从那时起,研究界通过提出残差[14]、高分辨率[43]、基于注意力[7]和许多其他类型的结构[8,15,16,35,45],不断推动图像编码器的性能边界。同时,强大的图像编码能力也提高了其他复杂任务的性能,如目标检测[23,38],语义分割[18,52],人类姿态估计[17,43],等等。作为一个简单的任务,图像分类的求解模式由Softmax[19]及其衍生物主导。由网络结构决定的图像编码器的容量在这个问题中起着至关重要的作用,并且是研究界主要关注的问题。
2.1.2 目标检测
常见的目标检测需要类别标签和所有预定义目标的定位边界框,是一项更复杂的任务,其中范例也起着至关重要的作用。两阶段法Faster R-CNN[38],一阶段法RetinaNet[23],以及它们的衍生物[2,4,13,46,57]是该领域的主要方法[24,41]。受Mask R-CNN[13]的启发,多任务学习已经成为研究和工业社区中一种有吸引力的范式,因为它通过共享主干和通过联合训练促进任务来节省计算资源的巨大潜力。范式创新在这一领域的巨大影响激励我们在自动驾驶场景中利用卓越的范式来获得更好的感知性能,在自动驾驶场景中,任务甚至更加复杂,多任务学习相当有吸引力。
2.2 BEV中的语义分割
自动驾驶中的主要感知任务之一是向量恢复其周围环境的地图。这可以通过在BEV中对可行驶区域、停车场、车道分隔线、停车线等目标进行语义分割来实现。在基准测试[1]中具有领先性能的基于视觉的方法总是具有相似的框架[31,33,39,54]。在该框架中,有四个主要组件:用于在图像视图中编码特征的图像视图编码器,用于将特征从图像视图转换到BEV的视图Transformer model,用于在BEV中进一步编码特征的BEV编码器,以及用于逐像素分类的头。这种管道在BEV语义分割中的成功鼓励我们将其扩展到3D目标检测任务,期望BEV中的特征能够很好地捕捉3D目标的一些目标,如比例、方向和速度。此外,我们还在寻求一种可扩展的范式,在这种范式中,多任务学习可以实现高准确性和高效率。
2.3 基于视觉的3D目标检测
三维物体检测是自动驾驶中另一个关键的感知任务。在过去的几年里,KITTI[9]基准推动了单目3D物体检测的快速发展[20,27,29,36,47,48,58,61,64]。然而,有限的数据和单一的视图使其无法开发更复杂的任务。最近,一些大规模基准[1,44]发布了更多数据和多视图,为多摄像机3D目标检测的范式开发提供了新的视角。基于这些基准,已经开发了一些具有竞争性性能的多摄像机3D目标检测范例。例如,受到FCOS[46]在2D检测的成功的启发,FCOS3D[49]将3D目标检测问题视为2D目标检测问题,仅在图像视图中进行感知。由于目标属性与图像外观具有很强的空间相关性,该算法可以很好地预测这一点,但在感知目标的平移、速度和方向方面相对较差。继DETR[3]之后,DETR3D[51]提出检测注意力模式中的3D目标,其精度与FCOS3D相似。虽然DETR3D只需要一半的计算预算,但复杂的计算流水线会将其推理速度减慢到与FCOS3D相同的水平。PGD[50]通过搜索和解决突出的缺点(即目标深度的预测),进一步发展了FCOS3D范式。这在基线上提供了显著的准确性改进,但代价是更多的计算预算和额外的推理延迟。现有的范例在准确性和时间效率之间的权衡有限。这促使我们寻求和开发新的,以大幅推动这一领域的性能边界。
有一些先驱[5,21,36],他们利用了BEV中的3D目标检测任务。其中,同样受到Lift-Splat-Shoot[33]的启发,[36]是和我们最相似的一个。他们将Lift-Splat-Shoot范式应用于单目3D物体检测,并通过参考激光雷达对深度预测进行监督,使其在KITTI[9]基准测试中具有竞争力。在DD3D[32]的并行工作中可以找到一个接近的想法。不同的是,在不依赖激光雷达的情况下,我们通过基于视图Transformer model的解耦效应构建独家数据增强策略来升级这一范式。这是一种更可行的方法,并在使BEVDet范式在现有方法中具有竞争力方面发挥了重要作用。
3.方法
3.1 网络结构
如图1所示,具有模块化设计的BEVDet由四种模块组成:图像视图编码器、视图Transformer model、BEV编码器和任务专用头。我们通过构建几种不同结构的衍生物来研究BEVDet的可行性见表1。


表1。BEVDet的组成部分。“-number”表示该模块中的通道数。Lift-Splat-Shoot-64-0.4 × 0.4表示Transformer model在[33]中提出的观点。输出功能的通道数为64,分辨率为0.4米。
3.1.1 图像视图编码器
图像视图编码器将输入图像编码成高级特征。为了利用多分辨率特征的强大功能,imageview编码器包括用于高级特征提取的主干和用于多分辨率特征融合的颈部。默认情况下,我们使用经典的ResNet[14]和最新的基于注意力的SwinTransformer[26]作为原型研究的主干。替换包括DenseNet[16]、HRNet[43]等。关于颈部模块,我们使用经典的FPN[22]和在[33]中提出的颈部结构,其在下文中被命名为FPN-LSS。FPN-LSS只是将1/32输入分辨率的特征上采样到1/16输入分辨率,并将其与主干生成的特征连接起来。更复杂的颈部模块尚未被开发,如PAFPN[25]、NAS-FPN[10]等。
3.1.2 视图Transformer model
视图Transformer model将特征从图像视图转换为BEV。我们应用Transformer model在[33]中提出的观点来构建BEVDet原型。所采用的视图Transformer model以图像——视图特征为输入,通过分类方式密集预测深度。然后,使用分类分数和导出的图像视图特征来绘制预定义的点云。最后,可以通过沿着垂直方向(即,如图1所示的Z坐标轴)应用池化操作来生成BEV特征。在实践中,我们将深度预测的默认范围扩展到[1,60]米,间隔为1.25 × r,其中r表示输出要素的分辨率。
3.1.3 BEV Encoder
BEV编码器进一步对BEV空间中的特征进行编码。虽然这种结构类似于具有主干和颈部的图像视图编码器,但它可以高精度地感知一些关键线索,如比例、方向和速度,因为它们是在BEV空间中定义的。我们遵循[33]利用具有经典残差块的ResNet[14]来构建主干,并通过应用FPN-LSS来组合具有不同分辨率的特征。
3.1.4 Head
特定于任务的头是基于BEV特性构建的。在常识[1]中,自动驾驶仪中的3D目标检测针对可移动目标的位置、比例、方向和速度,如行人、车辆、障碍物等。在没有任何修改的情况下,我们直接采用CenterPoint[56]第一阶段的3D目标检测头进行原型验证,并与PointPillar[21]和VoxelNet[60]等基于激光雷达的管道进行公平比较。尚未应用CenterPoint的第二个细化阶段。
3.2 定制数据扩充策略
视图Transformer model[33]以像素方式将特征从图像视图转换为BEV。具体来说,给定一个像素具有特定深度d的像平面 p i m a g e = [ x i , y i , 1 ] T p_{image} = [x_i, y_i, 1]^T pimage=[xi,yi,1]T,3D空间中的对应坐标为:

其中I是3 × 3相机固有矩阵。具有翻转、裁剪和旋转等操作的常见数据扩充策略可以公式化为3 × 3变换矩阵A[17]。当在输入图像上应用数据增强策略时(即, p i m a g e ′ = A p i m a g e p^′_{image} = Ap_{image} pimage′=Apimage),应在视图变换[33]中应用逆变换 A − 1 A^{−1} A−1以保持特征和BEV空间中的目标之间的空间一致性:
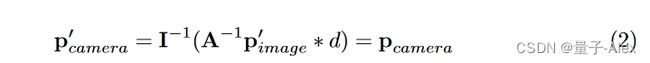
关于BEV空间中的学习,数据的数量少于图像视图空间中的数据,因为每个样本包含多个相机图像(例如,nuScenses基准测试中的每个样本包含6个图像[1])。因此,BEV空间中的学习容易陷入过度拟合。由于视图Transformer model在扩充视角中隔离了两个视图空间,我们构造了另一种针对BEV空间中正则化效应的扩充策略。遵循最新的基于激光雷达的方法[34,55,56,63],采用2D空间中常见的数据增强操作,包括翻转、缩放和旋转。在实践中,操作是对视图Transformer model的输出特征和3D目标检测目标进行的,以保持它们的空间一致性。值得注意的是,这种数据扩充策略是建立在视图Transformer model可以将imageview编码器与后续模块解耦的前提之上的。这是BEVDet的一个特殊特征,在其他方法中可能无效[49–51]。
3.3 Scale-NMS
不同类别在BEV空间中的空间分布与在图像——视图空间中的空间分布有很大不同。在图像——视图空间中,由于相机的透视成像机制,所有类别共享相似的空间分布。因此,具有固定阈值的经典非最大抑制(NMS)[40]策略可以很好地调整所有类别的预测结果,以符合先验(例如,在2D目标检测中,两个实例之间的边界框交集(IOU)指示器总是低于特定阈值0.5[11,23,37,38,46])。然而,在BEV领域就不一样了。在BEV空间中,各种类的占用区域是本质上不同,实例之间的重叠应该接近于零。因此,IOU在预测结果之间的分布因类别而异。例如,如图2所示,像行人和交通锥这样的物体在地平面中占据很小的区域,该区域总是小于算法的输出分辨率(例如,中心点0.8米[56])。常见的目标检测范例[23,38,46,56]冗余地生成预测。每个目标的占用面积小,可能会使冗余结果与真正结果没有交集。这使依赖IOU来访问真阳性和假阳性之间的空间关系的经典NM失活。
为了克服上述问题,本文提出了Scale-NMS。Scale-NMS在执行经典NMS算法之前,根据类别缩放每个目标的大小。以这种方式,IOU在真阳性和冗余结果之间的分布被调制以与经典NMS匹配。如图2的第二行所示,在预测小目标时,Scale-NMS通过放大目标大小来建立结果之间的空间关系,这使得经典NMS能够根据IOU指示符丢弃冗余的结果。在实践中,我们将标度NMS应用于除屏障之外的所有类别,因为屏障的大小各不相同。比例因子是特定于类别的。它们是通过对验证集进行超参数搜索而生成的。

图二。经典NMS和建议的 ScaleNMS之间的比较说明。
为了克服上述问题,本文提出了Scale-NMS。Scale-NMS在执行经典NMS算法之前,根据类别缩放每个目标的大小。以这种方式,IOU在真阳性和冗余结果之间的分布被调制以与经典NMS匹配。如图2的第二行所示,在预测小目标时,Scale-NMS通过放大目标大小来建立结果之间的空间关系,这使得经典NMS能够根据IOU指示符丢弃冗余的结果。在实践中,我们将标度NMS应用于除屏障之外的所有类别,因为屏障的大小各不相同。比例因子是特定于类别的。它们是通过对验证集进行超参数搜索而生成的。
4.算法
4.1 实验环境
4.1.1 数据集
我们在大规模基准nuScenes上进行了全面的实验[1]。nuScenes基准测试包括来自6台摄像机的1000个场景和图像。它是基于视觉的3D目标检测[32, 49–51]和BEV语义分割[31, 33, 39, 54]的最新流行基准。场景被正式分成700/150/150个场景进行训练/验证/测试。有高达1.4米的注释三维边界框10类:汽车,卡车,公共汽车,拖车,工程车辆,行人,摩托车,自行车,障碍,和交通圆锥体。在中心点[56]之后,我们定义地平面中51.2米内的感兴趣区域(ROI),默认分辨率(即中心点[56]中体素的大小)为0.8米。
4.1.2 评估指标
对于3D目标检测,我们报告官方预定义的指标:平均平均精度(mAP)、平均平移误差(ATE)、平均比例误差(ASE)、平均方向误差(AOE)、平均速度误差(AVE)、平均属性误差(AAE)和NuScenes检测得分(NDS)。该映射类似于2D目标检测[24]中用于测量精度和召回率的映射,但是基于地平面上2D中心距离的匹配而不是并集上的交集(IOU)[1]来定义。NDS是综合判断检测能力的其他指标的综合。其余指标用于计算正面结果在相应方面的精度(例如,平移、比例、方向、速度和属性)。
4.1.3 训练参数
使用AdamW[28]优化器训练模型,其中梯度clip以学习率 2 e − 4 2e^{-4} 2e−4利用,在8个NVIDIA GeForce RTX 3090 GPUs上的总批量大小为64。对于基于ResNet[14]的图像视图编码器,我们应用步进学习速率策略,该策略将epoch 17和20的学习速率降低0.1倍。对于基于SwinTransformer[26]的图像视图编码器,我们应用了循环策略[53],该策略在前40%的时间表中将学习速率从 2 e − 4 2e^{-4} 2e−4线性增加到 1 e − 3 1e^{-3} 1e−3,并在剩余时期将学习速率从 1 e − 3 1e^{-3} 1e−3线性降低到0。默认情况下,总计划在20个轮次内终止。
4.1.4 数据处理
情况下,在训练过程中,分辨率为1600 × 900的源图像[1]通过随机翻转、范围为 s ∈ [ W i n / 1600 − 0.06 , W i n / 1600 + 0.11 ] s ∈ [W_{in}/1600 − 0.06, W_{in}/1600 + 0.11] s∈[Win/1600−0.06,Win/1600+0.11]的随机缩放、范围为 r ∈ [ − 5.4 ◦ , 5.4 ◦ ] r ∈ [−5.4◦, 5.4◦] r∈[−5.4◦,5.4◦]的随机旋转以及最终裁剪到Win × Hin的大小来处理。裁剪在水平方向上随机进行,但在垂直方向上固定 ( i . e . , ( y 1 , y 2 ) = ( m a x ( 0 , s ∗ 900 − H i n ) , y 1 + H i n ) (i.e., (y_1, y_2) = (max(0, s ∗ 900 − H_{in}), y_1 + H_{in}) (i.e.,(y1,y2)=(max(0,s∗900−Hin),y1+Hin),其中y1和y2是目标区域的上限和下限。)在BEV空间中,输入特征和3D目标检测目标通过随机翻转、范围为 [ 22.5 ° 、 22.5 ° ] [22.5°、22.5°] [22.5°、22.5°]的随机旋转和范围为【0.95、1.05】的随机缩放来增强。在中心点[56]之后,所有模型都用CBGS[62]进行训练。在测试时间,输入图像按因子 s = W i n / 1600 + 0.04 s = W_{in}/1600 + 0.04 s=Win/1600+0.04缩放,并裁剪为 W i n × H i n W_{in} × H_{in} Win×Hin分辨率,区域定义为 ( x 1 , x 2 , y 1 , y 2 ) = ( 0.5 ∗ ( s ∗ 1600 − W i n ) , x 1 + W i n , s ∗ 900 − H i n , y 1 + H i n ) (x_1, x_2, y_1, y_2) = (0.5 ∗ (s ∗ 1600 − W_{in}), x_1 + W_{in}, s ∗ 900 − H_{in}, y_1 + H_{in}) (x1,x2,y1,y2)=(0.5∗(s∗1600−Win),x1+Win,s∗900−Hin,y1+Hin)。
4.1.5 推理速度
我们基于MMDetection3D[6]进行所有实验。所有的推理速度和计算预算都是在没有数据扩充的情况下测试的。对于像FCOS3D[49]和PGD[50]这样的单镜头范例,推理速度除以6倍(即单个样本中的图像数量[1]),因为它们将每个图像作为独立的样本。值得注意的是,分割操作可能不是最佳方法,因为批量处理可以加快单目范式的推断。我们通过用另一个等价的实现替换视图转换中的累加和运算来加速所提出的BEVDet范例。详情可在消融研究部分找到。