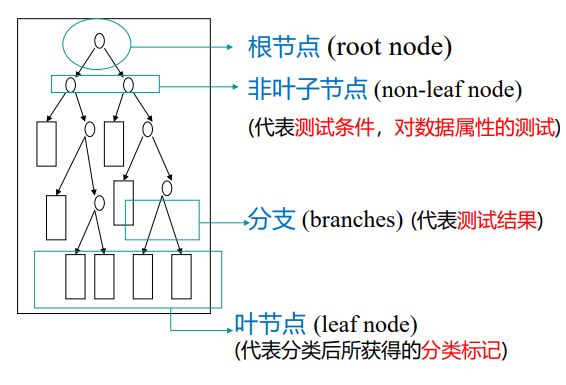
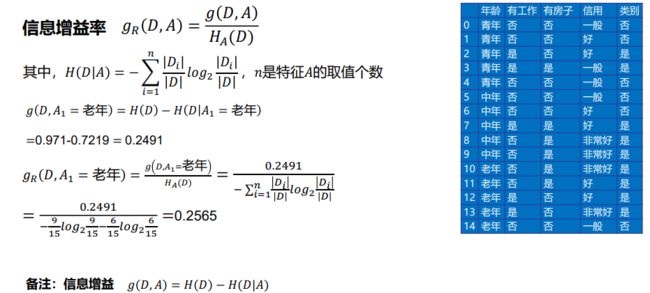
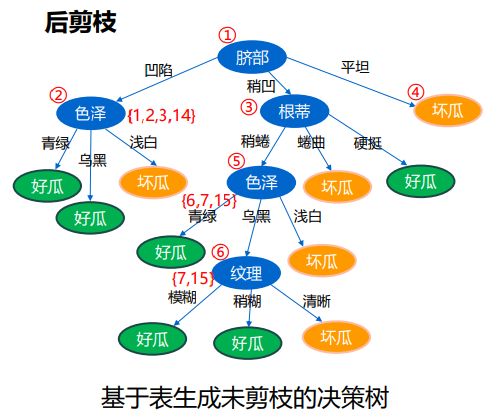
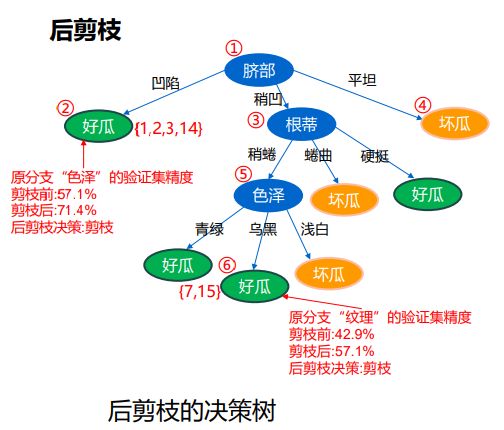
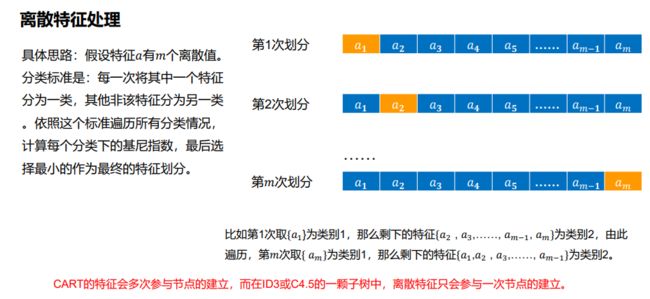
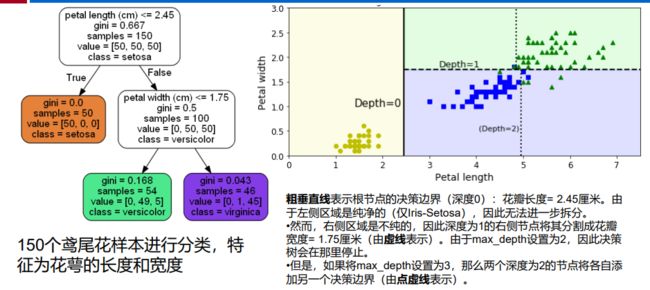
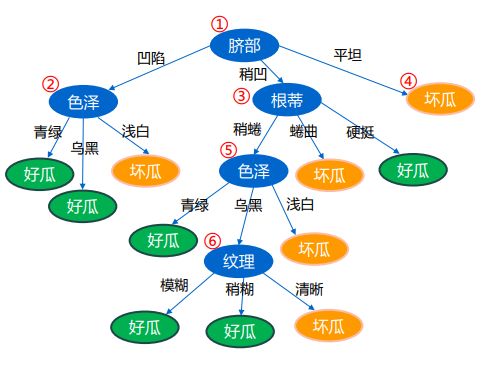
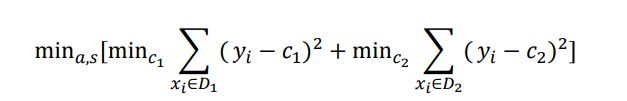- C++ 11 Lambda表达式和min_element()与max_element()的使用_c++ lamda函数 min_element((1)
2401_84976182
程序员c语言c++学习
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上CC++开发知识点,真正体系化!由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新如果你需要这些资料,可以戳这里获取#include#include#includeusingnamespacestd;boolcmp(int
- 基于链家网的二手房数据采集清洗与可视化分析
Mint_Datazzh
项目selenium网络爬虫
个人学习内容笔记,仅供参考。项目链接:https://gitee.com/rongwu651/lianjia原文链接:基于链家网的二手房数据采集清洗与可视化分析–笔墨云烟研究内容该课题的主要目的是通过将二手房网站上的存量与已销售房源,构建一个二手房市场行情情况与房源特点的可视化平台。该平台通过HTML架构和Echarts完成可视化的搭建。因此,该课题的主要研究内容就是如何利用相关技术设计并实现这样
- 算法学习笔记:17.蒙特卡洛算法 ——从原理到实战,涵盖 LeetCode 与考研 408 例题
在计算机科学和数学领域,蒙特卡洛算法(MonteCarloAlgorithm)以其独特的随机抽样思想,成为解决复杂问题的有力工具。从圆周率的计算到金融风险评估,从物理模拟到人工智能,蒙特卡洛算法都发挥着不可替代的作用。本文将深入剖析蒙特卡洛算法的思想、解题思路,结合实际应用场景与Java代码实现,并融入考研408的相关考点,穿插图片辅助理解,帮助你全面掌握这一重要算法。蒙特卡洛算法的基本概念蒙特卡
- 分布式学习笔记_04_复制模型
NzuCRAS
分布式学习笔记架构后端
常见复制模型使用复制的目的在分布式系统中,数据通常需要被分布在多台机器上,主要为了达到:拓展性:数据量因读写负载巨大,一台机器无法承载,数据分散在多台机器上仍然可以有效地进行负载均衡,达到灵活的横向拓展高容错&高可用:在分布式系统中单机故障是常态,在单机故障的情况下希望整体系统仍然能够正常工作,这时候就需要数据在多台机器上做冗余,在遇到单机故障时能够让其他机器接管统一的用户体验:如果系统客户端分布
- 算法学习笔记:15.二分查找 ——从原理到实战,涵盖 LeetCode 与考研 408 例题
呆呆企鹅仔
算法学习算法学习笔记考研二分查找
在计算机科学的查找算法中,二分查找以其高效性占据着重要地位。它利用数据的有序性,通过不断缩小查找范围,将原本需要线性时间的查找过程优化为对数时间,成为处理大规模有序数据查找问题的首选算法。二分查找的基本概念二分查找(BinarySearch),又称折半查找,是一种在有序数据集合中查找特定元素的高效算法。其核心原理是:通过不断将查找范围减半,快速定位目标元素。与线性查找逐个遍历元素不同,二分查找依赖
- 入门html这篇文章就够了
ξ流ぁ星ぷ132
html前端
HTML笔记文章目录HTML笔记html介绍什么是htmlhtml的作用HTML标签介绍常用标签标签and标签and标签u标签del删除线br标签用于换行pre标签,预处理标签span标签div标签sub标签andsup标签hr标签h1,h2...h6标签:HTML5中的语义标签:特殊字符img标签a标签第一种用法:超链接第二种用法:锚点video标签表格标签:form标签input标签selec
- OKHttp3源码分析——学习笔记
Sincerity_
源码相关Okhttp源码解析读书笔记httpclientcache
文章目录1.HttpClient与HttpUrlConnection的区别2.OKHttp源码分析使用步骤:dispatcher任务调度器,(后面有详细说明)Request请求RealCallAsyncCall3.OKHttp架构分析1.异步请求线程池,Dispather2.连接池清理线程池-ConnectionPool3.缓存整理线程池DisLruCache4.Http2异步事务线程池,http
- LangChain中的向量数据库接口-Weaviate
洪城叮当
langchain数据库经验分享笔记交互人工智能知识图谱
文章目录前言一、原型定义二、代码解析1、add_texts方法1.1、应用样例2、from_texts方法2.1、应用样例3、similarity_search方法3.1、应用样例三、项目应用1、安装依赖2、引入依赖3、创建对象4、添加数据5、查询数据总结前言 Weaviate是一个开源的向量数据库,支持存储来自各类机器学习模型的数据对象和向量嵌入,并能无缝扩展至数十亿数据对象。它提供存储文档嵌
- vue3面试题(个人笔记)
武昌库里写JAVA
面试题汇总与解析课程设计springbootvue.jsjava学习
vue3比vue2有什么优势?性能更好,打包体积更小,更好的ts支持,更好的代码组织,更好的逻辑抽离,更多的新功能。描述Vue3生命周期CompositionAPI的生命周期:onMounted()onUpdated()onUnmounted()onBeforeMount()onBeforeUpdate()onBeforeUnmount()onErrorCaptured()onRenderTrac
- Python学习笔记5|条件语句和循环语句
iamecho9
Python从0到1学习笔记python学习笔记
一、条件语句条件语句用于根据不同的条件执行不同的代码块。1、if语句基本语法:if布尔型语句1:代码块#语句1为True时执行的代码示例:age=int(input("请输入你的年龄:"))ifage>=18:print("你已成年")2、if-else语句如果if条件不成立,则执行else代码块:if布尔型语句1:代码块#语句1为True时执行的代码else:代码块#语句1为False时执行的代
- swagger【个人笔记】
撰卢
笔记java
文章目录swagger导入mave坐标在配置类(WebMvcConfiguration)中加入knife4j相关配置设置静态资源映射,主要是让拦截器放行swagger常用注解@Api(tags="\[描述这个类的作用]")@ApiModel(description="\[描述这个类的作用]")@ApiModelProPerty("描述这个类的作用")@ApiOperation("\[描述方法的作用
- 【个人笔记】负载均衡
撰卢
笔记负载均衡运维
文章目录nginx反向代理的好处负载均衡负载均很的配置方式均衡负载的方式nginx反向代理的好处提高访问速度进行负载均衡保证后端服务安全负载均衡负载均衡,就是把大量的请求按照我们指定的方式均衡的分配给集群中的每台服务器负载均很的配置方式upstreamwebservers{server192.168.100.128:8080server192.168.100.129:8080}server{lis
- Python的科学计算库NumPy(一)
linlin_1998
pythonnumpy开发语言
NumPy(NumericalPython)是Python中最基础、最重要的科学计算库之一,提供了高性能的多维数组(ndarray)对象和大量数学函数,是许多数据科学、机器学习库(如Pandas、SciPy、TensorFlow等)的基础依赖。1.创建一个numpy里面的一维数组importnumpyasnp###通过array方法创建一个ndarrayarray1=np.array([1,2,3
- 在 Obsidian 中本地使用 DeepSeek — 无需互联网!
知识大胖
NVIDIAGPU和大语言模型开发教程人工智能deepseek
简介您是否想在Obsidian内免费使用类似于ChatGPT的本地LLM?如果是,那么本指南适合您!我将引导您完成在Obsidian中安装和使用DeepSeek-R1模型的确切步骤,这样您就可以在笔记中拥有一个由AI驱动的第二大脑。推荐文章《24GBGPU中的DeepSeekR1:UnslothAI针对671B参数模型进行动态量化》权重1,DeepSeek类《在RaspberryPi上运行语音识别
- 微算法科技的前沿探索:量子机器学习算法在视觉任务中的革新应用
MicroTech2025
量子计算算法
在信息技术飞速发展的今天,计算机视觉作为人工智能领域的重要分支,正逐步渗透到我们生活的方方面面。从自动驾驶到人脸识别,从医疗影像分析到安防监控,计算机视觉技术展现了巨大的应用潜力。然而,随着视觉任务复杂度的不断提升,传统机器学习算法在处理大规模、高维度数据时遇到了计算瓶颈。在此背景下,量子计算作为一种颠覆性的计算模式,以其独特的并行处理能力和指数级增长的计算空间,为解决这一难题提供了新的思路。微算
- 5G标准学习笔记14 - CSI--RS概述
刘孬孬沉迷学习
5G学习笔记信息与通信
5G标准学习笔记14-CSI–RS概述大家好~,这里是刘孬孬,今天带着大家一起学习一下5GNR中一个非常非常重要的参考信号------------------CSI-RS信号,CSI-RS不是持续发送,UE只能在网络明确配置了CSI-RS的情况下才能使用其进行信道测量。前言对于CSI-RS,肯定还离不开前面所说的CSI(channelstateinformation),前面也讲过CSI对于MIMO
- 5G标准学习笔记06-基于AI/ML波束管理
刘孬孬沉迷学习
5G学习笔记
5G标准学习笔记06-基于AI/ML波束管理前言前面对于孬孬学习了波束管理的概述,下面要进一步来看一下传统波束管理和现在3GPP中推动的AL/ML波束管理之前的区别联系。一、传统波束管理方法流程传统BM流程主要包括以下步骤:波束扫描(BeamSweeping):gNB通过顺序发送多个窄波束(SSB或CSI-RS),覆盖整个服务区域,UE测量每个波束的信号质量(如L1-RSRP或L1-SINR)。波
- 5G标准学习笔记03- CSI 反馈增强概述
刘孬孬沉迷学习
5G笔记学习
5G标准学习笔记03-CSI反馈增强概述大家好,最近在研究AI/ML3gpp标准NR空口的有关内容,后面可能会给大家介绍一下对应的有关内容AI/ML在3GPP标准中的研究进展在AI/ML在NR空口的应用中,对应标准主要聚焦了3个case进行讨论研究分别是:CSI反馈增强;波束管理;定位精度增强;这三个内容可能比较涉及RAN1/2的具体内容,后面会基于这个进行一定的介绍。今天主要是主要介绍CSI反馈
- 运维笔记<4> xxl-job打通
GeminiJM
运维javaxxl-job
新的一天,来点新的运维业务,今天是xxl-job的打通其实在非集群中,xxl-job的使用相对是比较简单的,相信很多人都有使用的经验这次我们的业务场景是在k8s集群中,用xxl-job来做定时调度加上第一次倒腾,也是遇到了不少问题,在这里做一些记录1.xxl-job的集群安装首先是xxl-job的集群安装先贴上xxl-jobsql初始化文件的地址:xxl-job/doc/db/tables_xxl
- 两台pc如何高速度传输大文件
费城之鹰
其他两台电脑高速传输文件局域网不适用U盘传输资料网线直连两台电脑传资料
今天笔记本跑一个大一点的项目,8G的内存直接100%,i5的CPU直接75%并且在超频工作了,原本1.6Ghz的频率直接飙到了3.8Ghz,由于项目性质原因,采用的是公司配的笔记本,但是年初采购的联想E480,还在三包时间段内,公司不允许拆机增加内存,只能换一台新的台式机,听起来挺爽,有新设备,但是办公区域不准使用U盘这一类的存储设备,这就蛋疼了,大半年了项目代码,资料全在这个不够用的笔记本里,问
- 学习笔记(33):matplotlib绘制简单图表-绘制混淆矩阵热图
宁儿数据安全
#机器学习学习笔记matplotlib
学习笔记(33):matplotlib绘制简单图表-绘制混淆矩阵热图一、绘制混淆矩阵热图代码解析1.1、导入必要的库importmatplotlib.pyplotaspltfromsklearn.metricsimportconfusion_matriximportseabornassnsmatplotlib.pyplot:Python中最常用的绘图库,用于创建各种图表confusion_matr
- 玩转Docker | 使用Docker部署NotepadMX笔记应用程序
心随_风动
玩转Dockerdocker笔记eureka
玩转Docker|使用Docker部署NotepadMX笔记应用程序前言一、NotepadMX介绍工具简介主要特点二、系统要求环境要求环境检查Docker版本检查检查操作系统版本三、部署NotepadMX服务下载NotepadMX镜像编辑部署文件创建容器检查容器状态检查服务端口安全设置四、访问NotepadMX服务访问NotepadMX首页设置访问验证编辑笔记总结前言在如今快节奏的工作与学习中,一
- 【前端】异步任务风控验证与轮询机制技术方案(通用笔记版)
一、背景场景在某类生成任务中,例如用户点击“执行任务”按钮后触发一个较耗时的后端操作(如生成报告、渲染图像、转码视频等),由于其调用了模型、渲染服务或需要较长处理时间,为了防止接口被频繁恶意调用,系统需要加入风控验证机制。此外,因任务处理为异步,前端无法立即获得最终结果,因此需通过轮询方式定期查询任务状态,等待任务完成后展示结果。二、整体流程说明1.用户点击“执行任务”按钮:前端调用风控接口/ap
- 数据分析案例-电脑笔记本价格数据可视化分析3
艾派森
数据分析信息可视化python数据分析数据挖掘电脑
♂️个人主页:@艾派森的个人主页✍作者简介:Python学习者希望大家多多支持,我们一起进步!如果文章对你有帮助的话,欢迎评论点赞收藏加关注+目录1.项目背景2.数据集介绍3.技术工具
- 在mac m1基于llama.cpp运行deepseek
lama.cpp是一个高效的机器学习推理库,目标是在各种硬件上实现LLM推断,保持最小设置和最先进性能。llama.cpp支持1.5位、2位、3位、4位、5位、6位和8位整数量化,通过ARMNEON、Accelerate和Metal支持Apple芯片,使得在MACM1处理器上运行Deepseek大模型成为可能。1下载llama.cppgitclonehttps://github.com/ggerg
- LLaMA 学习笔记
AI算法网奇
深度学习基础人工智能深度学习
目录LLaMA模型结构:模型微调手册:推理示例:指定位置加载模型测试ok:模型下载:llama-stack下载modelscope下载LLaMA优化技术RMSNormSwiGLU激活函数旋转位置编码(RoPE)LLaMA模型结构:llama3结构详解-CSDN博客模型微调手册:大模型微调LLaMA详细指南(准备环境、数据、配置微调参数+微调过程)_llama微调-CSDN博客显存占用:FP16/B
- BOOT_KEY按键(学习笔记)
小高Baby@
学习笔记
先来让我们了解一下GPIO是什么吧,它在单片机中也有很重要的作用,接下来我们来看看吧。esp32C3是QFN32封装(一种集成电路(IC)封装类型),GPIO引脚一共有22个,从GPIO-0到GPIO-21。从理论上来说,所有的IO引脚都可以复用为任何外设功能,但有些引脚用作连接芯片内部FLASH或者外部FLASH功能时,官方不建议用作其它用途。esp32c3的GPIO,可以用作输入、输出,可以配
- 多线程在Java项目中的使用案例(笔记)
车车不吃香菇
java基础java
多线程在Java项目中的使用案例(笔记)实现runnable接口@OverridepublicBooleanaddMeetingExpertIds(MeetAddExpertDtomeetAddExpertDto,LonguserId){//会议关联到专家//如果需要发给专家newThread(newRunnable(){@Overridepublicvoidrun(){try{if(meetAd
- 【机器学习笔记Ⅰ】9 特征缩放
巴伦是只猫
机器学习机器学习笔记人工智能
特征缩放(FeatureScaling)详解特征缩放是机器学习数据预处理的关键步骤,旨在将不同特征的数值范围统一到相近的尺度,从而加速模型训练、提升性能并避免某些特征主导模型。1.为什么需要特征缩放?(1)问题背景量纲不一致:例如:特征1:年龄(范围0-100)特征2:收入(范围0-1,000,000)梯度下降的困境:量纲大的特征(如收入)会导致梯度更新方向偏离最优路径,收敛缓慢。量纲小的特征(如
- Kotlin学习笔记
qq_26907861
1.Val和Varval:用于声明不可变量,不可变是指引用不可变;var:用于声明可变的变量;packagehello//可选的包头funmain(args:Array){//包级可见的函数,接受一个字符串数组作为参数vala="不可变的变量"//不可变的变量varn=2//可变println(a)println(n)}2.fun函数Kotlin中的函数可以这样声明:fun函数名(参数列表):返回
- 面向对象面向过程
3213213333332132
java
面向对象:把要完成的一件事,通过对象间的协作实现。
面向过程:把要完成的一件事,通过循序依次调用各个模块实现。
我把大象装进冰箱这件事为例,用面向对象和面向过程实现,都是用java代码完成。
1、面向对象
package bigDemo.ObjectOriented;
/**
* 大象类
*
* @Description
* @author FuJian
- Java Hotspot: Remove the Permanent Generation
bookjovi
HotSpot
openjdk上关于hotspot将移除永久带的描述非常详细,http://openjdk.java.net/jeps/122
JEP 122: Remove the Permanent Generation
Author Jon Masamitsu
Organization Oracle
Created 2010/8/15
Updated 2011/
- 正则表达式向前查找向后查找,环绕或零宽断言
dcj3sjt126com
正则表达式
向前查找和向后查找
1. 向前查找:根据要匹配的字符序列后面存在一个特定的字符序列(肯定式向前查找)或不存在一个特定的序列(否定式向前查找)来决定是否匹配。.NET将向前查找称之为零宽度向前查找断言。
对于向前查找,出现在指定项之后的字符序列不会被正则表达式引擎返回。
2. 向后查找:一个要匹配的字符序列前面有或者没有指定的
- BaseDao
171815164
seda
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
public class BaseDao {
public Conn
- Ant标签详解--Java命令
g21121
Java命令
这一篇主要介绍与java相关标签的使用 终于开始重头戏了,Java部分是我们关注的重点也是项目中用处最多的部分。
1
- [简单]代码片段_电梯数字排列
53873039oycg
代码
今天看电梯数字排列是9 18 26这样呈倒N排列的,写了个类似的打印例子,如下:
import java.util.Arrays;
public class 电梯数字排列_S3_Test {
public static void main(S
- Hessian原理
云端月影
hessian原理
Hessian 原理分析
一. 远程通讯协议的基本原理
网络通信需要做的就是将流从一台计算机传输到另外一台计算机,基于传输协议和网络 IO 来实现,其中传输协议比较出名的有 http 、 tcp 、 udp 等等, http 、 tcp 、 udp 都是在基于 Socket 概念上为某类应用场景而扩展出的传输协
- 区分Activity的四种加载模式----以及Intent的setFlags
aijuans
android
在多Activity开发中,有可能是自己应用之间的Activity跳转,或者夹带其他应用的可复用Activity。可能会希望跳转到原来某个Activity实例,而不是产生大量重复的Activity。
这需要为Activity配置特定的加载模式,而不是使用默认的加载模式。 加载模式分类及在哪里配置
Activity有四种加载模式:
standard
singleTop
- hibernate几个核心API及其查询分析
antonyup_2006
html.netHibernatexml配置管理
(一) org.hibernate.cfg.Configuration类
读取配置文件并创建唯一的SessionFactory对象.(一般,程序初始化hibernate时创建.)
Configuration co
- PL/SQL的流程控制
百合不是茶
oraclePL/SQL编程循环控制
PL/SQL也是一门高级语言,所以流程控制是必须要有的,oracle数据库的pl/sql比sqlserver数据库要难,很多pl/sql中有的sqlserver里面没有
流程控制;
分支语句 if 条件 then 结果 else 结果 end if ;
条件语句 case when 条件 then 结果;
循环语句 loop
- 强大的Mockito测试框架
bijian1013
mockito单元测试
一.自动生成Mock类 在需要Mock的属性上标记@Mock注解,然后@RunWith中配置Mockito的TestRunner或者在setUp()方法中显示调用MockitoAnnotations.initMocks(this);生成Mock类即可。二.自动注入Mock类到被测试类 &nbs
- 精通Oracle10编程SQL(11)开发子程序
bijian1013
oracle数据库plsql
/*
*开发子程序
*/
--子程序目是指被命名的PL/SQL块,这种块可以带有参数,可以在不同应用程序中多次调用
--PL/SQL有两种类型的子程序:过程和函数
--开发过程
--建立过程:不带任何参数
CREATE OR REPLACE PROCEDURE out_time
IS
BEGIN
DBMS_OUTPUT.put_line(systimestamp);
E
- 【EhCache一】EhCache版Hello World
bit1129
Hello world
本篇是EhCache系列的第一篇,总体介绍使用EhCache缓存进行CRUD的API的基本使用,更细节的内容包括EhCache源代码和设计、实现原理在接下来的文章中进行介绍
环境准备
1.新建Maven项目
2.添加EhCache的Maven依赖
<dependency>
<groupId>ne
- 学习EJB3基础知识笔记
白糖_
beanHibernatejbosswebserviceejb
最近项目进入系统测试阶段,全赖袁大虾领导有力,保持一周零bug记录,这也让自己腾出不少时间补充知识。花了两天时间把“传智播客EJB3.0”看完了,EJB基本的知识也有些了解,在这记录下EJB的部分知识,以供自己以后复习使用。
EJB是sun的服务器端组件模型,最大的用处是部署分布式应用程序。EJB (Enterprise JavaBean)是J2EE的一部分,定义了一个用于开发基
- angular.bootstrap
boyitech
AngularJSAngularJS APIangular中文api
angular.bootstrap
描述:
手动初始化angular。
这个函数会自动检测创建的module有没有被加载多次,如果有则会在浏览器的控制台打出警告日志,并且不会再次加载。这样可以避免在程序运行过程中许多奇怪的问题发生。
使用方法: angular .
- java-谷歌面试题-给定一个固定长度的数组,将递增整数序列写入这个数组。当写到数组尾部时,返回数组开始重新写,并覆盖先前写过的数
bylijinnan
java
public class SearchInShiftedArray {
/**
* 题目:给定一个固定长度的数组,将递增整数序列写入这个数组。当写到数组尾部时,返回数组开始重新写,并覆盖先前写过的数。
* 请在这个特殊数组中找出给定的整数。
* 解答:
* 其实就是“旋转数组”。旋转数组的最小元素见http://bylijinnan.iteye.com/bl
- 天使还是魔鬼?都是我们制造
ducklsl
生活教育情感
----------------------------剧透请原谅,有兴趣的朋友可以自己看看电影,互相讨论哦!!!
从厦门回来的动车上,无意中瞟到了书中推荐的几部关于儿童的电影。当然,这几部电影可能会另大家失望,并不是类似小鬼当家的电影,而是关于“坏小孩”的电影!
自己挑了两部先看了看,但是发现看完之后,心里久久不能平
- [机器智能与生物]研究生物智能的问题
comsci
生物
我想,人的神经网络和苍蝇的神经网络,并没有本质的区别...就是大规模拓扑系统和中小规模拓扑分析的区别....
但是,如果去研究活体人类的神经网络和脑系统,可能会受到一些法律和道德方面的限制,而且研究结果也不一定可靠,那么希望从事生物神经网络研究的朋友,不如把
- 获取Android Device的信息
dai_lm
android
String phoneInfo = "PRODUCT: " + android.os.Build.PRODUCT;
phoneInfo += ", CPU_ABI: " + android.os.Build.CPU_ABI;
phoneInfo += ", TAGS: " + android.os.Build.TAGS;
ph
- 最佳字符串匹配算法(Damerau-Levenshtein距离算法)的Java实现
datamachine
java算法字符串匹配
原文:http://www.javacodegeeks.com/2013/11/java-implementation-of-optimal-string-alignment.html------------------------------------------------------------------------------------------------------------
- 小学5年级英语单词背诵第一课
dcj3sjt126com
englishword
long 长的
show 给...看,出示
mouth 口,嘴
write 写
use 用,使用
take 拿,带来
hand 手
clever 聪明的
often 经常
wash 洗
slow 慢的
house 房子
water 水
clean 清洁的
supper 晚餐
out 在外
face 脸,
- macvim的使用实战
dcj3sjt126com
macvim
macvim用的是mac里面的vim, 只不过是一个GUI的APP, 相当于一个壳
1. 下载macvim
https://code.google.com/p/macvim/
2. 了解macvim
:h vim的使用帮助信息
:h macvim
- java二分法查找
蕃薯耀
java二分法查找二分法java二分法
java二分法查找
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
蕃薯耀 2015年6月23日 11:40:03 星期二
http:/
- Spring Cache注解+Memcached
hanqunfeng
springmemcached
Spring3.1 Cache注解
依赖jar包:
<!-- simple-spring-memcached -->
<dependency>
<groupId>com.google.code.simple-spring-memcached</groupId>
<artifactId>simple-s
- apache commons io包快速入门
jackyrong
apache commons
原文参考
http://www.javacodegeeks.com/2014/10/apache-commons-io-tutorial.html
Apache Commons IO 包绝对是好东西,地址在http://commons.apache.org/proper/commons-io/,下面用例子分别介绍:
1) 工具类
2
- 如何学习编程
lampcy
java编程C++c
首先,我想说一下学习思想.学编程其实跟网络游戏有着类似的效果.开始的时候,你会对那些代码,函数等产生很大的兴趣,尤其是刚接触编程的人,刚学习第一种语言的人.可是,当你一步步深入的时候,你会发现你没有了以前那种斗志.就好象你在玩韩国泡菜网游似的,玩到一定程度,每天就是练级练级,完全是一个想冲到高级别的意志力在支持着你.而学编程就更难了,学了两个月后,总是觉得你好象全都学会了,却又什么都做不了,又没有
- 架构师之spring-----spring3.0新特性的bean加载控制@DependsOn和@Lazy
nannan408
Spring3
1.前言。
如题。
2.描述。
@DependsOn用于强制初始化其他Bean。可以修饰Bean类或方法,使用该Annotation时可以指定一个字符串数组作为参数,每个数组元素对应于一个强制初始化的Bean。
@DependsOn({"steelAxe","abc"})
@Comp
- Spring4+quartz2的配置和代码方式调度
Everyday都不同
代码配置spring4quartz2.x定时任务
前言:这些天简直被quartz虐哭。。因为quartz 2.x版本相比quartz1.x版本的API改动太多,所以,只好自己去查阅底层API……
quartz定时任务必须搞清楚几个概念:
JobDetail——处理类
Trigger——触发器,指定触发时间,必须要有JobDetail属性,即触发对象
Scheduler——调度器,组织处理类和触发器,配置方式一般只需指定触发
- Hibernate入门
tntxia
Hibernate
前言
使用面向对象的语言和关系型的数据库,开发起来很繁琐,费时。由于现在流行的数据库都不面向对象。Hibernate 是一个Java的ORM(Object/Relational Mapping)解决方案。
Hibernte不仅关心把Java对象对应到数据库的表中,而且提供了请求和检索的方法。简化了手工进行JDBC操作的流程。
如
- Math类
xiaoxing598
Math
一、Java中的数字(Math)类是final类,不可继承。
1、常数 PI:double圆周率 E:double自然对数
2、截取(注意方法的返回类型) double ceil(double d) 返回不小于d的最小整数 double floor(double d) 返回不大于d的整最大数 int round(float f) 返回四舍五入后的整数 long round