MySQL1000万条数据分页查询优化
这种问题的解决就是通过构建一个新的小表,以小表来join驱动大表;或者构建一个子查询语句,用exist,in做查询;或者注意索引下推和索引覆盖的使用。
概述
今天一个朋友问我一个问题,说MySQL很多数据查询怎么优化。我就直接说了个分页查询就行了啊,查询字段加索引。然而结果并没有我想象得那么简单,他分页查询直接把服务查崩了。原来他们数据量已经有好几百万了。你可能会问不就几百万数据吗,分页只查询10条怎么可能查询会很慢。后面我会模拟1000万条数据分页查询。
准备工作
1.新建一个测试库,我这里就叫test

2.在此库中新建一张student表
CREATE TABLE `student` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(10) NOT NULL COMMENT '姓名',
`age` int(10) unsigned NOT NULL COMMENT '岁数',
PRIMARY KEY (`id`),
KEY `age` (`age`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
3.此时需要新建1000万条数据,这里我提供一段简短得代码。复制过去就可以用
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class InsertTest {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
final String url = "jdbc:mysql://127.0.0.1/test?useUnicode=true&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=UTC";
final String name = "com.mysql.cj.jdbc.Driver";
final String user = "root";
final String password = "928888";
Connection conn = null;
//指定连接类型
Class.forName(name);
//获取连接
conn = DriverManager.getConnection(url, user, password);
if (conn != null) {
System.out.println("获取连接成功");
//插入操作
batchInsert(conn);
} else {
System.out.println("获取连接失败");
}
}
public static void batchInsert(Connection conn) {
// 开始时间
Long begin = System.currentTimeMillis();
// sql前缀
String sqlPrefix = "INSERT INTO student (name, age) VALUES ";
try {
// 保存sql后缀
StringBuffer sqlSuffix = new StringBuffer();
// 设置事务为非自动提交
conn.setAutoCommit(false);
//准备执行语句
PreparedStatement pst = (PreparedStatement) conn.prepareStatement(" ");
// 外层循环,总提交事务次数
for (int i = 1; i <= 100; i++) {
sqlSuffix = new StringBuffer();
// 第j次提交步长
for (int j = 1; j <= 100000; j++) {
// 构建SQL后缀
sqlSuffix.append("('" + "cxx" + j + "'," + 1 + "),");
}
// 构建完整SQL
String sql = sqlPrefix + sqlSuffix.substring(0, sqlSuffix.length() - 1);
// 添加执行SQL
pst.addBatch(sql);
// 执行操作
pst.executeBatch();
// 提交事务
conn.commit();
// 清空上一次添加的数据
sqlSuffix = new StringBuffer();
}
// 头等连接
pst.close();
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
// 结束时间
Long end = System.currentTimeMillis();
// 耗时
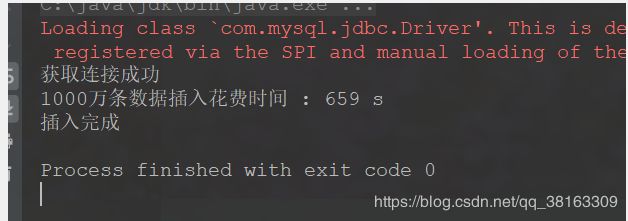
System.out.println("1000万条数据插入花费时间 : " + (end - begin) + "ms");
System.out.println("插入完成");
}
}此处可能执行时间比较长,各位小伙伴不要心急,下图是我得执行时间
分页查询测试
1.首先我测试一条我们常见的分页sql,大家可以猜测下执行时间
select * from student where age = 1 limit 9000000,1 
2.这里我第一次执行了100多秒,第二次因为有缓存所以只执行了40多秒
我第一次测试我也不敢相信自己得眼睛,what,不就查询一条数据怎么可能需要这么久,而且我的age还是建立了索引得,照理说不应该这么慢啊(为此我还专门查询了sql执行计划,确实是走了索引得,如下图所示)
执行器脚本如下
EXPLAIN select * from student where age = 1 limit 9000000,1
3.可能有的人不知道limit 9000000,1是什么意思,我大概解释一下就是从第9000000万行开始查询一行
4.后面我查了相关资料才知道原来起始数据开始比较小的时候不会影响查询,但是起始数据后数据增大后查询就会变得特别慢(起始数据得意思是从多少行开始)
原因分析
1.因为数据表是InnoDB,根据InnoDB索引的结构,查询过程为:
通过普通索引查到主键值(找出所有age=1的id)
再根据查到的主键值通过主键索引找到相应的数据块(根据id找出对应的数据块内容)
根据offset的值,查询9000001次主键索引的数据,最后将之前的9000000条丢弃,取出最后1条(这里应该是导致数据查询缓慢得原因)。
2.下面我用具体的实例来分析
首先你执行查询所有列得脚本
select * from student where age = 1 limit 9000000,1
此处可能需要等几十秒
执行完后执行下面者条语句来查看buffer pool的内容
select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('primary','age') and TABLE_NAME like '%student%' group by index_name;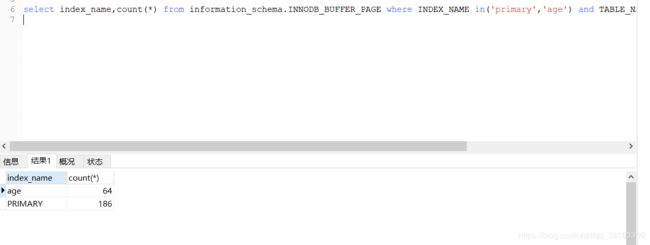
此时buffer pool中关于student表有186个数据页,64个索引页(此处不一定准确,因为我第一次执行比这个多很多,这里是有缓存。如果你们想测试最初得值可以关闭MySQL重新启动)
我们在执行只查询id列得脚本
select id from student where age = 1 limit 9000000,1
此时可以看出数据页减少了很多,这里我们可以得出结论:MySQL查询时,起始数量过大影响性能的原因是多次通过主键索引访问数据块的I/O操作。
解决方案
1.根据上面的分析,我们知道查询所有字段会导致主键索引多次访问数据块造成的I/O操作。
2.因此我们先查出偏移后的主键,再根据主键索引查询数据块的所有内容即可优化。
3.优化后得脚本:
SELECT
a.*
FROM
student a
RIGHT JOIN (
SELECT
id
FROM
student
WHERE
age = 1
LIMIT 9000000,
1
) t ON a.id = t.id
此时我们可以看出执行时间较少了很多
总结
以上就是全篇文章得内容,感谢各位百忙之中抽出时间来查看本文。希望本文能对大家在工作中有一定的帮助。希望大家也能指出相应得问题,大家共同学习。