1.逆向基础
文章目录
-
- 一、前言
- 二、什么是逆向?
- 三、软件逆向
- 四、逆向分析技术
- 五、文本字符
- 六、Windows系统
-
- 1.Win API
- 2.WOW64
- 3.Windows消息机制
- 4.虚拟内存
一、前言
原文以及后续文章可点击查看:逆向基础
逆向真的是一个很宏大的话题,而且大多数都是相当复杂且繁琐的,我目前对其了解的其实也并不深。
但既然C/C++都学了,不学一下逆向,又总会有点不得劲的感觉。
所以本系列就想尝试一下,看能不能写好逆向这一领域的相关东西。
不过由于我目前对逆向了解的真的不够多,所以本系列教程的第一版,大部分内容都会直接采用**《加密与解密》**这本书的结构与知识点分布进行讲解。
当然,我也不可能直接复制粘贴。
因为这书说实话,其实也有点年代感了,很多东西现在看来并不是很适用,并且新手估计也很难理解书中的专业术语。
二、什么是逆向?
逆向是一个非常宏大的话题,千万不要将眼界放的太过于狭隘了。
比如其它国家的高科技飞机,我们如果意外缴获了,但在不知道其制造工艺的情况下,正常来说也是无法复刻的。
而通过仔细分析缴获的这个飞机上的材料、结构,推测出其可能的制造方式,从而达到全部、或者部分复刻的目的,这也叫逆向。
这种通过成品,逆向推测出其原本技术的手段,一般就被称为逆向工程。
比如一个最直观的例子,估计大家都用过很多破解软件,那这些软件是怎么破解的呢?
实际上依赖的也是逆向工程。
但就我目前的认知来看,如果你想要逆向一个东西,那么你至少得熟悉它是以什么样的流程开发出来的,只有这样,逆向起来才会事半功倍。
同样举个例子,如果一个软件是采用vc++开发的,那么最好逆向方式就是查win api。
可如果一个软件是用JavaScript开发的,比如使用了当前很火的Electron框架,那么最简单的逆向方式就是直接解压其压缩包、翻它的源代码就行了(比如StarUML软件的破解汉化的原理这样如此)。
而如果是安卓软件,那么你就得了解Java的字节码,才能完成逆向工作。
是不是感觉头都开始大了?
确实是这样的,所以我才说逆向是一个相当宏大的话题。
但虽然这个话题很宏大,但也并非无迹可寻,这其实和学习编程语言差不多,只要你会了其中一个方向的逆向,那么其它方向的逆向也仅仅是花点时间熟悉一下而已。
编程语言入门,我推荐C/C++,因为只要你学会了C/C++,其它语言都会有一种顺手拈来、水到渠成的感觉。
而逆向入门,我便推荐win32程序逆向,同样的,只要你学会了win32程序的逆向,其它逆向方向也仅仅是需要时间来熟悉而已。
三、软件逆向
win32软件逆向的基本思路只有三步:可执行文件 -> 反汇编 -> 源代码。
其中可执行文件,就是常见的.exe可执行文件,它本质就是一堆带有一定格式的二进制数据,并且与汇编语言一一对应,可以直接通过一些工具将其翻译为汇编代码。
然后我们需要做的事就是,通过分析汇编代码,尝试将其逆向得到对应的源代码。
一般是将其逆向成C/C++代码。
软件逆向的主要内容可以分为三类:
- 软件使用限制的去除或者软件功能的添加。
- 软件源代码的再获得
- 软件的复制和模拟
就目前来说,逆向工程主要用在1和3上。
1常见的破解软件、以及游戏外挂。
3常见的是一些商业公司兼容格式的适配,比如word文档格式是微软开发的,但WPS国产软件同样能打开它,这就是在尝试复制、模拟对方。
但也有可能是微软直接给出了word文档格式,那就不用逆向了,不过这个我并不清楚,你只需要理解这个意思就行了。
至于第2,源代码的再获得,如今很少有这个需求。
因为开源太强大了,如果需要,你基本都可以在github上找到,很少需要去亲自还原源代码的
就算是还原,一般也是还原算法之类的代码。
四、逆向分析技术
在逆向一个软件时,一般有两种分析方案:
- 静态分析
- 动态分析
静态分析指的是不运行程序,直接分析它的二进制代码。
当然这并不是让我们直接看二进制,因为二进制与汇编代码是一一对应的。
所以我们通常会使用一个叫做IDA的软件,将其翻译为汇编代码,然后大致观察、分析整个程序的运行流程,获取到尽可能多的信息。
但静态分析的缺点就是,此时程序没有运行起来,很多东西可能就看不到。
比如一些软件的密钥,一般都是程序运行起来之后,再通过一系列的计算得到的。
所以这个时候就需要进行动态分析,顾名思义,它是让程序跑起来之后再让我们进行分析,可以实时看到程序的运行流程,目前常用的软件为x64dbg。
这个后面会有更详细的进行介绍,这里稍微了解一下就行了。
五、文本字符
对于分析程序来说,文本字符非常重要,因为一个应用程序向用户展示的内容无外乎就两个东西:图像、文本。
在C/C++中,我们就知道有两种字符类型:char与wchar_t。
前者称为窄字节字符,后者称为宽字节字符,其原因就在于前者只占一个字节大小,而后者要占两个字节大小。
更官方的称呼为:ASCII与Unicode。
比如一个字符串:"pediy"。
如果用ASCII码表示,就是下面这样:
70h 65h 64h 69h 79h
而如果用Unicode码表示就是:
0070h 0065h 0064h 0069h 0079h
后面的h代表这是一个十六进制数字。
在vs中写上下面这段代码:
int main() {
char buf[]="pediy";
wchar_t buf1[] = L"pediy";
}
然后进行调试,并打开调试窗口的内存窗口(要在调试状态才能找到):
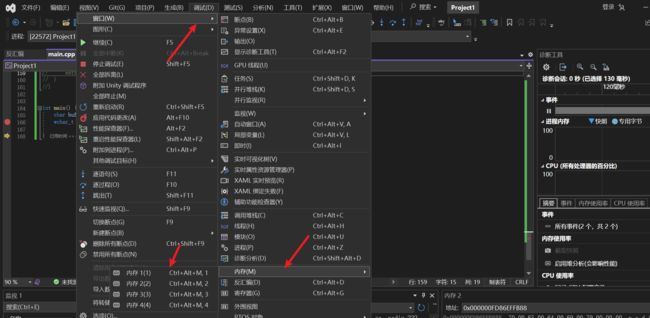
然后从自动窗口中(找不到的,可以从上图打开的二级菜单中找到打开),找到这两个变量在内存中的地址:
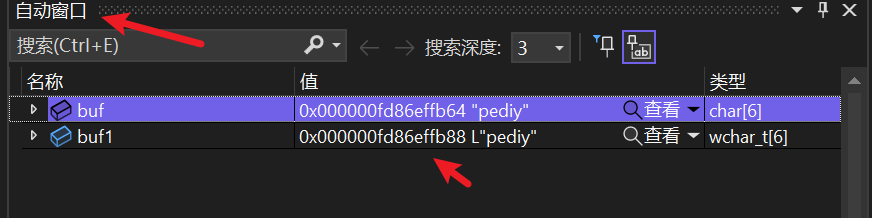
将这个地址复制到内存窗口,就能查看这块内存中的数据了:

最前面的是地址,然后就是该地址上的数据,最后是这个数据通过ASCII码表映射得到的字符。
从这里你也能看到,C/C++语言字符串末尾就是通过0来标识的,即使我们没写,它也默认自带了一个0。
最值得我们关注的是右边宽字节字符数据在内存中的存储方式:70 00,难道不应该是00 70吗?
这就涉及到了字节存储顺序的知识。
字节存储顺序共有两种:大端序、小端序
- 大端序:高位字节数字存放到低位地址上。
- 小端序:高位字节数字存放到高位地址上。
因为正常数据表现形式是从低位地址到高位地址,所以在大端序中,就符合我们的直觉。
00 70这个数字,00是高位,所以放在低地址,也就是前面,70是低位,那就放在后面,最后的结果就是00 70。
而小端序就看起来就完全相反,也就是我们现在所看到的。
00为高位,放在高地址,也就是后面,70为低位,那就放在低地址,也就是前面,最后结果为:70 00。
这中行为取决于CPU。
只是由于目前大部分电脑都用的是intel系列的CPU,而intel系列的CPU就采用的小端序方式。
所以这种看起来比较反直觉的存储方式在逆向过程中会非常的常见,需要特别注意。
六、Windows系统
由于我们计划的是从Windows系统开始学习逆向,那么我们就得对windows系统要有一定的熟悉才行。
想要做windows逆行,我们就得对win api有所了解,这在vc++编程中非常常见,说的直白点,就是头文件windows.h里面的那些函数。
1.Win API
API的全称为:Application Programming Interface,即:应用程序接口。
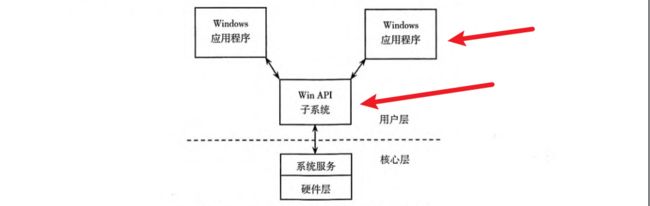
只要你是在windows系统上运行,无论你用的什么开发框架,比如MFC、Qt、甚至Electron,其底层都必定要调用win api(即:windows应用程序编程接口)。
这些所谓的框架,其本质就是对这些系统提供给我们的接口进行了一定程度上的封装。
可以看看下面这张图:
由于最近几十年工业技术的不断发展,电脑系统的位数也在不断的提升,从最初的16位,到后面的32位,再到现在的64位。
win api也有了很多变化,16位windows系统上的api一般被称为win16 api,32位操作系统上的api则被称为win32 api,相比于16位,32位的功能提升了很多。
而现代的64位相比于32位,api的函数名和功能基本没有变化,只是用的64位代码来重新实现了一遍。
由于目前16位操作操作系统基本已经被淘汰了,所以不再过多赘述,我们重心放在32位上。
因此,前期我们主要是分析32位的程序,因为它的位数更少,分析起来相对更容易。
另外,这些win api都是windows操作系统通过动态库导出的。
因此windows系统运转的核心就是动态链接,也即动态库(.dll),在文章:动态库与静态库中,我介绍过如何用vc++来制作,不懂的可以先去看看。
逆向想要厉害,你首先得对正向开发有一定的了解才行。
这些动态库你可以从这两个目录中找到:C:\Windows\System32与C:\Windows\SysWOW64
我目前为
win11系统,如果你的系统版本过低,比如win7之下的,可能还存在于目录:C:\Windows\System
这些目录下的所有dll文件,就是windows系统运行的根基:

如果你删除了它们中的某一个,你的系统可能就会出现问题。
虽然它总共有数千个动态库,但实际上对于逆向来说,最常遇到的有三个,且分别代表一个子系统:
Kernel(kernel32.dll):操作系统的核心功能服务,比如进程、线程控制,内存管理,文件访问等User(user32.dll):负责处理用户接口,比如键盘、鼠标输入,窗口和菜单管理等。GDI(gdi32.dll):图形设备接口,允许程序在屏幕、打印机上显示文本和图形。
除此之外,也有负责其它功能的模块:
advapi32.dll:包括对象安全性、注册表操作comctl32.dll:通用控件comdlg32:公共对话框shell32.dll:用户界面外壳netapi32.dll:网络
在vc++编程中,我们使用的函数就是从这些dll文件中导出来的。
一般这些函数中,很多都有两个版本。
比如以弹出消息框的函数MessageBox为例,它就存在于user32.dll中。
它并不是一个函数,在vs环境下,它只是一个宏,并且会在不同情况下,替换为以下两个版本的函数:
MessageBoxA:参数为窄字节(char*)MessageBoxW:参数为宽字节(wchar_t*)
A为ANSI,W为Wide chars(Unicode)。
且操作系统内核默认使用的是宽字符。
也就是说,就算你调用窄字符版本的函数,其实也会被转换为宽字符之后才会被执行,这中间就会存在一定的效率损耗。
这就意味着,使用宽字节版本的win32 api函数,一般来说效率会更高。
之所以要讲这些,其目的在于,既然我们已经知道了只要是在windows系统上运行的程序都必定会调用这些win api函数,那么我们是不是就可以拦截呢?
比如一个程序要弹出对话框来让你注册,我们就可以找找看有没有对应的弹出对话框的API,然后直接拦截它,从而进行逆向。
这就是windows逆向中最简单直接的方式了,虽然如今的程序想要通过这种方式直接破解有点不现实,但如果你能找到2010年左右甚至以前的软件,基本都可以使用这种方式破开。
2.WOW64
然后再回到主题,前面我说的比较宽泛,现在再来看看32位于64位的区别,比如64位操作系统为什么能运行32位的程序?
而反过来肯定不行,32位操作系统是无法运行64位应用程序的。
64位操作系统的文件(主要就是那些dll),存放的位置就是前面提到的文件夹C:\Windows\System32。
而它之所以能兼容运行32位程序,则归功于文件夹:C:\Windows\SysWOW64,这个文件夹里面存放的就是32位操作系统文件。
其中WOW64其全称为WIndows-on-Windows 64-bit,它是一个windows操作系统上的子系统,意思大概就是让原本的32位程序也可以运行到64位电脑上。
如果是一个64位应用程序启动,就会直接去加载system32目录下的动态库文件:kernel32.dll,user32.dll,ntdll.dll。
netdll.dll是内核态、更加底层的dll文件,其它dll文件是在其基础之上实现的。
而如果是32位应用程序启动,WOW64就会建立32位netdll.dll所需的环境,比如将CPU模式切换到32位,并执行32位程序的加载器,就和原生运行一样。
但此时你对32位netdll.dll的任何调用,都会被重新定向到64位的netdll.dll上。
直白的来说就是,当你在32位程序中调用win api,其底层会自动去调用对应的64位win api,执行结束后再将结果重新转化为32位并交换给你。
也因此,WOW64并不支持16位的程序,也不支持加载32位内核模式的驱动程序,它只能加载32位的dll与运行可执行文件。
这个涉及到了windows的历史,只需要稍稍了解一下即可,实际逆向中大多数情况下是不用管这些教底层的东西的。
3.Windows消息机制
说完这个,再来聊聊Windows消息机制。
Windows本质上就是一个由消息驱动的系统,它提供了不同应用程序之间、程序与操作系统之间进行通信的方式。
Windows系统中有两种消息队列:
- 系统消息队列:比如鼠标、键盘等移动点击事件,都是被首先交由操作系统的,即首先存放到系统的消息队列中。
- 应用程序消息队列:如果某个消息属于某个程序,那么系统就会把这个消息复制到这个程序的消息队列中,这也就是我们在
vc++中可进行编程的部分,更多内容可以查看本站的另一篇文章:从零实现一个Windows窗口。
以下是一些我们常用的函数与消息:
SendMessage函数:用于给某个窗口发送一条消息。WM_COMMAND消息:用户点击应用程序上的菜单、按钮时,就会发送该消息给其父窗口,或者按下某个快捷键释放的时候也会发送。WM_DESTORY消息:窗口被销毁时会发送这条消息。WM_GETTEXT消息:将对应窗口的文本复制到发送方提供的缓存区中。WM_QUIT消息:如果应用程序调用PostQuitMessage函数,就会生成生成这个消息,用于退出当前程序。WM_LBUTTONDOWN消息:鼠标左键按下,就会发送这个消息给窗口。
消息有很多,没必要记,你只需要知道有这么个东西,以及明白windows系统本身是由消息驱动的就可以了。
在自己需要的时候,就去浏览器中搜一搜,看有没有对应的消息即可。
4.虚拟内存
不知道你有没有想过,先不说64位程序,单单是32位程序,一个就要4G内存,目前大多数电脑内存都是16G的,那岂不是只能运行起来4个程序?
而如果是64位的,那就更恐怖了,一个应用程序就得要2的64次方大小的内存,都不是多少G的问题了,而是16T左右了,1T=1024G。
这样搞肯定是不行的,而这就是虚拟内存的作用。
你想过为什么32位程序中指针大小固定为32位,64位程序中指针大小固定为64位吗?
因为指针本身就是用来寻址、存放地址的,你必须要有这么多位才能存放这么大的地址呀!
虚拟内存的作用就在于:它并不会实际给你分配足额的内存,而是给你一块足额的虚拟地址的内存,你可以用指针任意访问这块虚拟内存上的地址(只是地址,没有内存)。
然后当你想要使用某一块内存存放数据了,那系统再切切实实的给你分配一块内存来存放这个数据,并且通过虚拟内存管理器将这个内存地址映射到你应用程序中的虚拟内存地址上。
举个例子,假设你现在要访问地址为10000的内存并存放数字,实际上操作系统可能是在内存地址为10的地方存放的这个数据,并将这个地址10000映射到实际的内存地址10上。
以后只要你访问、修改地址10000,实际上操作系统都是去修改地址为10的内存。
此时地址10000就是虚拟的,而地址10则是货真价实的,也正因如此,不同应用程序无法直接交换数据,因为它们所使用的内存地址都是相互独立的、虚拟的。
这就是进程相互独立的原因。
上面的内容主要有以下几个要点:
- 应用程序不会直接访问物理地址,而是访问的虚拟内存,然后通过虚拟内存管理器去访问实际的物理内存。
- 虚拟内存管理器通过对虚拟地址的访问请求来控制所有的物理地址访问。
- 每个应用程序都有独立的虚拟空间,不同应用程序的地址空间是彼此隔离的。
同时,对于DLL程序来说,是没有“私有”空间的,它们总是被映射到其他应用程序的地址空间中,作为其他应用程序的一部分运行。
其原因是:如果DLL不与其他程序处于同一个地址空间,应用程序就无法调用它。
最后,由于我们程序需要调用系统提供给我们的服务(win api),所以也需要将系统代码映射到我们的虚拟内存中,我们才能使用。
一般来说就是后一半,比如32位为4G大小内存,后面2G就是系统的代码地址,我们实际可用的只有前面2G。
64位则要大得多,我们可用前面8T大小的地址。
虚拟内存是一个比较重要的点,但这里的系统占一半内存地址空间应该很容易让新手迷糊。
简单点来说就是,系统代码只会存放一份复制到内存中,一般是开机启动的时刻就完成的。
此后无论你启动多少个程序,这块代码都已经在内存中了,所以无需重新加载,但你程序想要访问却必须要先建立地址映射,需要建立多少呢?就是一半!
所以虽然系统占程序一半内存地址,并不意味着每次加载一个应用,系统都会往内存填2G大小的系统模块代码。
至此,本文就完成了windows系统基本内容的介绍,从后文开始,我们就将开始实战,学习如何开始逆向一个应用程序。
原文以及后续文章可点击查看:逆向基础