嵌入式笔试——笔试题目
单选(15题)
第一题

栈简介
栈由操作系统(编译器)自动分配释放 ,用于存放函数的参数值、局部变量等,其操作方式类似于数据结构中的栈。
堆简介
堆由开发人员分配和释放,容易产生内存碎片(不连续的无法利用的地址空间)。 若开发人员不释放,程序结束时由 OS(操作系统) 回收,分配方式类似于链表。
堆与栈区别
堆与栈实际上是操作系统对进程占用的内存空间的两种管理方式,主要有如下几种区别:
(1)管理方式不同。栈由操作系统自动分配释放,无需我们手动控制;堆的申请和释放工作由程序员控制,容易产生内存泄漏;
(2)空间大小不同。每个进程拥有的栈的大小要远远小于堆的大小。理论上,程序员可申请的堆大小为虚拟内存的大小,进程栈的大小 64bits 的 Windows 默认 1MB,64bits 的 Linux 默认 10MB;
(3)生长方向不同。堆的生长方向向上,内存地址由低到高;栈的生长方向向下,内存地址由高到低。
(4)分配方式不同。堆都是动态分配的,没有静态分配的堆。栈有2种分配方式:静态分配和动态分配。静态分配是由操作系统完成的,比如局部变量的分配。动态分配由alloca函数进行分配,但是栈的动态分配和堆是不同的,他的动态分配是由操作系统进行释放,无需我们手工实现。
(5)分配效率不同。栈效率高,堆效率低。 栈由系统自动分配,速度较快。但程序员是无法控制。堆分配的内存速度较慢,不易产生内存碎片栈由操作系统自动分配,会在硬件层级对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。堆则是由C/C++提供的库函数或运算符来完成申请与管理,实现机制较为复杂,频繁的内存申请容易产生内存碎片。显然,堆的效率比栈要低得多。
(6)存放内容不同。
栈存放的内容,函数返回地址、相关参数、局部变量和寄存器内容等。
堆,一般情况堆顶使用一个字节的空间来存放堆的大小,而堆中具体存放内容是由程序员来填充的。
C程序的存储空间是如何分配

1、代码段:
1.1).text
主要存放代码(用户代码)包括main函数在内的所有用户自定义的函数只读并且共享,这段内存在程序运行期间不会被释放。
1.2).init
主要用来存放系统给每个可执行文件自动添加的“初始化代码” ,(eg:环境变量的准备,命令行参数…)。
2、数据段:
2.1).data
主要存放程序的已初始化的全局变量和已初始化的static变量,可读可写,这段内存在程序运行期间不会被释放。
2.2).bss
主要存放程序的未初始化的全局变量和未初始化的static变量,可读可写,这段内存在程序运行期间不会被释放,.bss段 在进程初始化时候 (可能)全部初始化为0。
2.3).rodata
只读数据段,主要存放程序中的只读数据(eg:字符串常量),只读。这段内存在程序运行期间不会被释放。
3、栈空间(Stack)
主要存放局部变量(非static的局部变量),可读可写。这段空间,会自动释放,(代码块执行完毕,代码块中的所有局部变量的空间都会自动释放),随代码块的持续性。
4、堆(heap)空间: 动态内存空间
主要是 malloc,realloc,calloc 动态分配的空间,可读可写,这段内存在程序运行期间,一旦分配就一直存在,直到手动 free 或进程消亡(防止 “内存泄漏” / “垃圾内存”)。
第二题

死锁:
在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁,尽管死锁很少发生,但一旦发生就会造成应用的停止响应。
产生死锁的四个必要条件:
1、互斥条件:一个资源每次只能被一个进程使用。
2、请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
3、不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。
4、循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
预防死锁
1、有序分配锁资源可以预防死锁
2、银行家算法避免死锁(不是检测)
银行家算法是从当前状态出发,逐个按安全序列检查各客户谁能完成其工作,然后假定其完成工作且归还全部贷款,再进而检查下一个能完成工作的客户,…。如果所有客户都能完成工作,则找到一个安全序列,银行家才是安全的。
解除死锁
剥夺死锁进程的所有资源可以解除死锁
第三题
一、顺序结构(顺序存取和随机存取)
优点
1、简单:存储与管理都简单,且容易实现。
2、支持顺序存取和随机存取。
3、顺序存取速度快。
4、所需的磁盘寻道次数和寻道时间最少。
缺点
1、需要为每个文件预留若干物理块以满足文件增长的部分需要。
2、不利于文件插入和删除。
二、链式结构(顺序存取)
优点
1、提高了磁盘空间利用率,不需要为每个文件预留物理块。
2、有利于文件插入和删除。
3、有利于文件动态扩充。
缺点
1、存取速度慢,不适于随机存取。
2、当物理块间的连接指针出错时,数据丢失。
3、更多的寻道次数和寻道时间。
4、链接指针占用一定的空间,降低了空间利用率。
三、索引结构(顺序存取和随机存取)
优点
1、不需要为每个文件预留物理块。
2、既能顺序存取,又能随机存取。
3、满足了文件动态增长、插入删除的要求。
缺点
1、较多的寻道次数和寻道时间。
2、索引表本身带来了系统开销。如:内外存空间,存取时间等
四、hash(哈希)文件(顺序存取和随机存取)
哈希文件中,是使用一个函数(算法)来完成一种将关键字映射到存储器地址的映射,根据用户给出的关键字,经函数计算得到目标地址,再进行目标的检索。
第四题
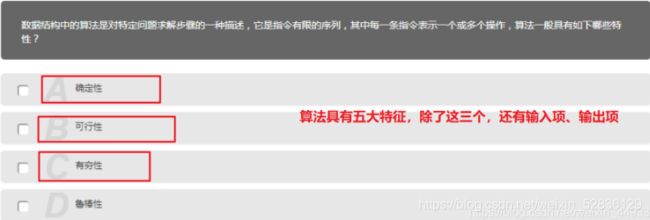
第五题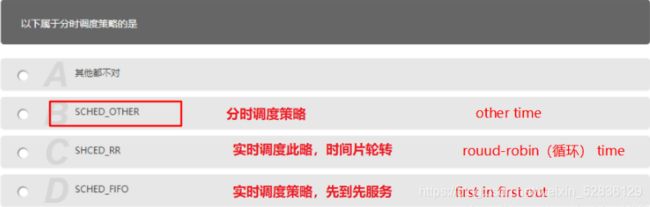
第六题

const的作用:
1、 修饰变量:
C语言中采用const修饰变量,功能是对变量声明为只读特性,并保护变量值以防被修改。举例说明如下:
const int i = 5;
上面这个例子表明,变量i具有只读特性,不能够被更改;若想对i重新赋值,如i = 10;则是错误的。
2、 修饰数组:
C语言中const还可以修饰数组,举例如下:
const int array[5] = {1,2,3,4,5};
array[0] = array[0]+1; //错误
数组元素与变量类似,具有只读属性,不能被更改;一旦更改,如程序将会报错。
3、 修饰指针:
C语言中const修饰指针要特别注意,共有两种形式,一种是用来限定指向空间的值不能修改;另一种是限定指针不可更改。举例说明如下:
int i = 5;
int j = 6;
int k = 7;
const int * p1 = &i; //定义1 即其指向空间的值不可改变
int * const p2 =&j; //定义2 限定的是指针
上面定义了两个指针p1和p2。
在定义1中const限定的是p1,即其指向空间的值不可改变,若改变其指向空间的值如p1=20,则程序会报错;但p1的值是可以改变的,对p1重新赋值如p1=&k是没有任何问题的。
在定义2中const限定的是指针p2,若改变p2的值如p2=&k,程序将会报错;但p2,即其所指向空间的值可以改变,如p2=80是没有问题的,程序正常执行。
4、 修饰函数参数:
const关键字修饰函数参数,对参数起限定作用,防止其在函数内部被修改。所限定的函数参数可以是普通变量,也可以是指针变量
void fun1(const int i)
{
其它语句
……
i++; //对i的值进行了修改,程序报错
其它语句
}
void fun2(const int *p)
{
其它语句
……
(*p)++; //对p指向空间的值进行了修改,程序报错
其它语句
}
第七题 选B

#define 的作用
在编译预处理时,对程序中所有出现的“宏名”,都用宏定义中的字符串去代换,这称为“宏代换”或“宏展开”。
在C或C++语言中,“宏”分为有参数和无参数两种。
(1) 无参宏定义
无参宏的宏名后不带参数。其定义的一般形式为:
#define 标识符 字符串
其中的“#”表示这是一条预处理命令。凡是以“#”开头的均为预处理命令。“define”为宏定义命令。“标识符”为所定义的宏名。“字符串”可以是常数、表达式、格式串等。
例如:
#define M (a+b)
1
(2) 无参宏定义
c语言允许宏带有参数。在宏定义中的参数称为形式参数,在宏调用中的参数称为实际参数。对带参数的宏,在调用中,不仅要宏展开,而且要用实参去代换形参。
带参宏定义的一般形式为:
#define 宏名(形参表) 字符串(在字符串中含有各个形参。)
带参宏调用的一般形式为:
宏名(形参表)
例如:
#ifndef __headerfileXXX__
#define __headerfileXXX__
…
文件内容
…
#endif
(3) 防止重复定义
#define 条件编译
头文件(.h)可以被头文件或C文件包含;
重复包含(重复定义)
由于头文件包含可以嵌套,那么C文件就有可能包含多次同一个头文件,就可能出现重复定义的问题的。
通过条件编译开关来避免重复包含(重复定义)
例如
#ifndef __headerfileXXX__
#define __headerfileXXX__
…
文件内容
…
#endif
宏定义中#与##的作用
#是把宏参数转化为字符串的运算符,##是把两个宏参数连接的运算符。
#define str(arg) #arg 则宏STR(inter)展开时为”inter”
#define name_y(y) name_y 则宏name_y(1)展开时仍为name_y
#define NAME(y) name_##y 则宏NAME(1)展开为name_1
#define DECLARE(name, type) typename##_##type##_type,
则宏DECLARE(val, int)展开为int val_int_type
第八题
关于malloc
当使用malloc后,只有在没有足够内存的情况下会返回NULL,或是出现异常报告。
malloc(0)是指分配内存大小为零 ,malloc(0),系统就已经帮你准备好了堆中的使用起始地址(不会为NULL)。但是你不能对该地址进行写操作(不是不允许),如果写了话,当调用free(ptr)就会产生异常报告(地址受损)。
malloc(0)也是一种存在不是NULL
NULL 一般预定义为 (void *)0,指向0地址。NULL是不指向任何实体
malloc是在程序堆栈上分配空间,不会是0地址 。
第九题

++i:先加后用
i++:先加后用
||:或运算
&&:与运算
第九题

IP地址分两部分: 网络ID+主机ID
比如192.168.1.100/24这个IP地址,掩码为:255.255.255.0
所以它的网络ID是:192.168.1.0 而主机ID为:0.0.0.100
而192.168.1.0是不能作为主机IP用的,它代表192.168.1.0这个子网,这个子网可用IP范围是
192.168.1.1——192.168.1.255 一头一尾都不能用。因为:
192.168.1.0代表网络ID,而192.168.1.255是广播地址。这两个IP要被去掉!
第十题

TCP和UDP协议的区别
1、TCP(面向连接)双方必须连接成功才能发数据,类似打电话,主要用于对传输数据精确的情况,如传输指令。
2、UDP(面向报文)双方无须连接成功就能发数据,类似发短信,主要用于传输大数据量的情况,可靠性不能保证,如视频。
TCP和UDP协议的区别
TCP和UDP协议的相同点:都是传输层协议;
第十一题

recv函数
返回值:
若无错误发生,recv()返回读入的字节数。如果连接已中止,返回0。如果发生错误,返回-1,应用程序可通过perror()获取相应错误信息。
注:
如果套接口为SOCK_STREAM类型,并且远端“优雅”地中止了连接,那么recv()一个数据也不读取,立即返回。如果立即被强制中止,那么recv()将以WSAECONNRESET错误失败返回。在套接口的所设选项之上,还可用标志位flag来影响函数的执行方式。也就是说,本函数的语义既取决于套接口选项,也取决于标志位参数。
多选题


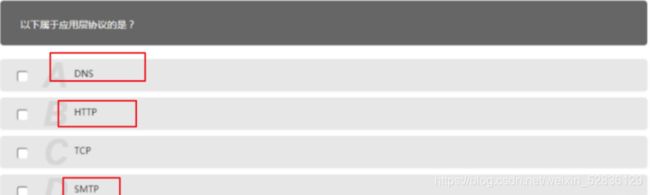
协议汇总
物理层: RJ45 、 CLOCK 、 IEEE802.3 (中继器,集线器)
数据链路: PPP 、 FR 、 HDLC 、 VLAN 、 MAC (网桥,交换机)
网络层: ==IP ==、 ICMP 、 ARP 、 RARP 、 OSPF 、 IPX 、 RIP 、 IGRP 、 (路由器)
传输层: TCP 、 UDP 、 SPX (网关)
会话层: NFS 、 SQL 、 NETBIOS 、 RPC
表示层: JPEG 、 MPEG 、 ASII
应用层: FTP , DNS,Telnet(TELNET) ,SMTP,HTTP , WWW ,NFS,SNMP
简答题
![]()
TCP协议保证数据传输可靠性的方式主要有:
校验和
序列号
确认应答
超时重传
连接管理
流量控制
拥塞控制
![]()
c语言中static关键字用法:
1、static+局部变量:静态局部变量使用static修饰符定义,即使在声明时未赋初值,编译器也会把它初始化为0。且静态局部变量存储于进程的全局数据区,即使函数返回,它的值也会保持不变。
2、static+全局变量:普通全局变量对整个工程可见,其他文件可以使用extern外部声明后直接使用。也就是说其他文件不能再定义一个与其相同名字的变量了(否则编译器会认为它们是同一个变量)。
静态全局变量仅对当前文件可见,其他文件不可访问,其他文件可以定义与其同名的变量,两者互不影响。
3、static+函数
静态函数只能在声明它的文件中可见,其他文件不能引用该函数
不同的文件可以使用相同名字的静态函数,互不影响