springboot集成Elk做日志系统(一) 环境搭建
环境搭建
- 一、ELK 介绍
-
-
- **Elasticsearch、Logstash、Kibana作用**
-
- 二、本次采用实现日志收集的方案
-
-
- **logback产生日志->logstash->elasticsearch->kibana**
-
- 三、ELK的安装
-
- [windows 安装 ELK(Elasticsearch,Logstash,kibana)](https://www.cnblogs.com/startlearn/p/10007435.html)
- 1.安装Elasticsearch
- 2.使用 NSSM 软件 将 Elasticsearch,Logstash,kibana 都安装成windows服务
-
- 2.1、Elasticsearch服务安装:
- 2.2、 NSSM 安装服务 elasticsearch
- 2.3、NSSM安装 Logstash
- 2.4、NSSM 安装服务 kibana
- 安装成功并启动后:
- 3.安装elasticsearch集群管理工具head插件,可视化查看es状况
- 四、Spring Boot 搭建 ELK正确看日志的配置流程
-
- 1.系统中添加依赖
-
- maven版本
- gradle版本
- 有可能遇到的问题:依赖下载不下来
-
- 可采用外部引入依赖的方式
- 2.系统中logback-spring.xml的配置
- 3.Kibana的使用
-
- 3.1、建立索引
- 3.2、查看该索引下的数据
- 五、搭建es集群
-
- 1、将ElasticSearch 服务复制3分,分别修改每个ElasticSearch服务的主配置文件 elasticsearch.yml
-
- 1.1、node0节点
- 1.2、node1节点
- 1.3、node2节点
- 2、逐个启动每一台ElasticSearch服务
- 3、启动head插件 访问 http://localhost:9200 地址 访问es服务
- 4、可能出现的问题
-
- 4.1集群启动报错
本系统采用springboot+springcloud+gradle构建,
日志采用logback进行采集,
本文主要包含:环境搭建,es集群,es查询,其他相关;力求能从0开始,完成日志系统的搭建,以及后续日志的分析处理;
后续还有:
springboot集成Elk做日志系统(二)-切面/分词器快速定位日志
springboot集成Elk做日志系统(三)java通过RestHighLevelClient操作es日志
一、ELK 介绍
ELK是三个开源软件的缩写,分别表示:elasticsearch、logstash、kibana
Elasticsearch、Logstash、Kibana作用
-
Elasticsearch: 是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等 ,用于存储日志信息
-
Logstash: 日志收集,springboot利用Logstash把日志发送个Logstash,然后Logstash将日志传递给Elasticsearch。
-
Kibana:通过web端对日志进行可视化操作
二、本次采用实现日志收集的方案
logback产生日志->logstash->elasticsearch->kibana


优点:
此架构搭建简单,容易上手
缺点:
1、每个节点部署logstash,运行时占用CPU,内存大,会对节点性能造成一定的影响
2、没有将日志数据进行缓存,存在丢失的风险
三、ELK的安装
windows 安装 ELK(Elasticsearch,Logstash,kibana)
下载相应软件包:
Elasticsearch 下载:https://www.elastic.co/downloads/elasticsearch
Logstash 下载:https://www.elastic.co/downloads/logstash
kibana 下载:https://www.elastic.co/downloads/kibana
1.安装Elasticsearch
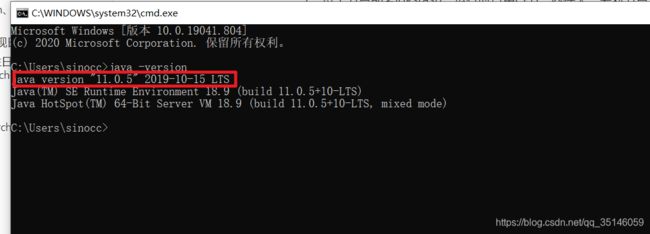
需要安装java SDK(这里就不描述怎么安装Java SDK 了自行网上搜索) 注意 SDK 版本必须是 1.8 及以上, 不知道版本 安装后可以 在cmd 中 用 java -version 查看
Elasticsearch,Logstash,kibana 都是无需安装软件 直接解压安装包即可
最好将 Elasticsearch,Logstash,kibana 解压到同一个目录下(我的目录名为这elk)

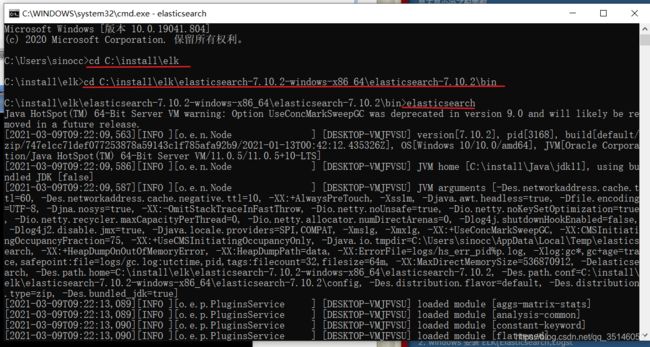
运行cmd (用管理员身份) 就当前运行目录转到 Elasticsearch 的bin 目录下 输入 elasticsearch 回车
如图:
然后 打开浏览器:输入 127.0.0.1:9200
如图 表示正常 :

2.使用 NSSM 软件 将 Elasticsearch,Logstash,kibana 都安装成windows服务
下载NSSM: http://www.nssm.cc/download
下载后解压到文件夹
2.1、Elasticsearch服务安装:
在cmd(要当前运行目录在Elasticsearch的bin下) 中直接运行
elasticsearch-service.bat install
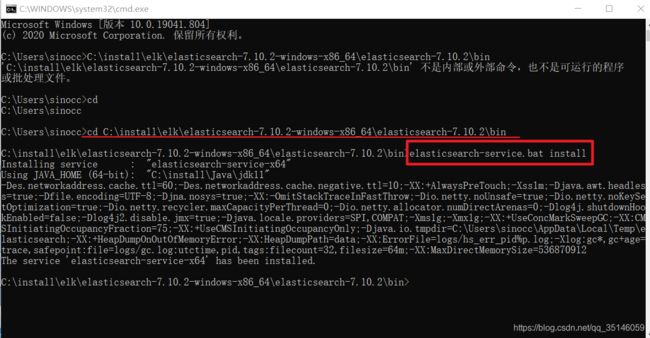
安装成功后可以在 服务列表中看到 elasticsearch的服务即可

2.2、 NSSM 安装服务 elasticsearch
将cmd 当前所在目录设置到 nssm.exe 的目录下运行 nssm install
nssm install

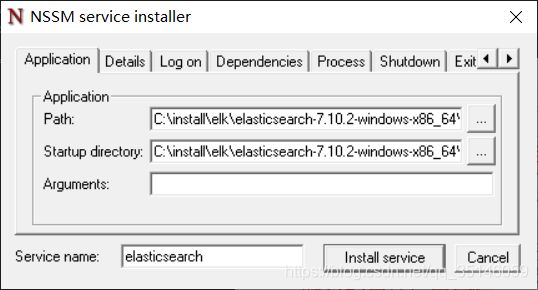
单击 install service 就可以了。
2.3、NSSM安装 Logstash
首先在 logstash的bin目录下 新建一个 logstash.conf 文件:
C:\install\elk\logstash-7.10.2-windows-x86_64\logstash-7.10.2\bin下的logstash.conf文件内容为:
input {
# stdin { }
tcp {
# host:port就是上面appender中的destination,
# 这里其实把Logstash作为服务,开启9250端口接收logback发出的消息
#这个需要配置成本机IP,不然logstash无法启动
host => "127.0.0.1"
#端口号
port => 9250
mode => "server" tags => ["tags"]
#将日志以json格式输入
codec => json_lines
}
}
filter {
grok {
match => [
"message","%{NOTSPACE:tag}[T ]%{NOTSPACE:method}[T ]%{NOTSPACE:api}[T ]%{NOTSPACE:params}",
"message","%{NOTSPACE:tag}[T ]%{NOTSPACE:author}[T ]%{NOTSPACE:msg}"
]
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "logstash-test-%{+YYYY.MM.dd}"
}
stdout { codec => rubydebug }
}

然后在新建一个文件 logstashrunservice.bat
输入logstash.bat -f logstash.conf 并保存
logstash.bat -f logstash.conf

将cmd 当前所在目录设置到 nssm.exe 的目录下运行 nssm install

单击 install service 就可以了。
2.4、NSSM 安装服务 kibana
将cmd 当前所在目录设置到 nssm.exe 的目录下运行 nssm install

单击 install service 就可以了。
如果都安装成功 就可以看到 服务列表 会显示这三个服务
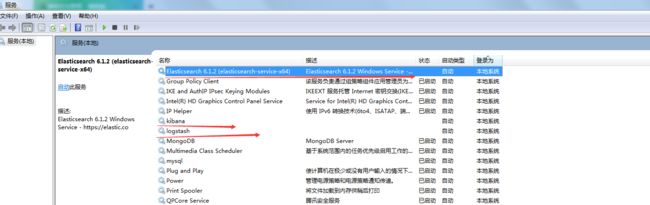
依次启动每个服务。如果每个服务都启动成功了。表示你已经安装成功了。
安装成功并启动后:
在浏览器中输入: http://127.0.0.1:5601/status
如图即为服务都安装启动成功:
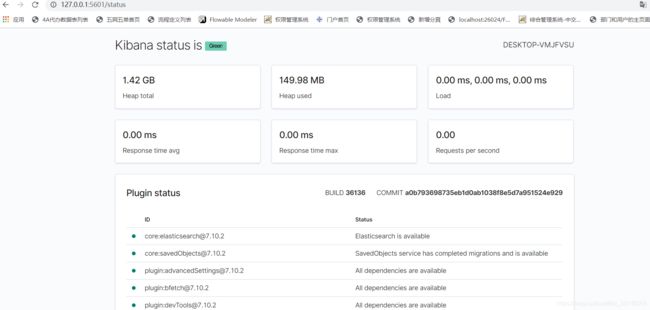
访问 http://127.0.0.1:5601/app/home#/ 即可自行查看各组件的使用

3.安装elasticsearch集群管理工具head插件,可视化查看es状况
chrome的插件 链接分享:
链接:https://pan.baidu.com/s/13oNyZiHkgk20E66DHAwkNg
提取码:pp0y
插件安装方式及报错解决详见:
https://blog.csdn.net/qq_39135287/article/details/89036221
安装成功后:浏览器会有扩展组件

浏览器输入: http://localhost:9200/_plugin/head/
就能看到es的状况了

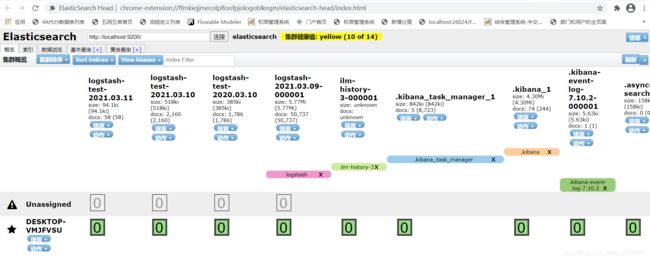
四、Spring Boot 搭建 ELK正确看日志的配置流程
1.系统中添加依赖
maven版本
<dependency>
<groupId>net.logstash.logbackgroupId>
<artifactId>logstash-logback-encoderartifactId>
<version>6.6version>
dependency>
gradle版本
//logback
compile group: 'org.slf4j', name: 'slf4j-api', version: '1.7.25'
compile group: 'ch.qos.logback', name: 'logback-core', version: '1.2.3'
//logstash集成logback
compile 'net.logstash.logback:logstash-logback-encoder:6.6'
有可能遇到的问题:依赖下载不下来
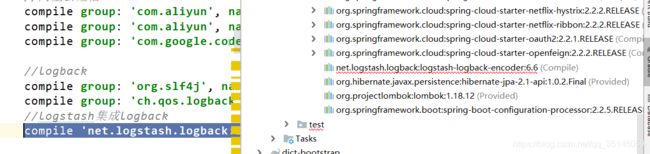
可采用外部引入依赖的方式
打开链接,下载依赖的jar包:
https://mvnrepository.com/artifact/net.logstash.logback/logstash-logback-encoder/6.6
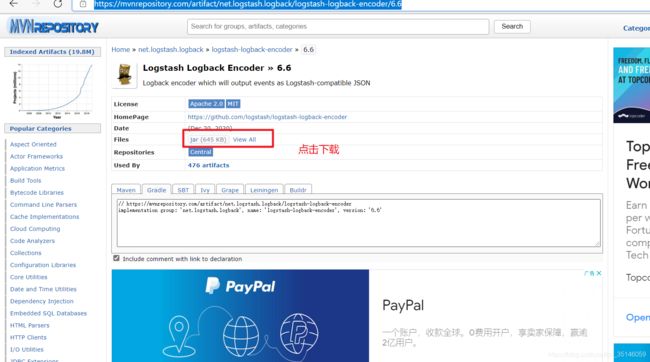
将下载的jar包放入gradle的仓库:
C:\install\Gradle4.5.gradle\caches\modules-2\files-2.1下面建一个文件夹放自己下载的jar包
此处我的位置是
C:\install\Gradle4.5.gradle\caches\modules-2\files-2.1\net.logstash.logback\logstash-logback-encoder\6.6
所以配置的依赖写成:
//logstash集成logback
compile files('C:/install/Gradle4.5/.gradle/caches/modules-2/files-2.1/net.logstash.logback/logstash-logback-encoder/6.6/logstash-logback-encoder-6.6.jar')
即:compile files(‘jar包的位置.jar’)即可
刷新gradle,成功

2.系统中logback-spring.xml的配置
让logback的日志输出到logstash
<configuration>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%date{yyyy-MM-dd HH:mm:ss} %highlight(%-5level) (%file:%line\)- %m%npattern>
<charset>UTF-8charset>
encoder>
appender>
<appender name="syslog" class="ch.qos.logback.core.rolling.RollingFileAppender">
<File>log/ant-back.logFile>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>log/ant-back.%d.%i.logfileNamePattern>
<maxHistory>120maxHistory>
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>100MBmaxFileSize>
timeBasedFileNamingAndTriggeringPolicy>
rollingPolicy>
<encoder>
<pattern>
%d %p (%file:%line\)- %m%n
pattern>
<charset>UTF-8charset>
encoder>
appender>
<appender name="logstash"
class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>127.0.0.1:9250destination>
<encoder
class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>UTCtimeZone>
timestamp>
<pattern>
<pattern>
{
"thread": "%thread",
"logLevel": "%level",
"message": "%message",
"class": "%logger{40}",
"serviceName": "${springAppName:-}",
"trace": "%X{X-B3-TraceId:-}",
"span": "%X{X-B3-SpanId:-}",
"exportable": "%X{X-Span-Export:-}",
"pid": "${PID:-}"
}
pattern>
pattern>
providers>
encoder>
appender>
<root level="INFO">
<appender-ref ref="STDOUT"/>
<appender-ref ref="logstash" />
root>
configuration>
核心为:

3.Kibana的使用
重启自己本地的项目,去浏览器的ELk中建立索引,查看刚才从系统中导入logstash的日志
3.1、建立索引
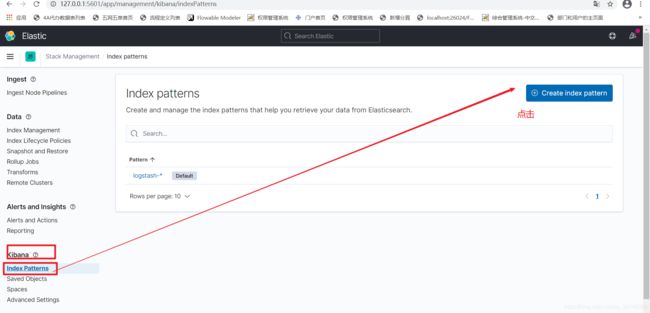
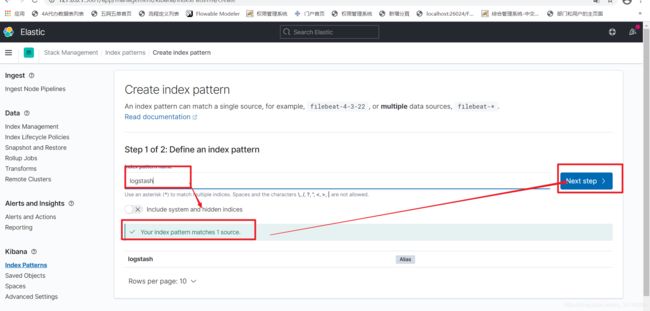
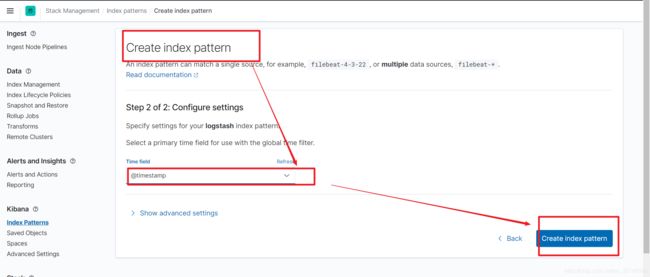
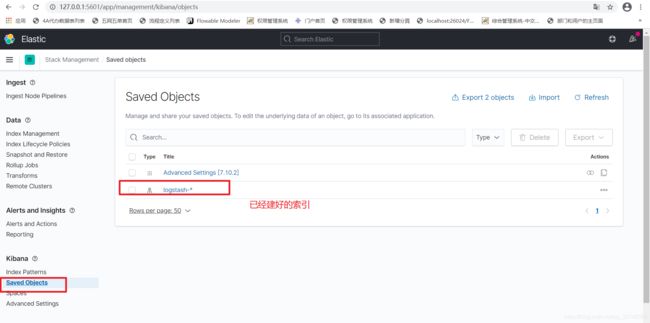
3.2、查看该索引下的数据
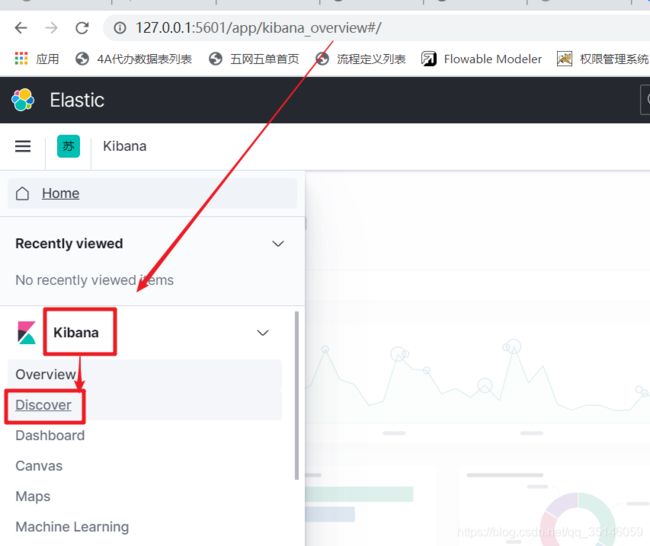

五、搭建es集群
由于之前es集群健康证一直是黄色,所以需要搭建一下es的集群
我们计划集群名称为:my-esCluster,部署3个elasticsearch节点,分别是:
- node0:http端口9200,TCP端口9300
- node1:http端口9201,TCP端口9301
- node2:http端口9202,TCP端口9302
1、将ElasticSearch 服务复制3分,分别修改每个ElasticSearch服务的主配置文件 elasticsearch.yml
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LbLL8JPZ-1615456570438)(C:\syl_own\notes\截图\image-20210311174815669.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uGEqT4ul-1615456570440)(C:\syl_own\notes\截图\image-20210311174847542.png)]
1.1、node0节点
# ================= Elasticsearch Configuration ===================
# 设置集群名称,集群内所有节点的名称必须一致。
cluster.name: my-esCluster
# 设置节点名称,集群内节点名称必须唯一。
node.name: node0
# 表示该节点会不会作为主节点,true表示会;false表示不会
node.master: true
# 当前节点是否用于存储数据,是:true、否:false
node.data: true
# 索引数据存放的位置
#path.data: /opt/elasticsearch/data
# 日志文件存放的位置
#path.logs: /opt/elasticsearch/logs
# 需求锁住物理内存,是:true、否:false
#bootstrap.memory_lock: true
# 监听地址,用于访问该es
network.host: 127.0.0.1
# es对外提供的http端口,默认 9200
http.port: 9200
# TCP的默认监听端口,默认 9300
transport.tcp.port: 9300
# 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4)
discovery.zen.minimum_master_nodes: 2
# es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["127.0.0.1:9300", "127.0.0.1:9301", "127.0.0.1:9302"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
# es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node0", "node1", "node2"]
# 是否支持跨域,是:true,在使用head插件时需要此配置
http.cors.enabled: true
# “*” 表示支持所有域名
http.cors.allow-origin: "*"
1.2、node1节点
# ================= Elasticsearch Configuration ===================
# 设置集群名称,集群内所有节点的名称必须一致。
cluster.name: my-esCluster
# 设置节点名称,集群内节点名称必须唯一。
node.name: node1
# 表示该节点会不会作为主节点,true表示会;false表示不会
node.master: true
# 当前节点是否用于存储数据,是:true、否:false
node.data: true
# 索引数据存放的位置
#path.data: /opt/elasticsearch/data
# 日志文件存放的位置
#path.logs: /opt/elasticsearch/logs
# 需求锁住物理内存,是:true、否:false
#bootstrap.memory_lock: true
# 监听地址,用于访问该es
network.host: 127.0.0.1
# es对外提供的http端口,默认 9200
http.port: 9201
# TCP的默认监听端口,默认 9300
transport.tcp.port: 9301
# 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4)
discovery.zen.minimum_master_nodes: 2
# es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["127.0.0.1:9300", "127.0.0.1:9301", "127.0.0.1:9302"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
# es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node0", "node1", "node2"]
# 是否支持跨域,是:true,在使用head插件时需要此配置
http.cors.enabled: true
# “*” 表示支持所有域名
http.cors.allow-origin: "*"
1.3、node2节点
# ================= Elasticsearch Configuration ===================
# 设置集群名称,集群内所有节点的名称必须一致。
cluster.name: my-esCluster
# 设置节点名称,集群内节点名称必须唯一。
node.name: node2
# 表示该节点会不会作为主节点,true表示会;false表示不会
node.master: true
# 当前节点是否用于存储数据,是:true、否:false
node.data: true
# 索引数据存放的位置
#path.data: /opt/elasticsearch/data
# 日志文件存放的位置
#path.logs: /opt/elasticsearch/logs
# 需求锁住物理内存,是:true、否:false
#bootstrap.memory_lock: true
# 监听地址,用于访问该es
network.host: 127.0.0.1
# es对外提供的http端口,默认 9200
http.port: 9202
# TCP的默认监听端口,默认 9300
transport.tcp.port: 9302
# 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4)
discovery.zen.minimum_master_nodes: 2
# es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["127.0.0.1:9300", "127.0.0.1:9301", "127.0.0.1:9302"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
# es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node0", "node1", "node2"]
# 是否支持跨域,是:true,在使用head插件时需要此配置
http.cors.enabled: true
# “*” 表示支持所有域名
http.cors.allow-origin: "*"
2、逐个启动每一台ElasticSearch服务
转到 Elasticsearch 的bin 目录下
输入
elasticsearch
回车
3、启动head插件 访问 http://localhost:9200 地址 访问es服务

ok:到此ElasticSearch的集群搭建成功
4、可能出现的问题
4.1集群启动报错
原因一:elasticsearch.yml配置文件有误,请检查参数的配置
原因二:还未启动时, 复制上一份的解压包并且解压包里面有数据 里有data目录,会造成启动失败

参考链接:
https://www.cnblogs.com/startlearn/p/10007435.html
https://freexyz.cn/dev/76618.html
https://blog.csdn.net/MCmango/article/details/114022493?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_baidulandingword-0&spm=1001.2101.3001.4242
https://www.cnblogs.com/zhujiqian/p/11593671.html
https://www.cnblogs.com/zhyg/p/6994314.html
https://blog.csdn.net/xxkalychen/article/details/107949619
elasticsearch集群管理工具head插件多种安装方式参考
搭建es集群