初识eBPF
eBPF 是一项革命性的技术,它能在操作系统内核中运行沙箱程序。被用于安全并有效地扩展内核的能力而无需修改内核代码或者加载内核模块。
从古至今,由于内核有监视和控制整个系统的特权,操作系统一直都是实现可观察性、安全性和网络功能的理想场所。同时,操作系统内核也很难进化,因为它的核心角色以及对稳定和安全的高度要求。因此,操作系统级别的创新相比操作系统之外实现的功能较少。

eBPF 从根本上改变了这个定律。通过允许在操作系统内运行沙箱程序,应用开发者能够运行 eBPF 程序在运行时为操作系统增加额外的功能。然后操作系统保证安全和执行效率,就像借助即时编译器(JIT compiler)和验证引擎在本地编译那样。这引发了一波基于 eBPF 的项目,涵盖了一系列广泛的使用案例,包括下一代网络、可观察性和安全功能。
现在,eBPF 被广泛用于:在现代数据中心和云原生环境中提供高性能网络和负载均衡;以低开销提取细粒度的安全可观察性数据;帮助应用开发者追踪应用程序;洞悉性能问题和加强容器运行时的安全性等等。一切皆有可能,而 eBPF 释放的创新才刚刚开始。
介绍
如果你想要深入了解 eBPF,查看 eBPF & XDP Reference Guide。无论你是一个想要构建 eBPF 程序的开发者还是对使用 eBPF 技术的解决方案感兴趣,都有必要了解一下基本概念和架构。
钩子(Hook)
eBPF 程序是事件驱动的,当内核或应用程序通过某个锚点时就会运行。预定义的钩子包括系统调用、函数进入/退出、内核追踪点、网络事件等等。
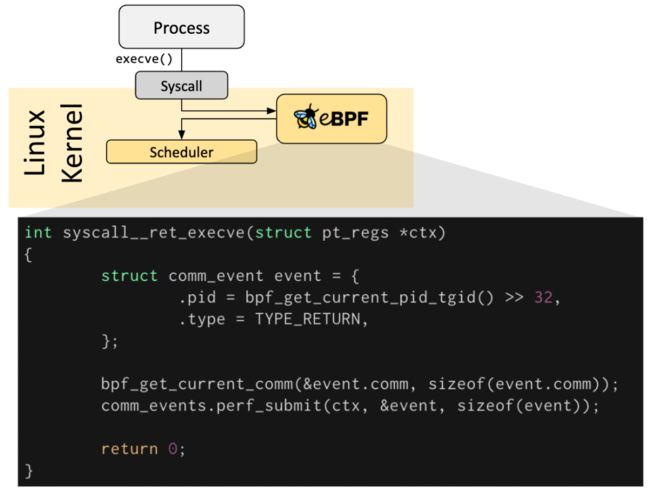
如果预定义的钩子不存在,可以创建一个内核探针(kprobe)或用户探针(uprobe)来将 eBPF 程序附加至内核或用户应用程序的任何地方。

怎么写 eBPF 程序?
在很多情况下,并不直接使用 eBPF,而是通过 Cilium、bcc 或 bpftrace 等项目间接使用,它们在 eBPF 之上提供了一层抽象,无需直接编写程序而是提供了一些能力,由 eBPF 来实现。

要是没有上层抽象的话,就要直接编写程序了。Linux 内核期望 ePBF 程序以字节码的形式加载。直接编写字节码不太可能,实际开发中更常见的是使用 LLVM 等编译器套件将伪 C 代码编译成 eBPF 字节码。
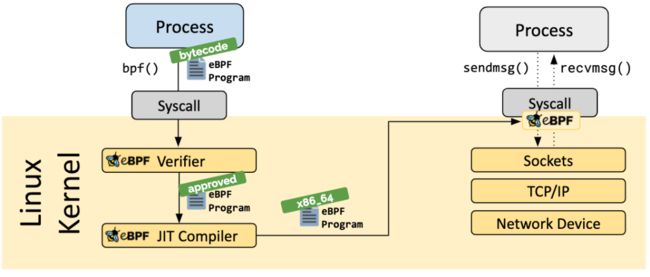
Loader & Verification 架构
当所需的钩子被确定后,可以使用 bpf 系统调用 将 eBPF 程序加载至 Linux 内核。通常使用 eBPF 库完成,下节将介绍可用的开发工具链。
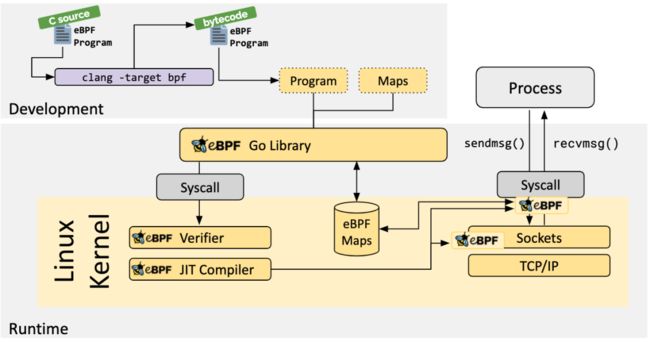
当程序被加载至 Linux 内核时,在被连接到所请求的钩子之前要经过两个步骤:
验证
验证步骤确保 eBPF 程序可以安全运行,将检查程序是否符合以下条件:
-
加载 eBPF 程序的进程的权限。除非启用非特权 eBPF,否则只有特权(privileged)进程可以加载 eBPF 程序。
-
程序不会崩溃或损害系统。
-
程序是会运行完成的(不会处于循环状态,这样会耽误进一步处理)。
JIT 编译
JIT(Just-In-Time)编译步骤将程序的通用字节码翻译成机器特定的指令集来优化程序的执行速度。这使得 eBPF 程序可以像本地编译的内核代码或作为内核模块加载的代码一样高效运行。
Maps
共享收集的信息和存储状态的能力对 eBPF 程序来说至关重要。为此,eBPF 程序可以利用 eBPF maps 的概念来存储和检索数据。eBPF maps 可被 eBPF 程序以及用户空间的应用程序通过系统调用来访问。

map 类型支持多种数据结构:
-
哈希表、数组
-
LRU(Least Recently Used)
-
环形缓冲区(Ring Buffer)
-
栈
-
LPM(Longest Prefix match)
辅助调用
eBPF 程序不能随意调用内核函数。这样做的话需要使 eBPF 程序与特定的内核版本绑定,并使程序的兼容性变得复杂。相反,eBPF 程序调用辅助函数,这是内核提供的一个稳定的 API。

辅助调用的集合还在持续扩充中,以下是可用的辅助调用:
-
生成随机数
-
获取当前时间和日期
-
eBPF map 访问
-
获取进程/cgroup 上下文
-
操控网络包和转发逻辑
尾部调用和函数调用
eBPF 程序可与尾部 & 函数调用的概念相结合。函数调用允许在 eBPF 程序中定义和调用函数。尾部调用能够调用和执行另一个 eBPF 程序并替换执行上下文,类似于常规进程进行 execve() 系统调用。
eBPF 安全性
能力越大责任越大。
eBPF 是一项非常强大的技术,目前运行在许多关键软件基础设施组件的核心。在 eBPF 的开发中,当 eBPF 被考虑纳入 Linux 内核时,eBPF 的安全性是最关键的方面。eBPF 的安全性通过几个层面得到保证:
所需的权限
除非非特权的 eBPF 被启用,否则所有打算将 eBPF 加载到 Linux 内核的进程必须以特权模式(root 权限)运行或需要 CAP_BPF 能力。这就意味着不受信任的程序无法加载 eBPF 程序。
如果启用了非特权 eBPF,非特权进程可以加载特定的 eBPF 程序,但功能被阉割,对内核的访问也受限制。
验证器
如果一个进程被允许加载 eBPF 程序,所有程序仍会通过 eBPF 验证器。eBPF 验证器确保程序本身的安全性。例如:
-
eBPF 程序会被验证它们总是可以执行完成,永不被阻塞或死循环。只有当验证器能够确保循环包含了退出条件并保证为真时,程序才会被接受。
-
程序不得使用任何未初始化的变量或越界访问内存。
-
程序不能太大,不可能加载任意大的 eBPF 程序。
-
程序的复杂度必须有限。验证器将评估所有可能的执行路径,并且必须能够在有限时间内完成分析。
加固
在验证成功后,eBPF 程序会根据是从特权还是非特权进程加载的来运行一个“加固进程”:
-
程序执行保护:持有 eBPF 程序的内核内存被保护且只读。出于任何原因,不论是内核 bug 还是恶意操作,如果 eBPF 程序被试图修改,内核将崩溃而不是允许它继续执行被破坏/篡改的程序。
-
针对 Spectre 的缓解措施:CPU 可能会预测错分支,并留下可观察的副作用,这些副作用可以通过旁路被提取出来。举几个例子:eBPF 程序屏蔽了内存访问来将瞬时指令下的访问重定向到受控区域,验证器也会遵循只有在投机执行下才能访问的程序执行路径,JIT 编译器在尾调用不能转换为直接调用的情况下发出 Retpolines。
-
常量盲化:代码中的所有常量都被屏蔽以防止 JIT 喷涂攻击(JIT spraying)。这可以防止攻击者将可执行代码作为常量注入,存在另一个内核 bug 的情况下,会允许攻击者跳入 eBPF 程序的内存段执行代码。
抽象的运行时上下文
eBPF 程序不能随意直接访问内核内存,要想访问程序上下文之外的数据和数据结果必须通过 eBPF 辅助工具(eBPF helper)来完成,如此保证了数据访问的一致性并限制了 eBPF 程序的访问权限。举个栗子,如果确保安全的情况下,一个正在运行的 eBPF 程序就被允许修改某些数据,但不能随机修改内核中的数据。
开发工具链
开发者可以根据不同的需求选择合适的工具来开发和管理 eBPF 项目:
bcc
BCC 是一个使用户能够编写嵌入 eBPF 程序的 Python 脚本的框架,主要用于追踪和剖析应用程序和系统,利用 eBPF 程序来在用户空间收集统计数据或生成事件,并以对人类友好的形式展示。运行 Python 程序会生成 eBPF 字节码并将其加载进内核。

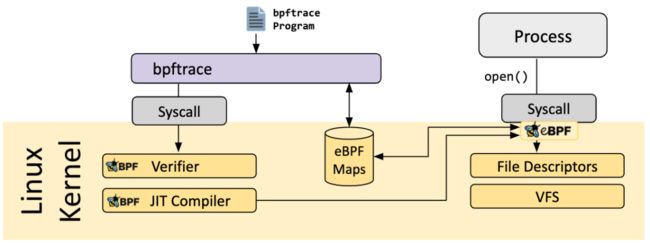
bpftrace
bpftrace 是一种 Linux eBPF 的高级追踪语言,在 4.x 版本的内核中可用。bpftrace 使用 LLVM 作为后端来将脚本编译为 eBPF 字节码,利用 BCC 和 Linux eBPF 子系统以及已有的 Linux 追踪功能进行交互:内核动态追踪(kprobes)、用户级动态追踪(uprobes)和追踪点(tracepoint)。bpftrace 语言的灵感来自于 awk、C 和 Dtrace 还有 SystemTap 这样的老一辈追踪器。
eBPF Go 库
gobpf 是一个通用的 eBPF Go 库,将获取 eBPF 字节码的过程和加载/管理程序解耦。eBPF 程序通常由高级编程语言编写,然后使用 clang/LLVM 编译器来编译成字节码。
libbpf C/C++ 库
libbpf 是一个基于 C/C++ 的通用 eBPF 库,帮助将由 clang/LLVM 编译器生成的 eBPF 对象文件和加载至内核解耦,提供易用的 API 来抽象与 BPF 系统调用的交互。
参考文献
https://www.qinglite.cn/doc/69556477626357aa7