ConcurrentHashMap的死循环问题
文章目录
- 前言
- 1. 情景复现
- 2. 源码解析
- 3. 代码调试
- 4. 原因
- 5. 解决
前言
对于ConcurrentHashMap来说,能保证多线程下的安全问题,但是在JDK1.8中还是会出现一个bug,就是computeIfAbsent,下面就来详细说说死循环的原因
1. 情景复现
首先就是bug的复现,首先了解下computeIfAbsent这个方法有什么用,其实方法第二个参数 lambda 表达式的意思就是如果找不到对应的key,那么就执行第二个方法,第二个方法的返回结果会作为value,和key一起存到 table 上面
abstract class Test {
public static void main(String[] args) throws InterruptedException {
System.out.println("方法开始");
ConcurrentHashMap<String, String> map = new ConcurrentHashMap<>();
System.out.println(map.computeIfAbsent("aaa", key -> {
return "没找到aaa就返回我这个";
}));
System.out.println("方法结束 => " + map);
}
}

然后下面就是整个bug的复现
abstract class Test {
public static void main(String[] args) throws InterruptedException {
System.out.println("方法开始");
ConcurrentHashMap<String, String> map = new ConcurrentHashMap<>();
map.computeIfAbsent("AaAa",
key -> {
return map.computeIfAbsent("BBBB", key2->"BBBB");
});
System.out.println("方法结束 => " + map);
}
}
执行结果:
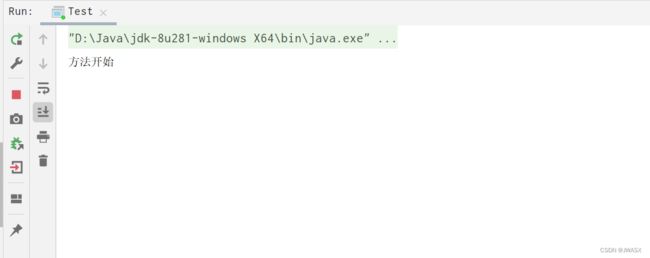
上面就是这个bug的复现了,下面来到源码的解析流程
2. 源码解析
public V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction) {
//首先会判断一下key和调用函数
if (key == null || mappingFunction == null)
throw new NullPointerException();
//计算出hash值
int h = spread(key.hashCode());
V val = null;
int binCount = 0;
//for循环
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//1.当table为null的时候或者长度为0的时候
if (tab == null || (n = tab.length) == 0)
//进行初始化
tab = initTable();
//2. 如果table已经初始化好了并且找到的下标位置是null,就去初始化这个位置
else if ((f = tabAt(tab, i = (n - 1) & h)) == null) {
//设置一个占位的Node,表示这个位置已经被线程占了
//这个node的hash= -3
Node<K,V> r = new ReservationNode<K,V>();
//然后给这个节点加锁
synchronized (r) {
//使用CAS把这个r添加到tab上面
if (casTabAt(tab, i, null, r)) {
binCount = 1;
Node<K,V> node = null;
try {
//注意这里,添加占位节点之后会调用这个函数
//因为我们根据key找不到,所以会调用这个函数
if ((val = mappingFunction.apply(key)) != null)
//调用结果不为null,就创建一个node然后添加到table上面去
node = new Node<K,V>(h, key, val, null);
} finally {
//设置到tab[i]的位置
setTabAt(tab, i, node);
}
}
}
//binCount记录添加的节点数
if (binCount != 0)
//*******************注意第一个跳出循环的点在这里**************************
break;
}
//3. 如果该节点已经是MOVED状态,证明有其他线程正在进行扩容,当前节点被移除到新数组上面了,所以是MOVED
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
//4. 如果上面的都没有发生,进入下面的流程进行添加
else {
boolean added = false;
//对tab节点进行加锁,粒度更小
synchronized (f) {
//5. 再次判断是不是f,如果是,证明没有其他线程进行修改
//因为如果是树化或者其他操作有可能导致头结点被修改
if (tabAt(tab, i) == f) {
//6. fh > 0, 说明是一个正常的节点,要执行正常节点的添加动作
if (fh >= 0) {
...
}
//7. 判断是不是树节点,如果是树节点就用树的添加
else if (f instanceof TreeBin) {
....
}
}
}
//8.判断是不是要树化了
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (!added)
return val;
//*******************注意第二个跳出循环的点在这里**************************
break;
}
}
}
//数量+1
if (val != null)
addCount(1L, binCount);
return val;
}
上面就是整个方法的一个解析的流程,注意上面的数组1-7,以及上面方法中两个能跳出循环的机会
- 第一个跳出的机会是第一次进入的时候判断到要找的节点是null,这时候会调用 computeIfAbsent 的第二个参数,也就是调用方法得到返回值,把这个返回值put 到 table 对应的下标上面,就可以返回了。
- 第二次跳出的机会是正常情况下添加到链表尾部或者添加到树上,然后 binCount 这个参数记录的添加的节点数 != 0,就可以退出,简单来说就是你要把节点能正常添加到 table 中
现在就开始分析这个流程 ,首先是第一次进入 computeIfAbsent
- 首先进入 for 循环,for (Node
- 然后判断 if (tab == null || (n = tab.length) == 0 ) ,没问题,进行初始化
- 接下来再次进入 for 循环,判断 if (tab == null || (n = tab.length) == 0 ) 失效
- 然后判断 else if ((f = tabAt(tab, i = (n - 1) & h)) == null) 成功,此时根据hash找到了下标,下标的值是 null
- 接下来进入上面的else if 流程
- 创建一个占位节点,这个节点 hash 值为 -3,把这个节点使用 CAS 添加到 tab[f(下标)] 上面,成功,因为此时没有多线程竞争
- 重点来了,接下来会调用 mappingFunction.apply(key) 执行我们设置的第二个参数的方法
好了,到现在第一次的 computeIfAbsent 已经分析完成了,此时整个 table 状态就是:已经初始化完成,并且在 table[f] 节点处有一个占位节点,第一次的 computeIfAbsent 陷入等待状态,等待第二次 computeIfAbsent 返回结果
现在开始第二次 computeIfAbsent
- 首先进入 for 循环
- 然后判断 if (tab == null || (n = tab.length) == 0 ) ,已经初始化完了,继续向下走
- 判断 else if ((f = tabAt(tab, i = (n - 1) & h)) == null) 不成功,因为这时候已经被一个占位节点(hash = -3)占用了
- 判断 else if ((fh = f.hash) == MOVED) 失败,因为此时不是扩容状态
- 进入添加链表或者树的流程
- if (tabAt(tab, i) == f) 判断成功,这个 f 是下标的第一个节点,现在不是多线程肯定是成功的
- 判断 if (fh >= 0) 失败,fh 是 f 的 hash,此时 = -3
- 判断 else if (f instanceof TreeBin) 失败,因为不是树节点,只是普通链表节点
- 最后判断 if (binCount != 0) 失败,因为我们并没有完成节点插入工作,所以这里还是 0
- 到这里继续进行 for 循环
3. 代码调试
好了,到这里已经出现死循环了,原因就是第二次 computeIfAbsent 一直在死循环了,而第一次 computeIfAbsent 在等待第二次返回,导致了死循环。下面再来用代码调试一下:
-
进入方法,然后可以看到 AaAa 的 hash 值
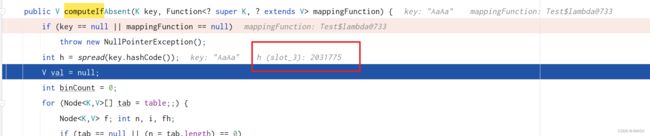
-
接下来初始化数组

-
初始化完成之后再次进入 for 循环
-
判断 (f = tabAt(tab, i = (n - 1) & h)) == null 成功,要设置节点,然后调用 mappingFunction.apply(key) 第二次进入 computeIfAbsent 方法
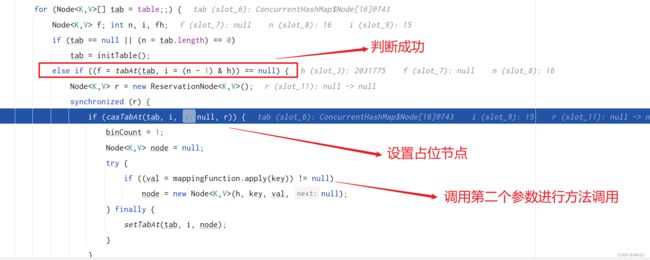
-
第二次进入 computeIfAbsent 方法,可以看到下面BBBB的 hash 值和 AaAa 是一样的

-
判断 if (tab == null || (n = tab.length) == 0) 和 (f = tabAt(tab, i = (n - 1) & h)) == null 失败,下面是此时 table 上面 2031775 的节点
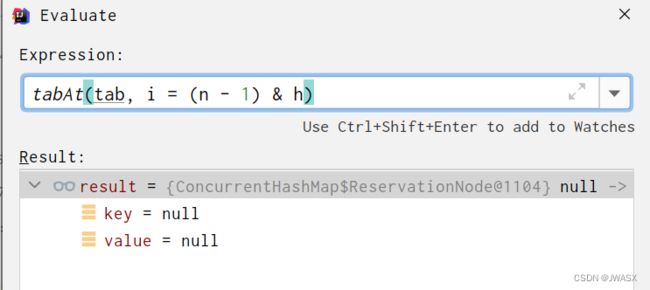
其实可以看出来这是一个ReservationNode节点,它的hash就是 -3
-
判断 else if ((fh = f.hash) == MOVED) 失败,MOVED = -1
-
进入最后一个else

-
判断 if (tabAt(tab, i) == f) 成功

-
判断 if (fh >= 0) 失败,fh = -3 这时候,fh是hash值
-
判断 else if (f instanceof TreeBin) 失败

-
判断 if (binCount != 0) 失败,此时 binCount 还是 0
-
再次进入循环

好了,到这里已经调试完成了
4. 原因
其实到这里就演示完成了,之所以跳不出循环根本原因还是因为没办法把节点添加上 table
- 错过了 table[i] = null 的添加,因为这时候第一次调用该方法的时候已经做了
- 错过了 正常链表和正常树情况下的添加,因为第一次调用该方法把一个占位节点放到了 table[i] ,没办法进行添加,因为能添加的前提是头结点要是一个正常的节点
- 第二次添加不了,不能返回结果给第一次的 computeIfAbsent 方法调用,
其实从上面的过程来看没什么问题,因为第一次 computeIfAbsent 在第二次 computeIfAbsent 没有返回结果之前肯定不能创建处一个真正的 Node 节点出来,只能把一个临时节点放到上面,意思就是告诉其他线程,这个位置我占了,只不过我现在还没有创建链表节点。
5. 解决
那我们来看看 JDK11是怎么解决的
public V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction) {
if (key != null && mappingFunction != null) {
int h = spread(key.hashCode());
V val = null;
int binCount = 0;
ConcurrentHashMap.Node[] tab = this.table;
while(true) {
int n;
//初始化数组
while(tab == null || (n = tab.length) == 0) {
tab = this.initTable();
}
ConcurrentHashMap.Node f;
int i;
ConcurrentHashMap.Node e;
//判断找到的数组下标位置是不是一个null,如果是就添加一个占位节点
if ((f = tabAt(tab, i = n - 1 & h)) == null) {
ConcurrentHashMap.Node<K, V> r = new ConcurrentHashMap.ReservationNode();
synchronized(r) {
if (casTabAt(tab, i, (ConcurrentHashMap.Node)null, r)) {
binCount = 1;
e = null;
try {
//调用第二次computeIfAbsent
if ((val = mappingFunction.apply(key)) != null) {
e = new ConcurrentHashMap.Node(h, key, val);
}
} finally {
setTabAt(tab, i, e);
}
}
}
if (binCount != 0) {
break;
}
} else {
int fh;
if ((fh = f.hash) == -1) {
//如果是 -1,就证明正在扩容,进入协助扩容流程
tab = this.helpTransfer(tab, f);
} else {
Object fk;
Object fv;
//判断第一个节点是不是我们要找的节点
if (fh == h && ((fk = f.key) == key || fk != null && key.equals(fk)) && (fv = f.val) != null) {
return fv;
}
boolean added = false;
synchronized(f) {
if (tabAt(tab, i) == f) {
if (fh < 0) {
if (f instanceof ConcurrentHashMap.TreeBin) {
//树节点的处理
...
//下面就是处理ReservationNode的流程,这里返回一个递归更新的异常错误
} else if (f instanceof ConcurrentHashMap.ReservationNode) {
throw new IllegalStateException("Recursive update");
}
} else {
...
}
}
}
//binCount就是添加的节点数目
if (binCount != 0) {
if (binCount >= 8) {
this.treeifyBin(tab, i);
}
if (!added) {
return val;
}
break;
}
}
}
}
if (val != null) {
this.addCount(1L, binCount);
}
return val;
} else {
throw new NullPointerException();
}
}
上面就是一个大概的流程,其实源码和 JDK8 差不多,但是在JDK11 专门对 fh < 0 进行了处理,并在里面判断 else if (f instanceof ConcurrentHashMap.ReservationNode),判断成功之后返回一个 “Recursive update” 的异常,Java 会认为如果出现这种情况,就发生了递归更新,所以就返回了一个异常。
说白了就是让你代码别这么写。
要是程序中需要用到 computeIfAbsent 的地方,要么就别嵌套调用,要么就先用key 查找一下,找不到就加入到 map中。总之递归不能出现。
下面就是JDK11中执行同样的测试用例的结果:

如果错误,欢迎指出!!!