内存知识梳理 4. 内存管理
前言
Linux利用x86的分段和分页机制将逻辑地址转换为物理地址。除了内核保留一部分空间存放代码和数据以外,剩余空间需要动态管理,给内核和进程使用。本讲讲述内存管理方法。
本讲包含三个方面的内容:
首先物理内存是内存管理的基础,要解决如何对其有效管理的问题,因此第一部分讲述页框管理。包括页框的概念、节点和管理区的概念、内核如何申请若干个页框、CPU内如何保障快速申请一个页框、如何用伙伴系统解决申请页框的碎片问题。高端内存如何映射到线性地址上(永久和临时映射)。
然后是高端内存管理的三种机制:永久内核映射、临时内核映射和非连续内存区管理。
最后内核如何处理以字节为单位的内存请求?这是第三部分内存区管理的内容。主要讲述slab分配器。
页框管理
硬件上具有不同的物理内存大小和内存结构,例如有的PC机有8GB内存,有的只有1GB,有的体系结构上不同地址区间的内存访问快慢不同。如何对其进行有效管理,这就是本节的内容。
页框
Linux以页框为单位管理内存。将物理内存按照4KB的大小(在32位系统,未开启PAE时)划分页框。
内核对每个物理页都用一个描述符来表示,系统在初始化期间根据物理内存大小建立一个描述符结构体数组mem_map,作为物理页面的仓库,每个结构都代表一个页框。描述符结构体如下:
==================== include/linux/mm_types.h 34 103 ====================
27 /*
28 * Each physical page in the system has a struct page associated with
29 * it to keep track of whatever it is we are using the page for at the
30 * moment. Note that we have no way to track which tasks are using
31 * a page, though if it is a pagecache page, rmap structures can tell us
32 * who is mapping it.
33 */
34 struct page {
35 unsigned long flags; /* Atomic flags, some possibly
36 * updated asynchronously */
37 atomic_t _count; /* Usage count, see below. */
38 union {
39 atomic_t _mapcount; /* Count of ptes mapped in mms,
40 * to show when page is mapped
41 * & limit reverse map searches.
42 */
43 struct { /* SLUB */
44 u16 inuse;
45 u16 objects;
46 };
47 };
48 union {
49 struct {
50 unsigned long private; /* Mapping-private opaque data:
51 * usually used for buffer_heads
52 * if PagePrivate set; used for
53 * swp_entry_t if PageSwapCache;
54 * indicates order in the buddy
55 * system if PG_buddy is set.
56 */
57 struct address_space *mapping; /* If low bit clear, points to
58 * inode address_space, or NULL.
59 * If page mapped as anonymous
60 * memory, low bit is set, and
61 * it points to anon_vma object:
62 * see PAGE_MAPPING_ANON below.
63 */
64 };
65 #if USE_SPLIT_PTLOCKS
66 spinlock_t ptl;
67 #endif
68 struct kmem_cache *slab; /* SLUB: Pointer to slab */
69 struct page *first_page; /* Compound tail pages */
70 };
71 union {
72 pgoff_t index; /* Our offset within mapping. */
73 void *freelist; /* SLUB: freelist req. slab lock */
74 };
75 struct list_head lru; /* Pageout list, eg. active_list
76 * protected by zone->lru_lock !
77 */
78 /*
79 * On machines where all RAM is mapped into kernel address space,
80 * we can simply calculate the virtual address. On machines with
81 * highmem some memory is mapped into kernel virtual memory
82 * dynamically, so we need a place to store that address.
83 * Note that this field could be 16 bits on x86 ... ;)
84 *
85 * Architectures with slow multiplication can define
86 * WANT_PAGE_VIRTUAL in asm/page.h
87 */
88 #if defined(WANT_PAGE_VIRTUAL)
89 void *virtual; /* Kernel virtual address (NULL if
90 not kmapped, ie. highmem) */
91 #endif /* WANT_PAGE_VIRTUAL */
92 #ifdef CONFIG_WANT_PAGE_DEBUG_FLAGS
93 unsigned long debug_flags; /* Use atomic bitops on this */
94 #endif
95
96 #ifdef CONFIG_KMEMCHECK
97 /*
98 * kmemcheck wants to track the status of each byte in a page; this
99 * is a pointer to such a status block. NULL if not tracked.
100 */
101 void *shadow;
102 #endif
103 };描述符中几个关键字段分别为:
_count(count):
页引用计数,如果该字段为-1表示相应页框空闲,可以分配给任意进程或内核本身;如果该字段大于等于0,则说明页框分配给了一个或多个进程,或用于存放一些内核数据结构。page_count()函数返回_count加1后的值,也就是该页的使用者数目。
flags:
包含32个状态标志PG_xyz。对于每个标志内核都有一些操作宏如PageXyz/SetPageXyz/ClearPageXyz。
==================== include/linux/page-flags.h 75 131 ====================
75 enum pageflags {
76 PG_locked, /* Page is locked. Don't touch. */
77 PG_error,
78 PG_referenced,
79 PG_uptodate,
80 PG_dirty,
81 PG_lru,
82 PG_active,
83 PG_slab,
84 PG_owner_priv_1, /* Owner use. If pagecache, fs may use*/
85 PG_arch_1,
86 PG_reserved,
87 PG_private, /* If pagecache, has fs-private data */
88 PG_private_2, /* If pagecache, has fs aux data */
89 PG_writeback, /* Page is under writeback */
90 #ifdef CONFIG_PAGEFLAGS_EXTENDED
91 PG_head, /* A head page */
92 PG_tail, /* A tail page */
93 #else
94 PG_compound, /* A compound page */
95 #endif
96 PG_swapcache, /* Swap page: swp_entry_t in private */
97 PG_mappedtodisk, /* Has blocks allocated on-disk */
98 PG_reclaim, /* To be reclaimed asap */
99 PG_buddy, /* Page is free, on buddy lists */
100 PG_swapbacked, /* Page is backed by RAM/swap */
101 PG_unevictable, /* Page is "unevictable" */
102 #ifdef CONFIG_MMU
103 PG_mlocked, /* Page is vma mlocked */
104 #endif
105 #ifdef CONFIG_ARCH_USES_PG_UNCACHED
106 PG_uncached, /* Page has been mapped as uncached */
107 #endif
108 #ifdef CONFIG_MEMORY_FAILURE
109 PG_hwpoison, /* hardware poisoned page. Don't touch */
110 #endif
111 __NR_PAGEFLAGS,
112
113 /* Filesystems */
114 PG_checked = PG_owner_priv_1,
115
116 /* Two page bits are conscripted by FS-Cache to maintain local caching
117 * state. These bits are set on pages belonging to the netfs's inodes
118 * when those inodes are being locally cached.
119 */
120 PG_fscache = PG_private_2, /* page backed by cache */
121
122 /* XEN */
123 PG_pinned = PG_owner_priv_1,
124 PG_savepinned = PG_dirty,
125
126 /* SLOB */
127 PG_slob_free = PG_private,
128
129 /* SLUB */
130 PG_slub_frozen = PG_active,
131 };结构体数组为
==================== mm/memory.c 73 73 ====================
73 struct page *mem_map;在alloc_node_mem_map()函数中分配空间并初始化。
数组的每个元素是一个page结构体,其下标代表页框的序号,这样通过物理地址可以计算出页框号,从mem_map数组中得到页框结构体。反过来用page结构体可以计算出页框号,从而得到页框物理地址范围。页描述符与页框之间的转换用如下宏完成:
==================== include/asm-generic/memory_model.h 30 32 ====================
30 #define __pfn_to_page(pfn) (mem_map + ((pfn) - ARCH_PFN_OFFSET))
31 #define __page_to_pfn(page) ((unsigned long)((page) - mem_map) + \
32 ARCH_PFN_OFFSET)
节点
某些体系结构中内存并非是一块均匀、平坦的区域,而是分成多个不同的节点node,节点内给定CPU对其访问时间相同(不考虑Cache等),节点间访问时间不同。这些物理上的差别促使内核将其区分对待,小心地选择最常引用的内核数据结构的存放位置。描述节点的结构体为:
==================== include/linux/mmzone.h 79 90 ====================
79 typedef struct pglist_data {
80 zone_t node_zones[MAX_NR_ZONES];
81 zonelist_t node_zonelists[NR_GFPINDEX];
82 struct page *node_mem_map;
83 unsigned long *valid_addr_bitmap;
84 struct bootmem_data *bdata;
85 unsigned long node_start_paddr;
86 unsigned long node_start_mapnr;
87 unsigned long node_size;
88 int node_id;
89 struct pglist_data *node_next;
90 } pg_data_t;多个这样的结构体连接成单向链表,描述了整个内存。其链表头元素由pgdat_list变量指向。
IBM兼容PC使用一致访问内存(UMA)模型,因此不存在这个非一致问题,但是为了保持通用性,Linux对x86也使用一样的管理模式,只是整个系统只存在一个节点,此时pgdat_list变量指向的链表只有一个元素,即节点0描述符,存放在contig_page_data变量中。
管理区
理想的计算机体系结构中页框的使用没有什么限制。但是硬件实际是存在制约,例如在x86平台上:
- ISA总线的DMA只能寻址RAM的前16MB
- 在具有大容量RAM的现代32位操作系统,CPU不能直接访问所有的物理内存,因为线性地址空间太小。
为此Linux将每个节点又分为3个管理区(Zone),分别为ZONE_DMA、ZONE_NORMAL和ZONE_HIGHMEM,其中有些体系上不全有这些管理区。
每个管理区用一个结构体描述:
==================== include/linux/mmzone.h 38 421 ====================
38 #define MIGRATE_UNMOVABLE 0
39 #define MIGRATE_RECLAIMABLE 1
40 #define MIGRATE_MOVABLE 2
41 #define MIGRATE_PCPTYPES 3 /* the number of types on the pcp lists */
42 #define MIGRATE_RESERVE 3
43 #define MIGRATE_ISOLATE 4 /* can't allocate from here */
44 #define MIGRATE_TYPES 5
57 struct free_area {
58 struct list_head free_list[MIGRATE_TYPES];
59 unsigned long nr_free;
60 };
282 struct zone {
286 unsigned long watermark[NR_WMARK];
293 unsigned long percpu_drift_mark;
303 unsigned long lowmem_reserve[MAX_NR_ZONES];
304
305 #ifdef CONFIG_NUMA
306 int node;
307 /*
308 * zone reclaim becomes active if more unmapped pages exist.
309 */
310 unsigned long min_unmapped_pages;
311 unsigned long min_slab_pages;
312 #endif
313 struct per_cpu_pageset __percpu *pageset;
317 spinlock_t lock;
318 int all_unreclaimable; /* All pages pinned */
319 #ifdef CONFIG_MEMORY_HOTPLUG
320 /* see spanned/present_pages for more description */
321 seqlock_t span_seqlock;
322 #endif
323 struct free_area free_area[MAX_ORDER];
324
325 #ifndef CONFIG_SPARSEMEM
330 unsigned long *pageblock_flags;
331 #endif /* CONFIG_SPARSEMEM */
332
333 #ifdef CONFIG_COMPACTION
339 unsigned int compact_considered;
340 unsigned int compact_defer_shift;
341 #endif
342
343 ZONE_PADDING(_pad1_)
344
345 /* Fields commonly accessed by the page reclaim scanner */
346 spinlock_t lru_lock;
347 struct zone_lru {
348 struct list_head list;
349 } lru[NR_LRU_LISTS];
350
351 struct zone_reclaim_stat reclaim_stat;
352
353 unsigned long pages_scanned; /* since last reclaim */
354 unsigned long flags; /* zone flags, see below */
355
356 /* Zone statistics */
357 atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
358
363 unsigned int inactive_ratio;
364
365
366 ZONE_PADDING(_pad2_)
368
393 wait_queue_head_t * wait_table;
394 unsigned long wait_table_hash_nr_entries;
395 unsigned long wait_table_bits;
396
400 struct pglist_data *zone_pgdat;
401 /* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */
402 unsigned long zone_start_pfn;
403
414 unsigned long spanned_pages; /* total size, including holes */
415 unsigned long present_pages; /* amount of memory (excluding holes) */
416
420 const char *name;
421 } ____cacheline_internodealigned_in_smp;结构体虽然很大,但每个节点最多只有三个这样的结构体。
free_area_t结构体用于描述一个连续内存区,MAX_ORDER是11,用法在后续的伙伴系统再介绍。
struct per_cpu_pageset __percpu *pageset用于每CPU页框高速缓存,后续介绍。
zone_start_pfn是管理区第一个页框的下标。
spanned_pages是包括洞的管理区总页数,present_pages是不包括洞的管理区总页数。
name是管理区名称:DMA、NORMAL或HighMem
其他的很多字段用于回收页框,相关内容今后再描述。
给定一个页描述符,如何确定其在哪个节点?每个页描述符都有到内存节点和管理区的链接,如果在内核编译时没有定义NODE_NOT_IN_PAGE_FLAGS宏,则在flag标志的高若干位存储节点和管理区号。用page_zone()函数返回该值。
当内核调用一个内存分配函数时,必须指明请求页框所在的管理区。内核通常指明它愿意使用哪个管理区。下一个小节描述。
请求和释放页框
当有内存分配请求时,如果有足够空闲内存可用,则请求就会被立刻满足,否则要回收一些内存,并且阻塞请求进程。
但是有些情况下,内核控制路径不能被阻塞——如中断或临界区内。这时需要使用原子分配请求GFP_ATOMIC,稍后讲述请求标志。
保留页框池
为了减少原子请求分配失败情况,内核保留了一个页框池,只有在内存不足时候才使用。
插入:事先分配和推迟分配。内核为了效率会做出两种决策:有时候有先见之明,在请求发生之前先处理,有时候又对请求尽量推迟。前者如预留原子请求保留池;后者如写时复制、文件系统缓冲、进程空间请求、修改高端地址的页表项等。写时复制在第四讲进程管理中描述,文件系统缓冲在文件系统一讲中描述,最后两种情况将在下一讲进程地址空间中讨论。
回到保留池上,保留内存的数量以KB计,存储在min_free_kbytes变量中,初始化过程中设置,取决于直接映射到内核线性地址空间第4个GB的物理内存的数量。
==================== mm/page_alloc.c 4976 5015 ====================
4976/*
4977 * Initialise min_free_kbytes.
4978 *
4979 * For small machines we want it small (128k min). For large machines
4980 * we want it large (64MB max). But it is not linear, because network
4981 * bandwidth does not increase linearly with machine size. We use
4982 *
4983 * min_free_kbytes = 4 * sqrt(lowmem_kbytes), for better accuracy:
4984 * min_free_kbytes = sqrt(lowmem_kbytes * 16)
4985 *
4986 * which yields
4987 *
4988 * 16MB: 512k
4989 * 32MB: 724k
4990 * 64MB: 1024k
4991 * 128MB: 1448k
4992 * 256MB: 2048k
4993 * 512MB: 2896k
4994 * 1024MB: 4096k
4995 * 2048MB: 5792k
4996 * 4096MB: 8192k
4997 * 8192MB: 11584k
4998 * 16384MB: 16384k
4999 */
5000static int __init init_per_zone_wmark_min(void)
5001{
5002 unsigned long lowmem_kbytes;
5003
5004 lowmem_kbytes = nr_free_buffer_pages() * (PAGE_SIZE >> 10);
5005
5006 min_free_kbytes = int_sqrt(lowmem_kbytes * 16);
5007 if (min_free_kbytes < 128)
5008 min_free_kbytes = 128;
5009 if (min_free_kbytes > 65536)
5010 min_free_kbytes = 65536;
5011 setup_per_zone_wmarks();
5012 setup_per_zone_lowmem_reserve();
5013 setup_per_zone_inactive_ratio();
5014 return 0;
5015}系统运行时该值可以更改,通过写入/proc/sys/vm/min_free_kbytes文件或发出一个适当的sysctl()系统调用来更改其值。
管理区描述符中的pages_min字段存储了管理区内保留页框的数目,该字段与page_low、page_high一起在页框回收算法中起作用。
分配和释放页框函数
有一个分区页框分配器(zoned page frame allocator)的内核子系统处理对连续页框组的分配请求。

其中“管理区分配器”部分接收动态内存分配与释放请求,它搜索一个能满足要求的一组连续页框内存管理区,详细情况后述。在每个管理区内,页框被名为“伙伴系统”的部分来处理。为了达到更好的系统性能,一小部分页框保留在高速缓存中,用于满足对单个页框的分配请求——见后面的“每CPU页框高速缓存”。
可以通过6个稍有差别的宏请求页框,一般它们返回第一个所分配页的线性地址,如果分配失败,返回NULL。
alloc_pages(gfp_mask, order)
请求2^order个连续页框,它返回第一个分配页框描述符的地址
alloc_pages(gfp_mask)
请求一个单独的页框,相当于上个宏中order=0
__get_free_page(gfp_mask, order)
类似于第一个宏,但返回值是第一个所分配页的线性地址
__get_free_page(gfp_mask)
上个宏中order=0
get_zerod_page(gfp_mask)
获取填满0的页框,相当于第一个宏的gfp_mask增加了一个__GFP_ZERO标志。
__get_dma_pages(gfp_mask, order)
获得用于DMA的页框,相当于第一个宏的gfp_mask增加了一个__GFP_DMA标志.
此外还有一个函数使得返回页的内容全为零:
get_zeroed_page(gfp_mask)
它与__get_free_page(gfp_mask)的工作方式相同,只不过把分配好的页全都填充成了0,当分配的页用于用户空间时,这个函数非常有用,可以防止内核数据泄露。
可见第一个宏是基础,我们一会儿分析,现在先看gfp_mask参数。
这个参数可以使用的标志有很多个,分为三类:行为修饰符、区修饰符和类型修饰符,其中类型修饰符是前两类的组合。Linux内核只使用类型修饰符作为gfp_mask值。
GFP_ATOMIC __GFP_HIGH
GFP_NOIO __GFP_WAIT
GFP_NOFS __GFP_WAIT | __GFP_IO
GFP_KERNEL __GFP_WAIT | __GFP_IO | __GFP_FS
GFP_USER __GFP_WAIT | __GFP_IO | __GFP_FS
GFP_HIGHUSER __GFP_WAIT | __GFP_IO | __GFP_FS | __GFP_HIGHMEM最常用的标志是GFP_KERNEL,这种分配可能引起睡眠,它使用的是普通优先级。因为调用可能阻塞,因此只用在可以重新安全调度的进程上下文中——即不持有锁等情况。它对内核如何获取请求内存没有任何约束,因此成功的可能性很高。
另一个截然相反的标志是GFP_ATOMIC,因为其不能睡眠,因此在内存紧缺时失败的可能性较大。但是在中断处理程序、软中断和tasklet中也只能选择GFP_ATOMIC。
GFP_NOIO可能会阻塞,但它避免启动磁盘I/O;GFP_NOFS也可能会引起阻塞,可能会启动磁盘I/O,但它不会启动文件系统I/O。他们分别用在某些低级块I/O或文件系统的代码中。例如,假设在文件系统代码中需要分配内存,但是没有使用GFP_NOFS,则分配可能引起更多的文件系统操作,而这些操作有可能导致另外的分配,从而一直持续下去不能成功。
__GFP_DMA和__GFP_HIGHMEM标志称为管理区修饰符,它们标识分配时所搜索的内存区,如果__GPF_DMA被置位,则只能从ZONE_DMA内存管理区获取页框。否则如果__GFP_HIGHMEM标志没有置位,只能按照优先次序从ZONE_NORMAL和ZONE_DMA内存管理区获取。否则可以按优先次序从ZONE_HIGHMEM、ZONE_NORMAL和ZONE_DMA内存管理区获得页框。
释放可以使用4个宏之一:
__free_pages(page, order)
free_pages(addr, order)
__free_page(page)
free_page(addr)伙伴系统算法
当需要一组连续页框时,存在著名的外碎片问题。如何避免外碎片?本质上有两种方法:
- 避开问题:利用分页单元把一组非连续的空闲页框映射到连续的线性地址空间。
- 迎难而上:开发一种技术记录现存的空闲连续页框,以尽量避免为满足为满足小块内存的请求而分割大的空闲块。
Linux内核使用第二种方法,原因有三:
一是有些情况下确实需要连续的页框,不能用映射到连续线性地址上的方法解决。例如DMA访问时候。
二是频繁修改映射需要修改页表,而修改页表势必导致TLB频繁刷新,从而导致访问内存平均时间增加。
三是内核用一个页的页表可以访问4MB的页,减少了TLB的失效率,提高访问内存的平均速度。
为此,内核准备了一种健壮、高效的分配策略,即伙伴系统(buddy system)。
伙伴系统
伙伴系统把所有空闲页框分为11个块链表,每个块链表分别包含大小为1,2,4,…512和1024个连续的页框,对每个1024个页框的最大请求对应着4MB的连续RAM块。每个块的第一个页框地址时该块大小的整数倍。

用一个例子来说明伙伴系统的请求和释放的工作原理。释放过程是伙伴系统的得名由来。
Linux2.6中,每个管理区有不同的伙伴系统。例如在x86中有三种伙伴系统:DMA使用的页框、常规页框和高端内存页框。
每个伙伴系统的主要数据结构有mem_map数组、包含11个free_area元素的数组。在上述代码中有叙述,回顾。其中free_area数组的第k个元素标示所有大小为2^k的空闲块,其中free_list字段是双向循环链表的头,这个链表包含每个空闲页框块的起始页框的页描述符,然后每个描述符的lru字段将其后续的页描述符串联起来。此外nr_free指定了大小为2^k页的空闲块的个数。
最后,每个2^k的空闲页块的第一个页的描述符的private字段存放了块的order,即数字k,正因为这样,释放时候内核可以确定这个块的伙伴是否也空闲。
随后在管理区分配器小节会遇到一些具体代码,就包含了一部分伙伴系统的算法源码,这里不再分析。在这里出现了链表。我们插入一段对Linux链表实现的介绍。
链表
Linux内核大量使用了链表,因此形成了结构化的定义和使用方法。
链表一般分为单链表和双链表及多链表。我们只涉及双链表。例如我们定义一个结构体并用链表连接起来,一般是在里面嵌入一个链表指针:
struct fox{
unsigned long tail_length;
unsigned long weight;
bool is_fantastic;
struct fox *next;
struct fox *prev;
};前后指针的类型因元素类型而异,这样很难统一实现。为此Linux用一种不同的方式实现了链表,即不是把数据结构塞入链表,而是把链表塞入数据结构。链表元素为:
==================== include/linux/types.h 216 218 ====================
struct list_head {
struct list_head *next, *prev;
};当将其放入数据结构时,变成了:
struct fox{
unsigned long tail_length;
unsigned long weight;
bool is_fantastic;
struct list_head list;
};看起来没什么区别,但实际上原来的链表操作中,数据类型是struct fox*,每种链表都不同。而现在变成了list_head类型,所有链表都相同,这样就可以用统一的代码操作,不再需要自行定义操作函数了。
再仔细分析,原来的前后指针指向的是一个结构体的首部,而现在链表们指向的都是链表元素,用下图表示:
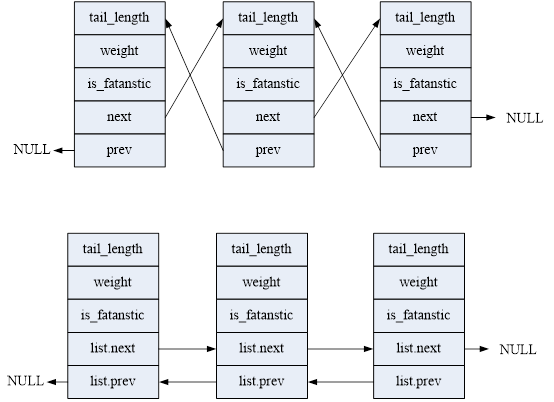
当需要寻址一个父结构体的变量时,利用编译器固定的变量偏移,可以从子结构体导出父结构体的地址。Linux使用list_entry来获取,它需要利用container_of()宏:
==================== include/linux/kernel.h 526 535 ====================
/**
* container_of - cast a member of a structure out to the containing structure
* @ptr: the pointer to the member.
* @type: the type of the container struct this is embedded in.
* @member: the name of the member within the struct.
*
*/
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );})==================== include/linux/list.h 338 345 ====================
/**
* list_entry - get the struct for this entry
* @ptr: the &struct list_head pointer.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_struct within the struct.
*/
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)如上所见,list_head本身并不包含数据,只有在被嵌入到自己定义的数据结构中才有意义。链表需要在使用前初始化,可以使用函数:
==================== include/linux/list.h 24 25 ====================
static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list;
list->prev = list;
}一般我们都需要定义一个链表头来指向整个链表,在Linux中这个特殊的链表头实际上也是一个list_head:
==================== include/linux/list.h 19 22 ====================
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)链表的操作有增加节点、删除节点、移动节点、连接链表、遍历链表、反向遍历等等,这些操作包括其他一些几乎能想到的所有链表操作方法都在list.h中找到,还有一个链表的排序可以在list_sort.h中找到。
每CPU页框高速缓存
内核经常请求和释放单个页框,为了提升性能,每个内存管理区定义了一个每CPU页框高速缓存,包含一些预分配的页框。
热高速缓存和冷高速缓存:如果刚分配后就向页框写,则从热高速缓存中获取页框;反之如果页框被DMA操作,则使用冷高速缓存有利。
实现每CPU页框高速缓存的主要数据结构是存放在内存管理区描述符的pageset字段中的一个per_cpu_pageset数组数据结构。该数组包含为每个CPU提供的一个元素,这个元素依次由两个per_cpu_pages描述符组成,一个给热高速缓存,另一个留给冷高速缓存。
==================== include/linux/mmzone.h 180 189 ====================
180 struct per_cpu_pageset {
181 struct per_cpu_pages pcp;
182 #ifdef CONFIG_NUMA
183 s8 expire;
184 #endif
185 #ifdef CONFIG_SMP
186 s8 stat_threshold;
187 s8 vm_stat_diff[NR_VM_ZONE_STAT_ITEMS];
188 #endif
189 };==================== include/linux/mmzone.h 171 178 ====================
171 struct per_cpu_pages {
172 int count; /* number of pages in the list */
173 int high; /* high watermark, emptying needed */
174 int batch; /* chunk size for buddy add/remove */
175
176 /* Lists of pages, one per migrate type stored on the pcp-lists */
177 struct list_head lists[MIGRATE_PCPTYPES];
178 };count是高速缓存中的页框个数,high为上界,表示高速缓存用尽,batch是在告诉缓存中将要添加或被删去的页框个数,list是高速缓存中包含的页框描述符链表。
内核用low和high监视高速缓存和冷高速缓存的大小。
使用每CPU页框高速缓存分配和释放页框
buffered_rmqueue()函数在指定的内存管理区中分配页框,它使用每CPU页框高速缓存来处理单一页框请求。
使用free_hot_page()和free_cold_page()函数释放页框到每CPU页框高速缓存,它们都是free_hot_cold_page()的封装,接收参数是将要释放的页框的描述符地址page和cold标志。
管理区分配器
如图,管理区分配器位于最上层,直接处理内存管理请求。它需要实现以下功能:
保护保留的页框池——见前;当内存不足且允许阻塞当前进程时候,应当触发页框回收算法,一旦某些页框被释放,再次尝试分配;如果可能,需要保存小而珍贵的ZONE_DMA。
如前所述,对一组连续页框的每次请求都是通过alloc_pages宏处理的。源码:
==================== mm/numa.c 43 43 ====================
43 #ifdef CONFIG_DISCONTIGMEM
==================== mm/numa.c 91 128 ====================
91 /*
92 * This can be refined. Currently, tries to do round robin, instead
93 * should do concentratic circle search, starting from current node.
94 */
95 struct page * alloc_pages(int gfp_mask, unsigned long order)
96 {
97 struct page *ret = 0;
98 pg_data_t *start, *temp;
99 #ifndef CONFIG_NUMA
100 unsigned long flags;
101 static pg_data_t *next = 0;
102 #endif
103
104 if (order >= MAX_ORDER)
105 return NULL;
106 #ifdef CONFIG_NUMA
107 temp = NODE_DATA(numa_node_id());
108 #else
109 spin_lock_irqsave(&node_lock, flags);
110 if (!next) next = pgdat_list;
111 temp = next;
112 next = next->node_next;
113 spin_unlock_irqrestore(&node_lock, flags);
114 #endif
115 start = temp;
116 while (temp) {
117 if ((ret = alloc_pages_pgdat(temp, gfp_mask, order)))
118 return(ret);
119 temp = temp->node_next;
120 }
121 temp = pgdat_list;
122 while (temp != start) {
123 if ((ret = alloc_pages_pgdat(temp, gfp_mask, order)))
124 return(ret);
125 temp = temp->node_next;
126 }
127 return(0);
128 }它扫描所有节点,调用alloc_pages_pgdat()分配,直至分配成功或全部失败。
==================== mm/numa.c 85 89 ====================
85 static struct page * alloc_pages_pgdat(pg_data_t *pgdat, int gfp_mask,
86 unsigned long order)
87 {
88 return __alloc_pages(pgdat->node_zonelists + gfp_mask, order);
89 }可见gfp_mask用作node_zonelists[]数组的下标,决定具体的分配策略。真正的分配发生在__alloc_pages(),它是管理区分配器的核心。
==================== mm/page_alloc.c 270 315 ====================
[alloc_pages()>__alloc_pages()]
270 /*
271 * This is the 'heart' of the zoned buddy allocator:
272 */
273 struct page * __alloc_pages(zonelist_t *zonelist, unsigned long order)
274 {
275 zone_t **zone;
276 int direct_reclaim = 0;
277 unsigned int gfp_mask = zonelist->gfp_mask;
278 struct page * page;
279
280 /*
281 * Allocations put pressure on the VM subsystem.
282 */
283 memory_pressure++;
284
285 /*
286 * (If anyone calls gfp from interrupts nonatomically then it
287 * will sooner or later tripped up by a schedule().)
288 *
289 * We are falling back to lowerlevel zones if allocation
290 * in a higher zone fails.
291 */
292
293 /*
294 * Can we take pages directly from the inactive_clean
295 * list?
296 */
297 if (order == 0 && (gfp_mask & __GFP_WAIT) &&
298 !(current->flags & PF_MEMALLOC))
299 direct_reclaim = 1;
300
301 /*
302 * If we are about to get low on free pages and we also have
303 * an inactive page shortage, wake up kswapd.
304 */
305 if (inactive_shortage() -> inactive_target / 2 && free_shortage())
306 wakeup_kswapd(0);
307 /*
308 * If we are about to get low on free pages and cleaning
309 * the inactive_dirty pages would fix the situation,
310 * wake up bdflush.
311 */
312 else if (free_shortage() && nr_inactive_dirty_pages-> free_shortage()
313 && nr_inactive_dirty_pages->= freepages.high)
314 wakeup_bdflush(0);
315在这个函数中标记内存管理的压力值,还有可能唤醒kswapd和bdflush两个内核线程,之后将页框回收时候再讲述。继续往下看。
==================== mm/page_alloc.c 316 340 ====================
[alloc_pages()>__alloc_pages()]
316 try_again:
317 /*
318 * First, see if we have any zones with lots of free memory.
319 *
320 * We allocate free memory first because it doesn't contain
321 * any data ... DUH!
322 */
323 zone = zonelist->zones;
324 for (;;) {
325 zone_t *z = *(zone++);
326 if (!z)
327 break;
328 if (!z->size)
329 BUG();
330
331 if (z->free_pages >= z->pages_low) {
332 page = rmqueue(z, order);
333 if (page)
334 return page;
335 } else if (z->free_pages < z->pages_min &&
336 waitqueue_active(&kreclaimd_wait)) {
337 wake_up_interruptible(&kreclaimd_wait);
338 }
339 }
340最后依次考察每个管理区中的空闲页面情况,如果不足则唤醒回收过程,如果足够就调用rmqueue()从中分配。(2.6内核中这个函数是__rmqueue)
==================== mm/page_alloc.c 989 1013 ====================
989 static struct page *__rmqueue(struct zone *zone, unsigned int order,
990 int migratetype)
991 {
992 struct page *page;
993
994 retry_reserve:
995 page = __rmqueue_smallest(zone, order, migratetype);
996
997 if (unlikely(!page) && migratetype != MIGRATE_RESERVE) {
998 page = __rmqueue_fallback(zone, order, migratetype);
999
1000 /*
1001 * Use MIGRATE_RESERVE rather than fail an allocation. goto
1002 * is used because __rmqueue_smallest is an inline function
1003 * and we want just one call site
1004 */
1005 if (!page) {
1006 migratetype = MIGRATE_RESERVE;
1007 goto retry_reserve;
1008 }
1009 }
1010
1011 trace_mm_page_alloc_zone_locked(page, order, migratetype);
1012 return page;
1013 }__rmqueue()用来在管理区中用伙伴系统算法找到一个空闲块。它从所请求的order的链表开始,调用__rmqueue_smallest先在恰好满足大小要求的队列中分配,如果不行就尝试更大的队列。997行的unlikely是一个编译加速控制宏。
==================== mm/page_alloc.c 796 820 ====================
796 static inline
797 struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,
798 int migratetype)
799 {
800 unsigned int current_order;
801 struct free_area * area;
802 struct page *page;
803
804 /* Find a page of the appropriate size in the preferred list */
805 for (current_order = order; current_order < MAX_ORDER; ++current_order) {
806 area = &(zone->free_area[current_order]);
807 if (list_empty(&area->free_list[migratetype]))
808 continue;
809
810 page = list_entry(area->free_list[migratetype].next,
811 struct page, lru);
812 list_del(&page->lru);
813 rmv_page_order(page);
814 area->nr_free--;
815 expand(zone, page, order, current_order, area, migratetype);
816 return page;
817 }
818
819 return NULL;
820 }如果在__rmqueue_smallest中如果找到了合适的空闲块,从链表中删除它的第一个页框描述符,并减少nr_free的值,根据需要修正链表。
==================== mm/page_alloc.c 735 750 ====================
735 static inline void expand(struct zone *zone, struct page *page,
736 int low, int high, struct free_area *area,
737 int migratetype)
738 {
739 unsigned long size = 1 << high;
740
741 while (high > low) {
742 area--;
743 high--;
744 size >>= 1;
745 VM_BUG_ON(bad_range(zone, &page[size]));
746 list_add(&page[size].lru, &area->free_list[migratetype]);
747 area->nr_free++;
748 set_page_order(&page[size], high);
749 }
750 }这里的while循环原理如下:当在大块中分配一个小块时,要把分配到的大块中剩余的部分分解成小块链入相应的队列。low对应于表示所需物理块大小的order,而high表示分配到的物理块的current_order。若两者相符,则不需要调整,否则拆分后链入更低一档的空闲块队列。这样直到high与low相等时循环结束。
在2.6.37代码中又加入了migratetype这一个属性。这里不再做进一步分析。
回过去__alloc_pages(),如果给定分配策略中所有页面管理区都失败了,那就只好“加大力度”再试,一是降低对页面管理区中保持“水位”的要求,二是把缓冲在管理区中的“不活跃干净页面”页考虑进去。
==================== mm/page_alloc.c 341 364 ====================
[alloc_pages()>__alloc_pages()]
341 /*
342 * Try to allocate a page from a zone with a HIGH
343 * amount of free + inactive_clean pages.
344 *
345 * If there is a lot of activity, inactive_target
346 * will be high and we'll have a good chance of
347 * finding a page using the HIGH limit.
348 */
349 page = __alloc_pages_limit(zonelist, order, PAGES_HIGH, direct_reclaim);
350 if (page)
351 return page;
352
353 /*
354 * Then try to allocate a page from a zone with more
355 * than zone->pages_low free + inactive_clean pages.
356 *
357 * When the working set is very large and VM activity
358 * is low, we're most likely to have our allocation
359 * succeed here.
360 */
361 page = __alloc_pages_limit(zonelist, order, PAGES_LOW, direct_reclaim);
362 if (page)
363 return page;
364先用参数PAGES_HIGH调用__alloc_pages_limit(),如果不行就再用PAGES_LOW调用。__alloc_pages_limit()会调整水位,然后再调用rmqueue()。这里不分析其源码。
如果这次分配还是失败,则根据策略有可能唤醒内核线程kswapd,让它设法换出一些页面,或者让系统调度后有可能其他进程释放出一些页面。再次切换回本进程时,用参数PAGE_MIN再调用一次__alloc_pages_limit()。
依然失败呢?这时候根据是谁在申请页面有不同策略。如果是普通进程,则通过回收inactive_clean_pages队列中的页面尝试。如果是kswapd或kreclaimd,本身就是内存分配工作者,则这个请求更重要,这时转回到try_again处。前面一次次加大力度调用__alloc_pages_limit()时,实际上还有所保留,这是为了应付紧急情况。现在紧急情况出现了,到了不惜血本的时候。重新再来一次就可以成功。如果再失败,则一定是系统有问题,打印错误信息。
==================== mm/page_alloc.c 519 519 ====================
519 printk(KERN_ERR "__alloc_pages: %lu-order allocation failed.\n", order);回顾一下__alloc_pages()函数的执行过程:
- 执行对内存管理区的第一次扫描,第一次扫描中,阈值min设置为z->pages_low,其中z指向正在被分析的管理区描述符。
- 如果在上一步没有终止,那么没有剩下多少空闲内存:唤醒kswapd内核线程异步回收页框。
- 执行对内存管理区的第二次扫描,将z->pages_min作为阈值base传递。这一步与第1步相似,但是用了较低的阈值。
- 如果函数在上一步没有终止,那么系统肯定内存不足。如果产生内存分配请求的内核控制路径不是一个中断处理程序或一个可延迟函数,并且它试图回收页框,那么函数随即执行对内存管理区的第三次扫描,试图分配页框并且忽略内存不足的阈值。只有这种情况下才允许内核控制路径耗用为内存不足预留的页。其实,这种情况下产生内存请求的内核控制路径最终将试图释放页框,因此只要有可能它就应当得到它所请求的。如果没有任何内存管理区包含足够的页框,函数就返回NULL提示调用者发生了错误。
- 这里,正调用的内核控制路径并没有试图回收内存。如果 gfp_mask的__GFP_WAIT标志没有置位,则函数返回NULL提示内核控制路径内存分配失败:这时如果不阻塞当前进程就没办法满足请求。
- 这里当前进程能够被阻塞:调用
cond_resched()检查是否有其他的进程需要CPU。 - 设置current的PF_MEMALLOC标志来表示进程已经准备好执行内存回收。
- 将一个指向reclaim_state数据结构的指针存入current->reclaim_state,这个数据结构只包含一个字段reclaimed_slab,被初始化为0。
- 调用
try_to_free_pages()寻找一些页框来回收。后一个函数可能阻塞当前进程。一旦函数返回,__alloc_pages()就重设current的PF_MEMALLOC标志并再次调用cond_resched()。 - 如果上一步已经释放了一些页框,那么该函数还要执行一次与第3步相同的内存管理区扫描。如果内存分配不能被满足,那么函数决定是否应当继续扫描内存管理区:如果是__GFP_NORETRY标志清除,并且内存分配请求跨越了多达8个页框,或__GFP_REPEAT和__GFPNOFAIL标志其中之一被置位,那么函数就调用
blk_congestion_wait()使进程休眠一会儿,并且回到第6步。否则,返回NULL提示调用者内存分配失败。 - 如果第9步中没有释放任何页框,就意味着内核遇到很大麻烦,因为空闲页框已经少到危险的地步,并且不可能回收任何页框。也许到了该作出重要决定的时候了。如果允许内核控制路径执行依赖于文件系统的操作来杀死一个进程(__GFP_FS置位)并且__GFP_NORETRY标志为0,那么执行如下子步骤:
a.使用等于z->pages_high的阈值再一次扫描内存管理区。
b.调用out_of_memory()杀死一个进程释放一些内存。
c.返回第1步。
从中可以发现,分配一个内存页面是一件十分艰苦卓绝的工作。事实上,绝大多数的工作都在分配策略决定的第一个页管理区中就成功了。设计的这么复杂是为了缓存足够多的资源以提高运行效率,只有在系统内存极其紧张时候才会一级一级动用战略储备资源。
本节我们没有仔细分析页面的换出、换入和定期换出等机制。以后将用单独一讲来描述。
高端内存页框的内核映射
高端内存不能直接映射到第4个GB线性空间中,因此调用__get_free_pages(GFP_HIGHMEM, 0)在高端内存分配一个页框后不能返回它的线性地址,因为它根本不存在。因此当分配高端内存时候,只能使用alloc_pages()和alloc_page(),它们不返回线性地址,而是返回第一个被分配页框的页描述符的线性地址。而页描述符在初始化阶段分配,且永远可以访问。
没有线性地址的高端内存中的页框不能被内核访问,因此内核线性地址的最后128MB中的一部分专门用来映射高端内存页框,通过不同时间使用相同的线性地址,可以重复利用小的线性地址空间映射较大的高端内存。映射机制有三种:永久映射、临时映射及非连续内存分配。
建立永久映射会阻塞当前进程,因此不能用于中断处理程序和可延迟函数。而临时映射不会阻塞,但是能建立的映射少。这些技术没有一个可以保证对整个RAM空间同时寻址,因为毕竟只有128MB线性地址空间可用。
永久内核映射
永久表示长期。它们使用主内核页表中一个专门的页表,其地址存放在pkmap_page_table变量中。
============= mm/highmem.c 74 74 ====================
74 pte_t * pkmap_page_table;页表中的页表项由LAST_PKMAP宏产生,包含1024项(PAE激活时是512项),因此一次最多可以访问4MB的高端内存。该页表映射的线性地址从PKMAP_BASE开始,该值在内核中定义为
============= arch/x86/include/asm/pgtable_32_types.h 40 41 ====================
40 #define PKMAP_BASE ((FIXADDR_BOOT_START - PAGE_SIZE * (LAST_PKMAP + 1)) \
41 & PMD_MASK)
pkmap_count数组包含LAST_PKMAP个计数器,pkmap_page_table页表中的每一项都有一个。
计数器为0表示对应的页表项没有映射任何高端内存页框,并且是可用的。
计数器为1表示对应的页表项没有映射任何高端内存页框,但是不能使用。因为自从最后一次使用以来,相应的TLB表项还没有被刷新。
计数器为n(远大于1)相应的表项映射一个高端内存页框,有n-1个内核成分在使用这个页框。
为了记录高端内存页框与永久内核映射包含的线性地址之间的联系,内核使用了page_address_htable散列表。该表包含一个page_address_map数据结构,用于为高端内存中的每一个页框进行当前映射。而该数据结构还包含一个指向页描述符的指针和分配给该页框的线性地址。

==================== mm/highmem.c 304 313 ====================
304 #define PA_HASH_ORDER 7
305
306 /*
307 * Describes one page->virtual association
308 */
309 struct page_address_map {
310 struct page *page;
311 void *virtual;
312 struct list_head list;
313 };==================== mm/highmem.c 321 327 ====================
321 /*
322 * Hash table bucket
323 */
324 static struct page_address_slot {
325 struct list_head lh; /* List of page_address_maps */
326 spinlock_t lock; /* Protect this bucket's list */
327 } ____cacheline_aligned_in_smp page_address_htable[1<如果需要直到一个页框的线性地址,调用page_address()函数。
==================== mm/highmem.c 334 365 ====================
334 /**
335 * page_address - get the mapped virtual address of a page
336 * @page: &struct page to get the virtual address of
337 *
338 * Returns the page's virtual address.
339 */
340 void *page_address(struct page *page)
341 {
342 unsigned long flags;
343 void *ret;
344 struct page_address_slot *pas;
345
346 if (!PageHighMem(page))
347 return lowmem_page_address(page);
348
349 pas = page_slot(page);
350 ret = NULL;
351 spin_lock_irqsave(&pas->lock, flags);
352 if (!list_empty(&pas->lh)) {
353 struct page_address_map *pam;
354
355 list_for_each_entry(pam, &pas->lh, list) {
356 if (pam->page == page) {
357 ret = pam->virtual;
358 goto done;
359 }
360 }
361 }
362 done:
363 spin_unlock_irqrestore(&pas->lock, flags);
364 return ret;
365 }如果页框不在高端内存中,直接通过lowmem_page_address()函数计算其地址。否则如果在高端内存中则该函数在page_address_htable散列表中查找,如果找到则返回,否则返回NULL。
如果该函数没有找到线性地址,则需要映射,使用kmap()建立永久内核映射。
==================== arch/x86/mm/highmem_32.c 5 11 ====================
5 void *kmap(struct page *page)
6 {
7 might_sleep();
8 if (!PageHighMem(page))
9 return page_address(page);
10 return kmap_high(page);
11 }如果页框在高端内存中,调用kmap_high()建立映射。
==================== mm/highmem.c 198 222 ====================
198 /**
199 * kmap_high - map a highmem page into memory
200 * @page: &struct page to map
201 *
202 * Returns the page's virtual memory address.
203 *
204 * We cannot call this from interrupts, as it may block.
205 */
206 void *kmap_high(struct page *page)
207 {
208 unsigned long vaddr;
209
210 /*
211 * For highmem pages, we can't trust "virtual" until
212 * after we have the lock.
213 */
214 lock_kmap();
215 vaddr = (unsigned long)page_address(page);
216 if (!vaddr)
217 vaddr = map_new_virtual(page);
218 pkmap_count[PKMAP_NR(vaddr)]++;
219 BUG_ON(pkmap_count[PKMAP_NR(vaddr)] < 2);
220 unlock_kmap();
221 return (void*) vaddr;
222 }这个函数获取kmap_lock自旋锁,以保护页表免受多处理器系统上的并发访问。这里不需要禁止中断,因为中断处理程序和可延迟函数不能调用kmap()。接下来如果页框没有映射,则调用map_new_virtual()函数新建映射。然后kmap_high()使页框的线性地址所对应的计数器加1。最后释放自旋锁并返回对该页框进行映射的线性地址。
==================== mm/highmem.c 148 196 ====================
148 static inline unsigned long map_new_virtual(struct page *page)
149 {
150 unsigned long vaddr;
151 int count;
152
153 start:
154 count = LAST_PKMAP;
155 /* Find an empty entry */
156 for (;;) {
157 last_pkmap_nr = (last_pkmap_nr + 1) & LAST_PKMAP_MASK;
158 if (!last_pkmap_nr) {
159 flush_all_zero_pkmaps();
160 count = LAST_PKMAP;
161 }
162 if (!pkmap_count[last_pkmap_nr])
163 break; /* Found a usable entry */
164 if (--count)
165 continue;
166
167 /*
168 * Sleep for somebody else to unmap their entries
169 */
170 {
171 DECLARE_WAITQUEUE(wait, current);
172
173 __set_current_state(TASK_UNINTERRUPTIBLE);
174 add_wait_queue(&pkmap_map_wait, &wait);
175 unlock_kmap();
176 schedule();
177 remove_wait_queue(&pkmap_map_wait, &wait);
178 lock_kmap();
179
180 /* Somebody else might have mapped it while we slept */
181 if (page_address(page))
182 return (unsigned long)page_address(page);
183
184 /* Re-start */
185 goto start;
186 }
187 }
188 vaddr = PKMAP_ADDR(last_pkmap_nr);
189 set_pte_at(&init_mm, vaddr,
190 &(pkmap_page_table[last_pkmap_nr]), mk_pte(page, kmap_prot));
191
192 pkmap_count[last_pkmap_nr] = 1;
193 set_page_address(page, (void *)vaddr);
194
195 return vaddr;
196 }map_new_virtual()函数遍历pkmap_count计数器,如果找到空值,则把页框的物理地址插入到kmap_page_table的一个项中,将pkmap_count对应项置1,调用set_page_address()函数在page_address_htable散列表中加入一个元素,并返回线性地址。
函数通过将上次使用过的页表项的索引保存在last_pkmap_nr的变量中做了加速。每次搜索都从上次停止的lask_pkmap_nr处开始递减。这种类似做法在下一讲中还会遇到。
如果第一遍找到最后在pkmap_count中没有找到空的计数器,将调用flush_all_zero_pkmaps()函数遍历pkmap_count寻找计数器为1的值,因为1代表空闲但TLB未刷新,这时将其计数器重置为0,删除page_address_htable散列表中对应元素,并在pkmap_page_table的所有项上进行TLB刷新。
结束flush_all_zero_pkmaps()函数后,map_new_virtual()重新遍历。如果仍然没有找到空闲的,则将当前进程current插入到pkmap_map_wait等待队列,表示这个进程需要映射,然后调用schedule()阻塞当前进程发起一次调度。一旦被唤醒,先调用page_address()检查是否在睡眠期间有其他进程已经映射了该页,如果还没有映射,则重新开始循环。
撤销映射使用kunmap()函数。同样如果页框在高端内存中,调用kunmap_high()函数。
==================== arch/x86/include/asm/highmem.h 54 54 ====================
54 #define PKMAP_NR(virt) ((virt-PKMAP_BASE) >> PAGE_SHIFT)==================== mm/highmem.c 252 297 ====================
252 /**
253 * kunmap_high - map a highmem page into memory
254 * @page: &struct page to unmap
255 *
256 * If ARCH_NEEDS_KMAP_HIGH_GET is not defined then this may be called
257 * only from user context.
258 */
259 void kunmap_high(struct page *page)
260 {
261 unsigned long vaddr;
262 unsigned long nr;
263 unsigned long flags;
264 int need_wakeup;
265
266 lock_kmap_any(flags);
267 vaddr = (unsigned long)page_address(page);
268 BUG_ON(!vaddr);
269 nr = PKMAP_NR(vaddr);
270
271 /*
272 * A count must never go down to zero
273 * without a TLB flush!
274 */
275 need_wakeup = 0;
276 switch (--pkmap_count[nr]) {
277 case 0:
278 BUG();
279 case 1:
280 /*
281 * Avoid an unnecessary wake_up() function call.
282 * The common case is pkmap_count[] == 1, but
283 * no waiters.
284 * The tasks queued in the wait-queue are guarded
285 * by both the lock in the wait-queue-head and by
286 * the kmap_lock. As the kmap_lock is held here,
287 * no need for the wait-queue-head's lock. Simply
288 * test if the queue is empty.
289 */
290 need_wakeup = waitqueue_active(&pkmap_map_wait);
291 }
292 unlock_kmap_any(flags);
293
294 /* do wake-up, if needed, race-free outside of the spin lock */
295 if (need_wakeup)
296 wake_up(&pkmap_map_wait);
297 }它从页框的线性地址计算出pkmap_count数组的索引,计数器减1并与1相比,如果匹配成功则表明没有进程在使用该页。由于释放了一个线性地址,该函数还唤醒等待队列,让其他在map_ner_virtual()中睡眠的进程醒来进行映射。
临时内核映射
临时内核映射比永久映射要简单,可以用在中断处理程序和可延迟程序的内部,因为他们从不阻塞当前进程。
内核保留一个页表项,称为“窗口”,高端内存的任一页框可以通过“窗口”映射到内核地址空间。内核的窗口数很少。每个CPU都有自己的几个窗口,用enum km_type数据结构表示。
==================== include/asm-generic/kmap_types.h 10 36 ====================
10 enum km_type {
11 KMAP_D(0) KM_BOUNCE_READ,
12 KMAP_D(1) KM_SKB_SUNRPC_DATA,
13 KMAP_D(2) KM_SKB_DATA_SOFTIRQ,
14 KMAP_D(3) KM_USER0,
15 KMAP_D(4) KM_USER1,
16 KMAP_D(5) KM_BIO_SRC_IRQ,
17 KMAP_D(6) KM_BIO_DST_IRQ,
18 KMAP_D(7) KM_PTE0,
19 KMAP_D(8) KM_PTE1,
20 KMAP_D(9) KM_IRQ0,
21 KMAP_D(10) KM_IRQ1,
22 KMAP_D(11) KM_SOFTIRQ0,
23 KMAP_D(12) KM_SOFTIRQ1,
24 KMAP_D(13) KM_SYNC_ICACHE,
25 KMAP_D(14) KM_SYNC_DCACHE,
26 /* UML specific, for copy_*_user - used in do_op_one_page */
27 KMAP_D(15) KM_UML_USERCOPY,
28 KMAP_D(16) KM_IRQ_PTE,
29 KMAP_D(17) KM_NMI,
30 KMAP_D(18) KM_NMI_PTE,
31 KMAP_D(19) KM_KDB,
32 /*
33 * Remember to update debug_kmap_atomic() when adding new kmap types!
34 */
35 KMAP_D(20) KM_TYPE_NR
36 };该结构中的每个符号,如KM_BOUNCE_READ表示了窗口的线性地址。每个窗口不能被两个不同的控制路径同时使用,否则后续映射不能成功,因此km_type结构中每个符号都只能由一种内核成分使用,并以该成分命名。最后一个符号KM_TYPE_NR只表示个数。
在上一讲的固定内存映射中有一个枚举fixed_addresses,其中有两个值FIX_KMAP_BEGIN和FIX_KMAP_END = FIX_KMAP_BEGIN+(KM_TYPE_NR*NR_CPUS)-1,这里就相当于插入了多个km_type的枚举值。因此每个CPU都有KM_TYPE_NR个固定映射的线性地址。所以临时内核映射是固定映射中的一种。
建立临时内核映射使用kmap_atomic()函数,它调用kmap_atomic_prot():
==================== arch/x86/mm/highmem_32.c 32 50 ====================
32 void *kmap_atomic_prot(struct page *page, pgprot_t prot)
33 {
34 unsigned long vaddr;
35 int idx, type;
36
37 /* even !CONFIG_PREEMPT needs this, for in_atomic in do_page_fault */
38 pagefault_disable();
39
40 if (!PageHighMem(page))
41 return page_address(page);
42
43 type = kmap_atomic_idx_push();
44 idx = type + KM_TYPE_NR*smp_processor_id();
45 vaddr = __fix_to_virt(FIX_KMAP_BEGIN + idx);
46 BUG_ON(!pte_none(*(kmap_pte-idx)));
47 set_pte(kmap_pte-idx, mk_pte(page, prot));
48
49 return (void *)vaddr;
50 }参数type和CPU的ID计算出一个固定映射的线性地址,然后就可以用__fix_to_virt()计算出线性地址来,填入页表中。
撤销临时内核映射使用kunmap_atomic()函数。
非连续内存区管理
前面讲的都是把一个内存区映射到一组连续的页框,这样可以充分利用高速缓存。
当内存区的请求不是很频繁时候,通过连续线性地址访问非连续页框将很有意义,这样可以避免外碎片,但缺点是打乱内核页表。当为活动的交换区分配数据结构、为模块分配空间、或给某些I/O驱动程序分配缓冲区时,需要使用非连续内存区管理。非连续内存区管理可以将一些不连续的物理内存页面组合起来映射到连续的线性地址空间上。
内核线性地址空间
我们先来看一下内核线性地址空间的使用情况。从PAGE_OFFSET开始是对前896MB物理内存的映射,其末尾对应的线性地址在变量high_memory中。
内存的结尾部分是固定映射的线性地址。FIXADDR_START宏由该区域的末端地址减去区域长度决定,其中末端地址是0xfffff000。
从PKMAP_BASE开始的一段空间是永久内核映射。其起始地址是一个页目录项地址对齐(二级映射时),长度是1个页表可以映射的长度(未开启PAE时是4MB)。与固定映射的线性地址中间有至少4KB的空隙。
其余的空间用于非连续内存区。起始处与物理内存映射的末尾有8MB的安全区,目的是捕获对内存的越界访问。同样每个vmalloc区域间都有一定长度的安全区。

每个非连续内存区都对应一个描述符:
==================== include/linux/vmalloc.h 26 35 ====================
26 struct vm_struct {
27 struct vm_struct *next;
28 void *addr;
29 unsigned long size;
30 unsigned long flags;
31 struct page **pages;
32 unsigned int nr_pages;
33 phys_addr_t phys_addr;
34 void *caller;
35 };addr是内存区第一个内存单元的线性地址。
size是内存区的大小加安全区大小4096。
flags是一些内存类型:VM_ALLOC表示用vmalloc()得到的页,VM_MAP表示使用vmap()映射的已经被分配的页,而VM_IOREMAP表示使用ioremap()映射的硬件设备的板上内存。
pages为指向nr_pages数组的指针。该数组由指向页描述符的指针组成。nr_pages是内存区页个数。
next指向下一个vm_struct结构。phys_addr字段设置为0,除非内存已被创建来映射一个硬件设备的I/O共享内存。
这些描述符通过next字段组成一个链表,链表首元素的地址在vmlist变量中,还定义了一个vmlist_lock变量用作自旋锁。
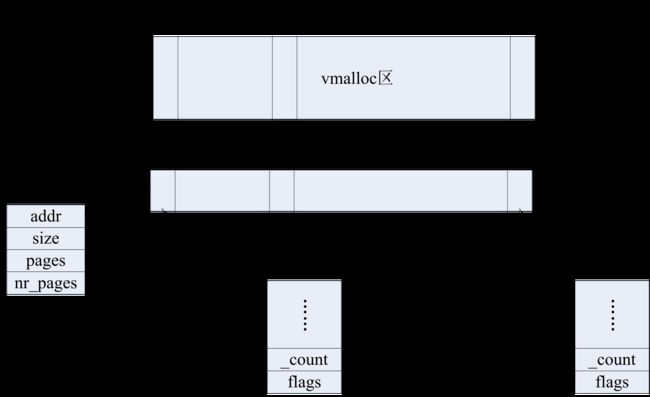
分配非连续内存区
使用vmalloc()函数给内核分配非连续内存区。
函数先将size设置为4096的整数倍,然后调用get_vm_area()创建一个新的描述符,并从线性地址空间中找到一块可以容纳本次分配长度的vmalloc区域,返回其线性地址。
然后vmalloc()函数调用kmalloc()函数请求一组连续页框,这组连续页框足够包含一个页描述符指针数组pages[]。调用memset()将这些指针设置为NULL。接着重复调用alloc_page()函数,每次分配一个页框,将页框描述符地址依次填入nr_pages中。最后就要修改页表了,这在map_vm_area()中实现。这里不分析其源码,直接给出其主要步骤。
由于这段线性地址可能是跨页目录项的,所以首先要循环分配页上级目录并将其地址写入页全局目录(在三级映射情况下),然后为每个页上级目录分配相关页表并填入每个页上级目录项。最后循环填写每个页表项。填写过程中通过pages[]数组得到页描述符,用set_pte和mk_pte宏把页框的物理地址写入页表中。
注意,map_vm_area()并不触及当前进程的页表。因此,当内核态的进程访问非连续内存区时,该内存区所对应的进程页表中的表项为空,缺页发生,缺页处理程序要检查缺页线性地址是否在住内核页表中,一旦发现主内核页表中有这个线性地址的非空项,就把它拷贝进相应的进程页表项中,并恢复进程的正常执行。这在下一讲的缺页异常处理程序中讲述。
除了vmalloc()外,非连续内存区还可以用vmalloc_32()函数分配,该函数只从ZONE_NOMAL和ZONE_DMA内存管理区中分配页框。
还有一个vmap()函数,当已经存在pages[]数组时候,它用来将其映射到非连续内存区中,它与vmalloc()相似,但是不分配页框。
释放非连续内存区
vfree()函数释放vmalloc()或vmalloc_32()创建的非连续内存区,而vunmap()释放vmap()创建的内存区。它们都依赖__vunmap()函数做实质工作。
它调用remove_vm_area()函数通过扫描vmlist找到vm_struct描述符的地址,清除非连续内存区中的线性地址对应的内核的页表项,但不回收页表。
根据参数,遍历pages[]并调用__free_page()释放页框到分区页框分配器。用kfree()释放数组本身。最后用kfree()释放vm_struct描述符。
与vmalloc()一样,在清除页表项时,内核只修改主内核页全局目录和子页表项,映射第4个GB的进程页表项保持不变。假如一个内核态的进程要访问一个释放的非连续内存区,则访问到的页表项全部为空,触发缺页异常。但是缺页处理程序认为这个访问是错误,因为主内核也表中不包含有效表项。
内存区管理
上一节讲述的都是以页框为单位的内存管理,当需要请求具有连续物理地址的任意长度的内存单元时,内核如何处理?这种场景经常带来另一个著名问题内碎片。
事实上,内核经常需要使用一些缓冲区,例如建立一个新的进程时候需要增加一个task_struct结构,而撤销进程时候需要释放该结构。这是一种频繁的动态申请和释放过程。
早期Linux采用一种典型方法,即按照2的幂次提供内存区,这样可以保证内存碎片小于50%,为此内核建立13个几何分布的空闲内存区链表,从32字节到131072字节。也在伙伴系统中处理。但是伙伴算法之上运行内存区分配算法效率不够高。
例如每次分配的数据需要初始化,内核中频繁使用的一些数据结构并非简单地清零。如果释放数据结构在下次可以重用,那么就可以提高内核效率。
其次在有高速缓存的情况下,如果每次分配的数据结构都在不同的页面中,将造成缓存命中率的下降,从而拖慢速度。
最后,这种方案不适合多处理器共用内存的情况。
这个问题长久以来都是一个热门研究课题,在90年代前期,Sun公司的Solaris2.4操作系统上采用了一种称为slab的缓冲区分配和管理方法,在相当程度上克服了上述问题。后来Linux也采用slab分配器模式,并做了改进。本节主要讲述slab分配器。
Slab的基本思想是为每种重要的数据结构分别建立专用的缓冲区队列,当申请这种数据结构时,从其队列中取出一个,当释放时返回队列。将数据结构元素称为“对象”。每种数据结构都有相应的“构造”和“析构”函数,各个对象在建立时用构造函数初始化。对象个数是动态变化的,不够时可以增添。同时又定期检查,将富余的队列加以精简。定期检查和处理在kswapd中完成,将来再详细描述。
另外,slab管理方法中每种对象的缓冲区队列并非由各个对象直接构成,而是一连串的“大块(slab)”构成,而每个大块都包含了若干个对象。一个slab可能由2^N(0<=N<=5)个连续物理页面构成,具体大小因对象大小而异,在初始化时候通过计算得到最合适的大小。
Slab最顶层称为一个高速缓存,包含一种特定对象。
每个slab的有一个描述结构slab:
==================== mm/slab.c 193 207 ====================
/*
* struct slab
*
* Manages the objs in a slab. Placed either at the beginning of mem allocated
* for a slab, or allocated from an general cache.
* Slabs are chained into three list: fully used, partial, fully free slabs.
*/
struct slab {
struct list_head list;
unsigned long colouroff;
void *s_mem; /* including colour offset */
unsigned int inuse; /* num of objs active in slab */
kmem_bufctl_t free;
unsigned short nodeid;
};
一般而言,对象分为大对象和小对象两种。大小是相对一个页面而言的。大对象的slab描述符放在slab外部,小slab的描述符放在slab内部,位于分配给slab的第一个页框的起始位置。图中只显示了外部slab的情况。
用于同一种对象的多个slab分为三个双向链表,分别通过描述符中的list前后指针相连:第一个是各个slab上所有对象都已分配使用的;第二个是各个slab上的对象已经部分地分配使用的;最后一个是各个slab上的全部对象都处于空闲状态。三个链表的首指针在一个kmem_list3结构体中存储,该结构体又被kmem_cache结构体中一个元素所指向。
每个slab都有一个对象区,这是个对象数据结构的数组,以对象的序号为下标就可以得到具体对象的起始地址。数组起始地址在s_mem中存储。
每个对象都有一个kmem_bufctl_t类型的描述符,所有对象描述符都存放在一个数组中,数组中第一个对象描述符描述slab中的第一个对象,依次类推。
对象描述符被定义为一个无符号整型值,它只在对象空闲时才有意义。当对象空闲时,描述符包含了下一个空闲对象在slab中的下标,这样就构成了一个简单链表。链表第一个空闲对象用slab描述符中的free字段表示。空闲对象链表中最后一个元素的对象描述符用常量BUFCTL_END标记。数据组位于slab描述符之后。因此也存在外部和内部之分。
==================== mm/slab.c 187 188 ====================
typedef unsigned int kmem_bufctl_t;
#define BUFCTL_END (((kmem_bufctl_t)(~0U))-0)在slab描述结构中还有一个已分配使用的对象的计数器inuse。
当释放一个对象时,只要调整链接数据组中的相应元素以及slab描述结构中的计数器,并且根据该slab的使用情况而调整其所在的slab队列。例如,如果slab上所有对象都已经分配使用,就要将该slab从部分使用队列转到全部使用队列中去。
每个slab头还有一个小区域是不使用的,称为着色区,大小为colouroff,是为了使slab中每个对象的起始地址都对齐到缓冲行上。每个slab都是从一个页边界开始的,所以本来就应该是对齐的,而着色区只是为了将第一个对象的起始地址往后推到另一个与缓冲行对齐的边界。同一个对象的缓冲队列中的各个slab的着色区大小尽可能安排成不同的大小,使得不同slab上同一相对位置的对象的起始地址在调整缓存中互相错开,这样可以改善缓存的效率。
每个slab上最后一个对象以后还有一个小小的废料区是不用的。这是对着色区大小的补偿。其大小取决于着色区的大小以及slab与其对象的相对大小。但该区域与着色区的总和对于同一种对象的各个slab是一个常数。
每个对象的大小基本上都是所需要数据结构的大小,但当数据结构大小不与高速缓冲行对齐时,才增加若干字节使其对齐。所以一个slab上所有对象的起始地址都必然是按高速缓存中的缓冲行对齐的。
每种对象建立的slab队列都有个队列头,其结构为kmem_cache。该结构中除了有用来维持slab队列的各种指引外,还记录了适用于队列中每个slab的各种参数,以及一个函数指针:构造函数(在代码中未找到析构函数)。
==================== include/linux/slab_def.h 46 125 ====================
/*
* struct kmem_cache
*
* manages a cache.
*/
struct kmem_cache {
/* 1) per-cpu data, touched during every alloc/free */
struct array_cache *array[NR_CPUS];
/* 2) Cache tunables. Protected by cache_chain_mutex */
unsigned int batchcount;
unsigned int limit;
unsigned int shared;
unsigned int buffer_size;
u32 reciprocal_buffer_size;
/* 3) touched by every alloc & free from the backend */
unsigned int flags; /* constant flags */
unsigned int num; /* # of objs per slab */
/* 4) cache_grow/shrink */
/* order of pgs per slab (2^n) */
unsigned int gfporder;
/* force GFP flags, e.g. GFP_DMA */
gfp_t gfpflags;
size_t colour; /* cache colouring range */
unsigned int colour_off; /* colour offset */
struct kmem_cache *slabp_cache;
unsigned int slab_size;
unsigned int dflags; /* dynamic flags */
/* constructor func */
void (*ctor)(void *obj);
/* 5) cache creation/removal */
const char *name;
struct list_head next;
/* 6) statistics */
#ifdef CONFIG_DEBUG_SLAB
unsigned long num_active;
unsigned long num_allocations;
unsigned long high_mark;
unsigned long grown;
unsigned long reaped;
unsigned long errors;
unsigned long max_freeable;
unsigned long node_allocs;
unsigned long node_frees;
unsigned long node_overflow;
atomic_t allochit;
atomic_t allocmiss;
atomic_t freehit;
atomic_t freemiss;
/*
* If debugging is enabled, then the allocator can add additional
* fields and/or padding to every object. buffer_size contains the total
* object size including these internal fields, the following two
* variables contain the offset to the user object and its size.
*/
int obj_offset;
int obj_size;
#endif /* CONFIG_DEBUG_SLAB */
/*
* We put nodelists[] at the end of kmem_cache, because we want to size
* this array to nr_node_ids slots instead of MAX_NUMNODES
* (see kmem_cache_init())
* We still use [MAX_NUMNODES] and not [1] or [0] because cache_cache
* is statically defined, so we reserve the max number of nodes.
*/
struct kmem_list3 *nodelists[MAX_NUMNODES];
/*
* Do not add fields after nodelists[]
*/
};像其他数据结构一样,每种对象的slab队列头也是在slab上。系统中有个总的slab队列,其对象是其他对象的slab队列头,其队列头也是一个kmem_cache结构,称为cache_cache。这就组成了一种层次式的树形结构。
==================== mm/slab.c 572 579 ====================
/* internal cache of cache description objs */
static struct kmem_cache cache_cache = {
.batchcount = 1,
.limit = BOOT_CPUCACHE_ENTRIES,
.shared = 1,
.buffer_size = sizeof(struct kmem_cache),
.name = "kmem_cache",
};其初始化在kmem_cache_init()函数中。
==================== mm/slab.c 1431 1539 ====================
/*
* Initialisation. Called after the page allocator have been initialised and
* before smp_init().
*/
void __init kmem_cache_init(void)
{
size_t left_over;
struct cache_sizes *sizes;
struct cache_names *names;
int i;
int order;
int node;
if (num_possible_nodes() == 1)
use_alien_caches = 0;
for (i = 0; i < NUM_INIT_LISTS; i++) {
kmem_list3_init(&initkmem_list3[i]);
if (i < MAX_NUMNODES)
cache_cache.nodelists[i] = NULL;
}
set_up_list3s(&cache_cache, CACHE_CACHE);
/*
* Fragmentation resistance on low memory - only use bigger
* page orders on machines with more than 32MB of memory.
*/
if (totalram_pages > (32 << 20) >> PAGE_SHIFT)
slab_break_gfp_order = BREAK_GFP_ORDER_HI;
/* Bootstrap is tricky, because several objects are allocated
* from caches that do not exist yet:
* 1) initialize the cache_cache cache: it contains the struct
* kmem_cache structures of all caches, except cache_cache itself:
* cache_cache is statically allocated.
* Initially an __init data area is used for the head array and the
* kmem_list3 structures, it's replaced with a kmalloc allocated
* array at the end of the bootstrap.
* 2) Create the first kmalloc cache.
* The struct kmem_cache for the new cache is allocated normally.
* An __init data area is used for the head array.
* 3) Create the remaining kmalloc caches, with minimally sized
* head arrays.
* 4) Replace the __init data head arrays for cache_cache and the first
* kmalloc cache with kmalloc allocated arrays.
* 5) Replace the __init data for kmem_list3 for cache_cache and
* the other cache's with kmalloc allocated memory.
* 6) Resize the head arrays of the kmalloc caches to their final sizes.
*/
node = numa_mem_id();
/* 1) create the cache_cache */
INIT_LIST_HEAD(&cache_chain);
list_add(&cache_cache.next, &cache_chain);
cache_cache.colour_off = cache_line_size();
cache_cache.array[smp_processor_id()] = &initarray_cache.cache;
cache_cache.nodelists[node] = &initkmem_list3[CACHE_CACHE + node];
/*
* struct kmem_cache size depends on nr_node_ids, which
* can be less than MAX_NUMNODES.
*/
cache_cache.buffer_size = offsetof(struct kmem_cache, nodelists) +
nr_node_ids * sizeof(struct kmem_list3 *);
#if DEBUG
cache_cache.obj_size = cache_cache.buffer_size;
#endif
cache_cache.buffer_size = ALIGN(cache_cache.buffer_size,
cache_line_size());
cache_cache.reciprocal_buffer_size =
reciprocal_value(cache_cache.buffer_size);
for (order = 0; order < MAX_ORDER; order++) {
cache_estimate(order, cache_cache.buffer_size,
cache_line_size(), 0, &left_over, &cache_cache.num);
if (cache_cache.num)
break;
}
BUG_ON(!cache_cache.num);
cache_cache.gfporder = order;
cache_cache.colour = left_over / cache_cache.colour_off;
cache_cache.slab_size = ALIGN(cache_cache.num * sizeof(kmem_bufctl_t) +
sizeof(struct slab), cache_line_size())然后可以反复调用kmem_cache_create()来创建多个所需数据类型的slab队列。当需要分配一个某种数据结构的缓冲区时,就只要调用kmem_cache_alloc()指明是从哪一个队列中分配,而不需要说明缓冲区大小,并且不需要初始化了。例如内核中常用的mm_struct、vm_area_struct、file、dentry、inode等都有自己专用的slab队列,使用时都是利用该函数分配的。
一些不太常用、初始化开销也不大的数据结构不需要使用专用的缓冲区队列,而是合用一个通用的缓冲区。Linux内核中有一个按大小分区,又采用slab方式管理的通用缓冲池,称为slab_cache。它所包含的对象大小最小是32,然后依次是64、128、……直到128KB即32个页面。从中分配和释放缓冲区的函数为:
void *kmalloc(size_t size, int flags);
void kfree(const void *objp);总结与预告
本讲对描述了Linux对物理内存这一重要资源的管理。这是实现内核和进程空间管理的基础。
下一讲将介绍进程地址空间管理,也将揭开第一讲开始处问题的答案。主要内容有:
进程的地址空间、内存描述符、线性区、缺页异常处理函数、创建和删除进程的地址空间、堆的管理。