Doris ——SQL原理解析
目录
前言
一、Doris简介
二、SQL解析简介
2.1 词法分析
2.2 语法分析
2.3 逻辑计划
2.4 物理计划
三、Doris SQL解析的总体架构
四、Parse阶段
五、Analyze阶段
六、SinglePlan阶段(生成单机逻辑Plan阶段)
七、DistributedPlan计划(生成分布式逻辑阶段)
7.1 DistributedPlan 概述
7.2 四种join算法:
7.2.1 Broadcast Join
7.2.2 Shuffle Join
7.2.3 Bucket Shuffle Join
7.2.4 Colocate Join
7.3 分布式逻辑计划的核心流程
7.3.1 PlanNode
7.3.2 ScanNode
7.3.3 HashJoinNode
八、Schedule阶段
8.1 prepare阶段
8.2 computeScanRangeAssignment阶段
8.3 computeFragmentExecParams阶段
8.4 create result receiver阶段
8.5 to thrift阶段
九、总结
前言
下文主要介绍了Doris SQL解析的原理。阐述了词法分析,语法分析,生成单机逻辑计划,生成分布式逻辑计划,生成分布式物理计划的过程。对应代码实现是Parse, Analyze, SinglePlan, DistributedPlan, Schedule这五个部分。
一、Doris简介
Apache Doris是一个基于MPP架构的高性能、实时的分析型数据库,能够较好的满足报表分析、即席查询、统一数仓构建等使用场景。Doris整体架构非常简单,只有FE和BE两类进程。FE主要负责用户请求的接入、查询解析规划、元数据的管理、节点管理相关工作。BE主要负责数据存储、查询计划的执行。
在 Doris 的存储引擎中,用户数据被水平划分为若干个数据分片(Tablet,也称作数据分桶)。每个Tablet 包含若干数据行。多个 Tablet 在逻辑上归属于不同的分区(Partition)。一个 Tablet 只属于一个 Partition。而一个 Partition 包含若干个 Tablet。Tablet 是数据移动、复制等操作的最小物理存储单元。
官网链接指路:
Doris 介绍 - Apache Doris
二、SQL解析简介
sql解析指的是:一条sql语句经过一系列的解析最后生成一个完整的物理执行计划的过程。解析过程主要包括以下四个步骤:词法分析,语法分析,生成逻辑计划,生成物理计划。
- 词法分析:解析原始SQL文本,拆分token
- 语法分析:将token转换成抽象语法树(AST)
- 逻辑查询计划:
- 单机逻辑查询计划:对AST经过一系列优化(比如:谓词下推等)成查询计划,提高执行性能和效率
- 分布式逻辑查询计划:根据分布式环境(数据分布信息、连接信息、join算法等)将单机逻辑查询计划转换成分布式
- 物理查询计划:在逻辑查询计划的基础上,根据数据的存储方式和机器的分布情况生成实际的执行计划
Doris SQL 解析架构具体介绍如下:

2.1 词法分析
词法分析主要负责将字符串形式的sql识别成一个个token,为语法分析做准备。
select ...... from ...... where ....... group by ..... order by ......
SQL的Token 可以分为如下几类:
○ 关键字(select、from、where)
○ 操作符(+、-、>=)
○ 开闭合标志((、CASE)
○ 占位符(?)
○ 注释
○ 空格2.2 语法分析
语法分析主要负责根据语法规则,将词法分析生成的token转成抽象语法树(Abstract Syntax Tree),如图2所示。

2.3 逻辑计划
逻辑计划负责将抽象语法树转成代数关系。代数关系是一棵算子树,每个节点代表一种对数据的计算方式,整棵树代表了数据的计算方式以及流动方向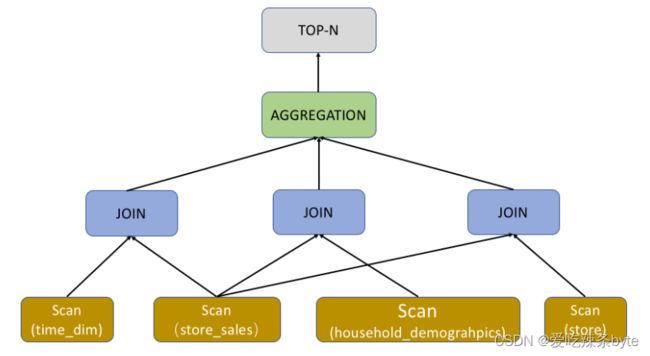
2.4 物理计划
物理计划是在逻辑计划的基础上,根据机器的分布,数据的分布,决定去哪些机器上执行哪些计算操作。Doris系统的SQL解析也是采用这些步骤,只不过根据Doris系统结构的特点和数据的存储方式,进行了细化和优化,最大化发挥机器的计算能力。
三、Doris SQL解析的总体架构
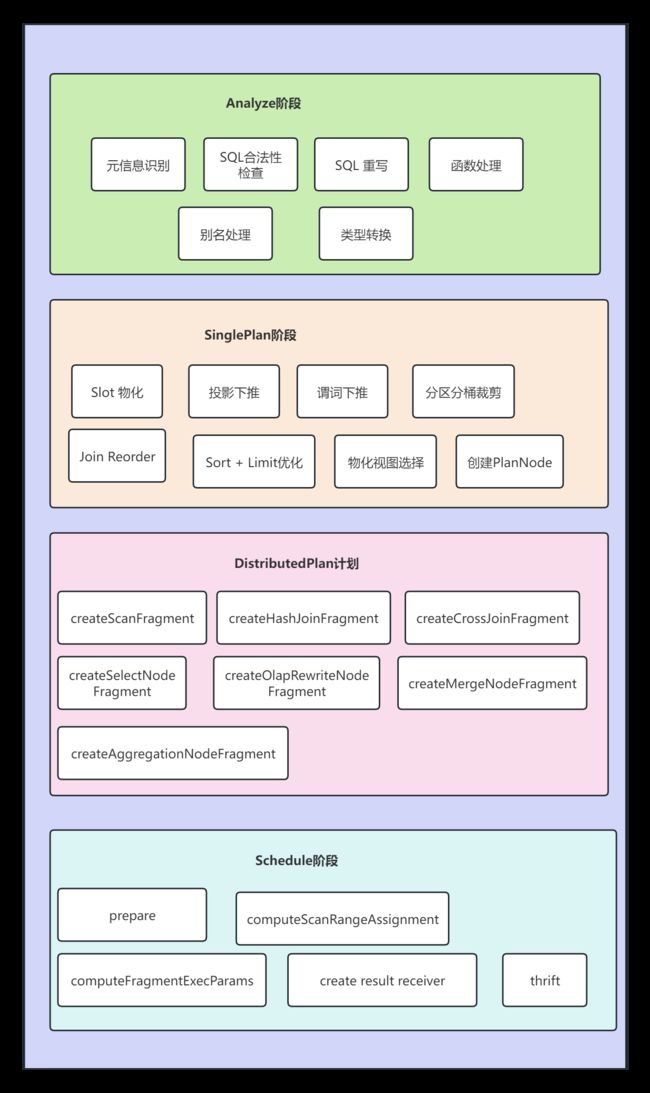
Doris SQL解析具体包括了五个步骤:词法分析,语法分析,生成单机逻辑计划,生成分布式逻辑计划,生成物理执行计划。具体代码实现上包含以下五个步骤:Parse, Analyze, SinglePlan, DistributedPlan, Schedule。
四、Parse阶段
Parse阶段主要涉及三部分工作:
- 构建词法解析器
- 词法分析,将 doris sql中的关键词识别成一个个token
- 进行语法解析,将词法分析生成的token转成抽象语法树AST
五、Analyze阶段
SQL 语句被解析成AST之后,会被交给 StmtExecutor进行一些前期的处理和语义分析,为生成单机逻辑计划做准备,大概会做下面的事情:
- 元信息的识别和解析
识别和解析sql中涉及的 Cluster, Database, Table, Column 等元信息,确定需要对哪个集群的哪个数据库的哪些表的哪些列进行计算。
- SQL 的合法性检查
窗口函数不能 DISTINCT,投影列是否有歧义,where语句中不能含有grouping操作等。
- SQL 重写
比如将 select * 扩展成 select 所有列,count distinct转成bitmap或者hll函数等。
- 函数处理
检查sql中包含的函数和系统定义的函数是否一致,包括参数类型,参数个数等。
- Table与Column别名处理
- 类型检查和转换
例如:二元表达式两边的类型不一致时,需要对其中一个类型进行转换(bigint和decimal比较,bigint类型需要转换成decimal)
总结,对AST进行analyze后会再进行一次rewrite操作,进行精简或者是转成统一的处理方式
六、SinglePlan阶段(生成单机逻辑Plan阶段)
此阶段主要是根据AST抽象语法树生成算子数。树上的每个节点都是一个算子。如下图所示,ScanNode代表着对一个表的扫描操作,将一个表的数据读出来。HashJoinNode代表着join操作,将小表广播到大表所在的每个节点,内存中构建哈希表,然后遍历大表每条记录做关联。Project算子表示投影操作,代表着最后需要输出的列,下图中的sql表示只用输出citycode这一列。

SinglePlan阶段主要做了如下几项工作:
- Slot 物化:指确定一个表达式对应的列需要 Scan 和计算,比如聚合节点的聚合函数表达式和 Group By 表达式需要进行物化(Slot:计算槽,是一个资源单位, 只有给 task 分配了一个 slot 之后, 这个task才可以运行)
- 投影下推:BE在Scan 时只会Scan必须读取的列
- 谓词下推:在满足语义正确的前提下将过滤条件尽可能下推到Scan节点
- 分区,分桶裁剪:根据过滤条件中的信息,确定需要扫描哪些分区,哪些桶的tablet
- Join Reorder:对于 Join操作, Doris会根据行数调整表的顺序,将大表放在前面。在保证结果不变的情况,通过规则计算最优(最少资源)join 操作
- Sort + Limit 优化成 TopN:对于order by limit语句会转换成TopN的操作节点
- MaterializedView 选择:会根据查询需要的列,过滤,排序和 Join 的列,行数,列数等因素选择最佳的物化视图
-
向量化执行引擎选择:基于现代CPU的特点,重新设计列式存储系统的SQL执行引擎,从而提高了CPU在SQL执行时的效率,提升了SQL查询的性能
-
Runtime Filter Join:Doris 在进行Hash Join 计算时会将小表广播到大表所在的各个节点上,构建一个内存哈希表,然后流式读出大表的数据进行Hash Join。而 RuntimeFilter是在右表生成哈希表的时候,动态生成一个基于哈希表数据的过滤条件,将该过滤条件下推到大表的数据扫描节点,从而减少扫描的数据量,避免不必要的I/O和网络传输。
七、DistributedPlan计划(生成分布式逻辑阶段)
7.1 DistributedPlan 概述
(1) 根据分布式环境,将单机的PlanNode树(planNode : 逻辑算子)拆分成分布式PlanFragment树(PlanFragment用来表示独立的执行单元)
(2)每个 PlanFragment 由 PlanNodeTree 和 Data Sink 组成。Plan分布式化的方法是增加 ExchangeNode,PlanNodeTree执行计划树会以 ExchangeNode为边界拆分为 PlanFragment。 ExchangeNode主要是用于BE之间的数据交换与共享,类似 Spark 和 MR 中的 Shuffle。
(3)DistributedPlan阶段的主要目标是最大化并行度和数据本地化。主要方法是将能够并行执行的节点拆分出去单独建立一个PlanFragment,用ExchangeNode代替被拆分出去的节点,用来接收数据。拆分出去的节点增加一个DataSinkNode,用来将计算之后数据传送到ExchangeNode中,做进一步的处理。
(4)DistributedPlanner中最主要的工作是决定Join的分布式执行策略:Broadcast Join,Shuffle Join,Bucket Shuffle Join,Colocate Join以及增加 Aggregation 的 Merge 阶段。
7.2 四种join算法:
对于查询操作来说,join操作是最常见的一种操作。Doris目前支持4种join算法:Broadcast Join,Shuffle Join,Bucket Shuffle Join,Colocate Join。
7.2.1 Broadcast Join
小表进行条件过滤后,将其广播到大表所在的各个节点上,形成一个内存Hash 表,然后流式读出大表的数据Hash Join。Doris会自动尝试进行 Broadcast Join,如果预估小表过大则会自动切换至 Shuffle Join。
7.2.2 Shuffle Join
大表和大表join时,一般采用hash partition join。它遍历表中的所有数据,计算key的哈希值,然后对集群数取模,选到哪台机器,就将数据发送到这台机器进行hash join操作。
7.2.3 Bucket Shuffle Join
当join列是左表的分桶列,可以采用bucket shuffle join算法。下图中的hash(column) % n 中的n指的是左表的桶数,column代表的是join 列,同时也是分桶列。这样左表数据不移动,右表数据根据分区计算的结果发送到左表扫表的节点就可以完成Join的计算。即只需网络传输一份右表数据就可以了,极大减少了数据的网络传输。

7.2.4 Colocate Join
两个表在创建的时候就指定了数据分布保持一致,那么当两个表的join key与分桶的key一致时,就会采用colocate join算法。由于两个表的数据分布是一样的,那么hash join操作就相当于在本地,不涉及到任何的数据传输,极大提高查询性能。
总结:上面这 4 种join方式灵活度是从高到低的,它对这个数据分布的要求是越来越严格,但 Join计算的性能也是越来越好的。
7.3 分布式逻辑计划的核心流程
7.3.1 PlanNode
如果是PlanNode, 自底向上创建PlanFragment。
7.3.2 ScanNode
如果是ScanNode,则直接创建一个PlanFragment,PlanFragment的RootPlanNode是这个ScanNode。
7.3.3 HashJoinNode
如果是HashJoinNode,则首先计算下broadcastCost(成本),根据不同的条件判断选择哪种Join算法。

(1)如果使用colocate join,由于join操作都在本地,就不需要拆分。设置HashJoinNode的左子节点为leftFragment的RootPlanNode,右子节点为rightFragment的RootPlanNode,与leftFragment共用一个PlanFragment,删除掉rightFragment。
(2)如果使用bucket shuffle join,需要将右表的数据发送给左表。所以先创建了一个ExchangeNode,设置HashJoinNode的左子节点为leftFragment的RootPlanNode,右子节点为这个ExchangeNode,与leftFragment共用一个PlanFragment,并且指定rightFragment数据发送的目的地为这个ExchangeNode。
(3)如果使用broadcast join,需要将右表的数据发送给左表。所以先创建了一个ExchangeNode,设置HashJoinNode的左子节点为leftFragment的RootPlanNode,右子节点为这个ExchangeNode,与leftFragment共用一个PlanFragment,并且指定rightFragment数据发送的目的地为这个ExchangeNode。
(4)如果使用hash partition join(也就是shuffle joun),左表和右边的数据都要切分,需要将左右节点都拆分出去,分别创建left ExchangeNode, right ExchangeNode,HashJoinNode指定左右节点为left ExchangeNode和 right ExchangeNode。单独创建一个PlanFragment,指定RootPlanNode为这个HashJoinNode。最后指定leftFragment, rightFragment的数据发送目的地为left ExchangeNode, right ExchangeNode。

八、Schedule阶段
该阶段是根据分布式逻辑计划,创建分布式物理计划。主要解决以下问题:
-
哪个 BE 执行哪个 PlanFragment
-
每个Tablet选择哪个副本去查询
-
如何进行多实例并发
创建分布式物理计划的核心流程有:
8.1 prepare阶段
给每个PlanFragment创建一个FragmentExecParams结构,用来表示PlanFragment执行时所需的所有参数;如果一个PlanFragment包含有DataSinkNode,则找到数据发送的目的PlanFragment,然后指定目的PlanFragment的FragmentExecParams的输入为该PlanFragment的FragmentExecParams。
8.2 computeScanRangeAssignment阶段
对fragment合理分配,尽可能保证每个BE节点的请求都是平均,针对不同类型的join进行不同的处理。
- computeScanRangeAssignmentByColocate
针对colocate join 进行处理,由于Join得两个表桶中的数据分布是一样的,他们是基于桶的join操作,所以在这里确定每个桶选择哪个host。在给host分配桶的时候,尽量保证每个host分配到的桶基本平均。
- computeScanRangeAssignmentByBucket
对bucket shuffle join进行处理,也只是基于桶的操作,所以在这里是确定每个桶选择哪个host。在给host分配桶时,同样需要尽量保证每个host分配到的桶基本平均。
- computeScanRangeAssignmentByScheduler
针对其他类型的join进行处理。确定每个scanNode读取tablet哪个副本。一个scanNode会读取多个tablet,每个tablet有多个副本。为了使sca操作尽可能的分散到多台机器上去,提高并发性能,减少IO压力,Doris 采用了Round-Robin算法,使tablet的扫描尽可能分散到多台机器上去。例如100个tablet需要扫描,每个tablet有3个副本,假设集群有10台机器,在分配时,保障每台机器扫10个tablet。
8.3 computeFragmentExecParams阶段
处理Fragment执行参数,这个阶段解决PlanFragment下发到哪个BE上执行, 以及如何处理实例并发问题。
8.4 create result receiver阶段
result receiver是查询完成后,最终数据需要输出的地方。
8.5 to thrift阶段
根据所有PlanFragment创建的rpc请求下发到BE端执行,一个完整的SQL解析过程完成了。
综上所述:

九、总结
本篇文章介绍了sql解析的通用流程:词法分析,语法分析,生成逻辑计划,生成物理计划。从总体上阐述了Doris在sql解析这块的总体架构,从代码和算法层面上解析Parse, Analyze, SinglePlan, DistributedPlan, Schedule五步骤的内容。
Doris遵守了sql解析的常用方法,根据底层存储架构,以及分布式的特点,在sql解析这块进行了大量的优化,实现了最大化的计算并行度、最小化的数据网络传输,最大化减少需扫描的数据量,给sql执行层面减少了很多负担。
补充:Hive SQL编译成MapReduce任务的过程 见文章:
(02)Hive SQL编译成MapReduce任务的过程-CSDN博客文章浏览阅读1.4k次,点赞30次,收藏23次。Hive SQL编译成MapReduce的过程https://blog.csdn.net/SHWAITME/article/details/136103206?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170813605316800182123993%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=170813605316800182123993&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-1-136103206-null-null.nonecase&utm_term=mapreduce&spm=1018.2226.3001.4450
参考文章:
【Doris全面解析】Doris SQL 原理解析
聊聊分布式 SQL 数据库Doris(五)-腾讯云开发者社区-腾讯云
https://blog.csdn.net/qq_34635236/article/details/128114948?ops_request_misc=&request_id=&biz_id=102&utm_term=doris%20sql%20%E6%BA%90%E7%A0%81&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-0-128114948.142%5Ev99%5Epc_search_result_base6&spm=1018.2226.3001.4187