嵌入式软件面试经典问题
一、进程与线程(不同的系统资源管理方式)
1.区别
进程:资源分配的基本单位,由一个或者多个线程组成
线程:调度器进行调度的基本单位,一个任务
每个进程都有自己独立的内存空间,一个进程可以有多个线程,进程切换开销大
多个线程共享内存,线程切换开销小
一个进程崩溃不影响其他进程
一个线程崩溃影响所处的整个进程
2.多进程,多线程优缺点
从内存占用,数据共享,同步,CPU利用率,创建销毁和切换速度,可靠性,编程调试比较
3.进程和线程的选择
创建和销毁频繁选线程
需要大量计算,切换频繁选线程
安全稳定选进程,需要速度选线程
4.多进程,多线程通讯(同步)方法
进程间:有名管道(进程AB)和无名管道(父子进程),消息队列,信号量,共享内存,套接字
5.进程状态转换
就绪,阻塞,运行
6.父进程,子进程
父进程调用fork()函数后,复制出一个子进程,两个进程拥有相同的代码段、数据段和用户堆栈
一般设置父进程等待子进程执行完毕
7.上下文切换
进程上下文切换:当进程进行切换时,对CPU所有寄存器的值,堆栈中的内容以及进程的执行位置进行保存,以便再次执行时恢复切换前状态
中断上下文:由于中断信号产生,当前进程中断,对当前进程的执行现场进行保存,转而去执行中断程序
二、C/C++
1.new和malloc
malloc和free是C++/C的库函数,需要加头文件stdlib.h;new和delete是C++的关键字,不需要加头文件,需要编译器支持
使用new申请内存,无需指定内存块大小,编译器会根据类型信息自行计算;malloc需要写出所需分配内存大小
new分配成功时返回是对象类型指针,无需进行类型转换;malloc返回void指针(只知道地址,不知道长度),需要强制类型转换为需要的类型
2.1GB内存能malloc(1.2G)
有可能,malloc函数是申请了一块虚拟地址空间与物理内存无关,得到的是虚拟空间中的地址,之后程序运行提供的物理内存由操作系统完成
3.extern"C"作用
使C++代码中能调用C语言编写的代码,使编译器按C语言进行编译
4.strcat,strncat,strcmp,strcpy,memcpy哪些函数会导致内存溢出,如何改进
strcat(char* dest,char* src) src指向的字符串追加到dest指向的字符串的尾部
strncat(char* dest,const char* src,size_t n) n表示要追加的最大字符数
strcmp(char)比较两个字符串的大小,一个字符一个字符按ASCLL码比较
strcpy(char *dest, const char *src) 把 src 所指向的字符串复制到 dest 不安全,不做任何检查,不判断拷贝大小,不判断目的地址内存是否够用
strncpy(dest,src,n)
memcpy(void *dest, void *src, unsigned int n) 可以拷贝任意类型数据,n表示要复制的最大字符数
strcat和strcpy容易造成内存溢出
5.static用法
static修饰局部变量,使其存储再静态区,函数执行完这个局部变量不会被释放(当二次调用其函数时不会再定义)
static修饰全局变量,使其只在本文件有效
static修饰函数,使得函数只在本文件有效
6.const用法
const修饰的数据只可读不可修改
7.volatile作用和用法
防止编译器优化,每次用到这个变量就读取内存地址的值,而不是保存在寄存器的值
使用情景:一些设备的硬件寄存器(如状态寄存器),多线程中共享的变量,中断函数供其他程序访问的变量
8.const常量和#define宏的区别
#define max 1 在预处理阶段进行替换,不分配内存,不进行类型安全检查
const int max=1; 在编译时确定其值,分配内存,进行类型安全检查
9.变量的作用域,生命周期
全局变量:作用于所在文件,其他文件也可外部引用;一直到程序结束
局部变量:作用局限于一个函数,进入作用域时生成,离开时消失
10.sizeof和strlen
sizeof()是个运算符,返回一个uint类型表示所使用操作数占空间的字节大小,编译的时候就出结果
strlen()是一个参数为字符型指针(char const*)函数,返回该字符串的长度,使用时需引用头文件
int main()
{
char *p = "hello";
char arr1 []= "hello";
char arr2[] = { 'h', 'e', 'l', 'l', 'o' };
printf("%d\n", sizeof( p));
//结果4,因为指针变量的所占空间大小仅仅和操作系统位数有关32-4,64-8
printf("%d\n", sizeof(arr1));
//结果6,字符串默认以\0结尾,sizeof()包含\0的计算
printf("%d\n", sizeof(arr2));
//结果为5,因为为字符型表示,并不含有\0(仅仅字符串有\0)
printf("%d\n", strlen( p));
//结果为5,strlen求的是字符串的长度,不包含\0
printf("%d\n", strlen(arr1));
//结果为5,strlen求的是字符串的长度,不包含\0
printf("%d\n", strlen(arr2));
//因为字符型不包含\0,但字符串需要找到\0才可结束,所以在'o'之后继续向后读取直到找到\0,所以是一个随机值
}
11.struct和union内存对齐
内存对齐作用:便于cpu访问内存,节省存储空间
struct对齐:
1、结构体变量的首地址和总大小是结构体中最宽数据类型的整数倍。
2、结构体每个成员相对于结构体首地址的偏移量(offset)都是成员大小的整数倍
将相同类型和大数据成员的放前面的成员放在一起,这样就减少了编译器为了对齐而添加的填充字符。
[^如32位的cpu按4的倍数来寻址,第一个成员为char,第二个为int,第三个为char,分配了12个字节的空间]
如果把两个char放前面,则可以节约4个字节的空间
union对齐:
如int b,char a[9]最大数据成员为char a[9] 则一共分配了12个字节的空间
预编译指令#pragma pack(n),所有成员对齐以n字节为准
attribute(packed)取消对齐
12.inline函数
以空间换时间的做法,省去函数调用和返回带来的开销,以代码复制为代价直接展开运行
适用被多次调用的语句较少,没有循环递归的函数,否则编译器可能会优化
声明和定义放一起,分离会导致链接错误
13.内存分区
栈区:编译器分配,函数返回值,局部变量
堆区:自行分配
全局区/静态区:全局变量,静态变量,常数
代码区:二进制代码 (ROM)
14.32位编译情况下,判断所使用机器大小端方法
大端存储:高位存在低地址,低位存在高地址
小端存储:高位存在高地址,地位存在低地址
判断方法:
联合体先从低地址开始存,同一时间只有一个成员占有内存
#include
int main() {
union w{
int a;
char b;
}c;
c.a=1;
if(c.b==1)
printf("xiaoduan\n");
else
printf("daduan\n");
return 0;
}
int强制转换为char,p指向a的低字节
#include 15.用变量a给出以下定义
一个指向函数的指针,该函数有一个整形参数并返回一个整形数
int (*a)(int)
16.运算符优先级
先算术再移位再关系符
三、网络编程
1.OSI模型
open system interconnection reference model
物理层:定义数据传输介质 如光纤,mac地址
数据链路层:封装数据 如以太网
网络层:路径选择 如IP
传输层:建立端到端的连接 如TCP,UDP
会话层:管理表示层实体之间的会话连接
表示层:数据格式兼容
应用层:提供软件接口 如http,ssh,ftp,smtp
 上图来自https://blog.csdn.net/wwy0324/article/details/109310658?spm=1001.2014.3001.5501
上图来自https://blog.csdn.net/wwy0324/article/details/109310658?spm=1001.2014.3001.5501
2.TCP,UDP
TCP:传输控制协议,面向连接的,可靠的字节流服务
编程复杂 ,可靠(无差错,不丢失,不重复,按顺序)稳定,效率低,占用资源多
传输前建立连接,确认机制,重传机制,拥塞机制,三次握手机制等
适用对信号质量完整性有要求场景,如发邮件
UDP:用户数据报协议,面向无连接的,不可靠的数据报服务
编程简单,效率高,不可靠
无状态传输,容易丢包
适用对质量要求不高,对速度要求快的场景,如视频电话
3.三次握手,四次挥手
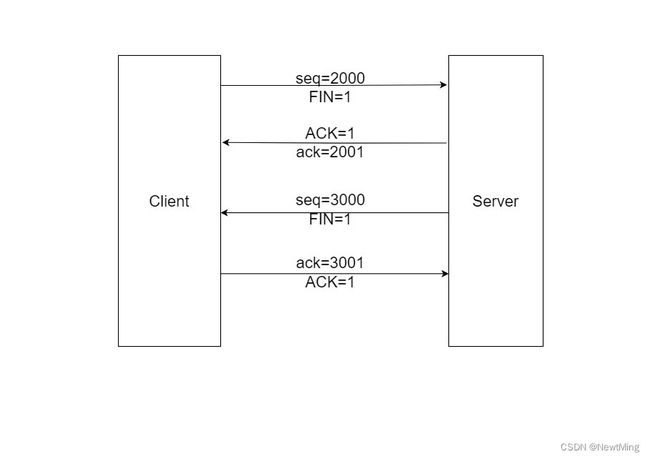
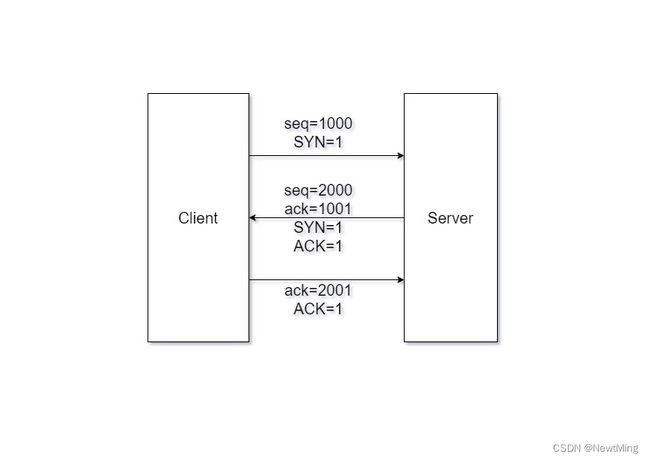
四、常见算法
稳定,不稳定,内排序,外排序,时间复杂度,空间复杂度
冒泡排序:
#include 快速排序:
void QuickSort(int* a, int low, int high)
{
int pos;
if (low < high) {
pos = FindPos(a, low, high);
QuickSort(a, low, pos-1); //第二个参数表示第一个元素的下标,第三个参数表示最后一个元素的下标
QuickSort(a, pos + 1, high);
}
}
int FindPos(int* a, int low, int high)
{
int tmp = a[low];
while (low < high) {
while (low < high &&a[high] >= tmp)
--high;
a[low] = a[high];
while (low < high && a[low] <= tmp)
++low;
a[high] = a[low];
}
a[low] = tmp;//终止while循环之后low和high一定相等
return high;
}
五、Linux操作系统
1.Linux内核
进程调度,内存管理,虚拟文件系统,网络接口,进程间通信
https://blog.csdn.net/jinking01/article/details/104547290?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164717396616780261960950%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=164717396616780261960950&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-104547290.es_vector_control_group&utm_term=linux内核&spm=1018.2226.3001.4187

2.linux系统组成
内核,shell,文件系统,应用程序
https://blog.csdn.net/lilygg/article/details/89309461?ops_request_misc=&request_id=&biz_id=102&utm_term=linux系统组成&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-0-89309461.nonecase&spm=1018.2226.3001.4187
3.用户空间和内核通信方式
- 使用mmap系统调用:可以将内核空间的地址映射到用户空间。
- netlink
- 使用API
- 文件
- 使用proc文件系统
4.系统调用和普通函数调用区别
系统调用:
- 使用INT和RET指令,内核和应用程序使用的是不同的堆栈
- 依赖内核,不保证移植
- 在用户空间和内核上下文环境间切换,开销较大
- 是操作系统的一个入口点
普通函数:
- 使用CALL和RET指令,调用时没有堆栈切换
- 平台移植性好
- 属于过程调用,开销较小
- 一个普通功能函数的调用
5.内核态,用户态
内核态:运行系统程序,特权级为R0最高
用户态:运行用户程序,特权级为R3
6.bootloader,内核,根文件
启动顺序:bootloader->kernel->rootfile->app
启动引导程序用来初始化处理器及外设,调用内核完成系统初始化,挂载某个文件为根文件系统,然后加载必要的内核模块,启动应用程序
7.bootloader启动两个阶段
stage1:
- 基本的硬件初始化(关闭看门口和中断,设置cpu工作频率)
- 为加载stage2准备RAM空间
- 拷贝内核映像和文件系统映像到RAM
- 设置堆栈指针sp
- 跳转到stage2入口
stage2:
- 初始化本阶段要使用的硬件(串口,网卡)
- 检测系统内存映射
- 加载内核映像和文件系统映像
- 设置内核的启动参数
- 调用内核
8.检查内存状态的命令
top
free
cat /proc/meminfo
vmstat
9.程序运行到结束的过程
预处理pre-processing .i
处理源代码中的预处理指令,如进行宏替换,条件编译,引入头文件,还会去除注释,添加行号和文件名标识
编译 compiling .s
把预处理完的文件进行一系列词法分析、语法分析、语义分析,以及优化后,生成相应的汇编代码文件。
汇编 assembling .o
将汇编代码转换成机器可以执行的指令 ,生成目标文件
链接 linking .exe
将各个目标文件整合起来
过程:地址和空间分配,重定位和符号决议
10.堆,栈,内存泄漏,内存溢出
堆:由程序员管理分配
栈:由编译器管理分配
内存泄漏:分配的内存空间使用完后未被回收,直到程序结束。如malloc但未free
内存溢出:要求分配的内存空间超出系统能分配的。因不检查数组边界,不检查类型可靠性
内存越界:使用内存时超出了系统申请的范围。如使用特定的数组越界
11.死锁的原因,产生条件
原因:
资源竞争;进程运行推进的顺序不合适;
产生必要条件:
互斥条件:一个资源每次都只能被一个进程使用
请求与保持条件:一个进程因请求资源而阻塞时,已经获得的资源保持不放
不可抢占条件:进程已获得的资源,在未使用完前不能抢占
循环等待条件:若干进程形成一个头尾相接的循环等待资源的关系
12.硬链接和软链接
为解决文件的共享使用
硬链接:ln 源文件 目标文件,类似于Windows的快捷方式
软连接:ln -s 源文件 目标文件,类似于cp -p加同步更新
源文件:即你要对谁建立链接
13.计算机32bit和64bit
寻址空间更大2^48,支持更大内存,每次能处理的数据更多
可以以64位格式寻址,通用寄存器和运算器宽度是64位,并可以对64位操作数执行运算
14.中断和异常
外中断——就是我们指的中断——是指由于外部设备事件所引起的中断,如通常的磁盘中断、打印机中断等
内中断——就是异常——是指由于 CPU 内部事件所引起的中断,如程序出错(非法指令、地址越界)
异常是由于执行了现行指令所引起的。由于系统调用引起的中断属于异常。
中断则是由于系统中某事件引起的,该事件与现行指令无关。
相同点:都是CPU对系统发生的某个事件做出的一种反应。
15.中断处理流程
请求中断,响应中断,关闭中断,保护断点,中断源识别,保护现场,中断服务程序,恢复现场,开中断,返回
16.挂起,休眠,关机命令
关机:halt,init0,poweroff,shutdown -h 时间
重启:reboot,init 6,shutdown -r 时间
挂起:sudo pm-suspend
休眠:sudo pm-hibernate
17.gcc编译优化
gcc -O
(https://blog.csdn.net/weixin_30517001/article/details/94809515?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164717717916780269881243%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=164717717916780269881243&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduend~default-3-94809515.es_vector_control_group&utm_term=gcc%E7%BC%96%E8%AF%91%E5%91%BD%E4%BB%A4&spm=1018.2226.3001.4187)
18.有数据cache情况下DMA数据链路
外设-DMA-DDR-cache-CPU
DMA(direct memory access)
DDR(DRAM)
19.linux命令
20.硬实时系统,软实时系统
硬实时系统有一个刚性的、不可改变的时间限制,它不允许任何超出时限的错误。超时必返回。Freertos,ucos
软实时系统的时限是一个柔性灵活的,它可以容忍偶然的超时错误。Windows、Linux
21.MMU基础
现代操作系统普遍采用虚拟内存管理机制,这需要MMU内存管理单元的支持,负责虚拟地址映射为物理地址。
有些嵌入式处理器没有MMU则不能运行依赖虚拟内存管理的操作系统
有MMU操作系统:windows,linux,macos,android
无MMU操作系统:freertos,ucMos
带MMUCPU:cortex-A,arm9
无MMUCPU:cortex-M