Mapreduce执行过程分析(基于Hadoop2.4)——(二)
4.3 Map类
创建Map类和map函数,map函数是org.apache.hadoop.mapreduce.Mapper类中的定义的,当处理每一个键值对的时候,都要调用一次map方法,用户需要覆写此方法。此外还有setup方法和cleanup方法。map方法是当map任务开始运行的时候调用一次,cleanup方法是整个map任务结束的时候运行一次。
4.3.1 Map介绍
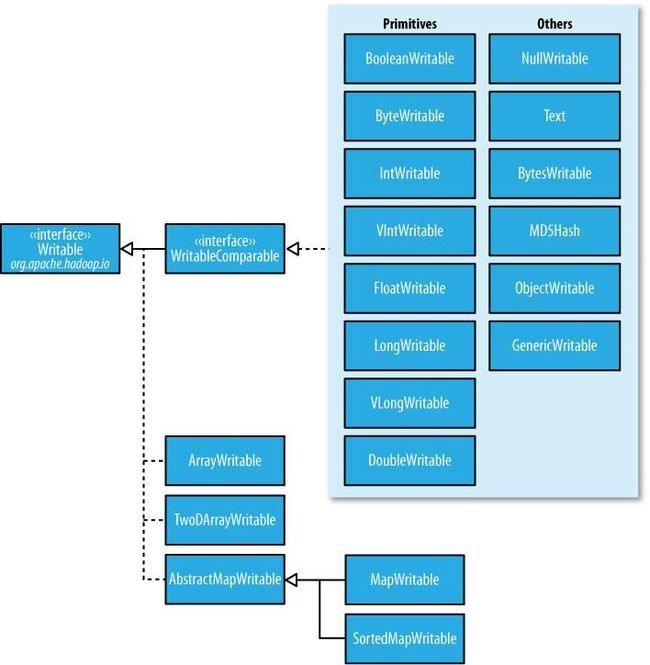
Mapper类是一个泛型类,带有4个参数(输入的键,输入的值,输出的键,输出的值)。在这里输入的键为Object(默认是行),输入的值为Text(hadoop中的String类型),输出的键为Text(关键字)和输出的值为IntWritable(hadoop中的int类型)。以上所有hadoop数据类型和java的数据类型都很相像,除了它们是针对网络序列化而做的特殊优化。
MapReduce中的类似于IntWritable的类型还有如下几种:
BooleanWritable:标准布尔型数值、ByteWritable:单字节数值、DoubleWritable:双字节数值、FloatWritable:浮点数、IntWritable:整型数、LongWritable:长整型数、Text:使用UTF8格式存储的文本(类似java中的String)、NullWritable:当<key, value>中的key或value为空时使用。
这些都是实现了WritableComparable接口:
Map任务是一类将输入记录集转换为中间格式记录集的独立任务。 Mapper类中的map方法将输入键值对(key/value pair)映射到一组中间格式的键值对集合。这种转换的中间格式记录集不需要与输入记录集的类型一致。一个给定的输入键值对可以映射成0个或多个输出键值对。
1 StringTokenizer itr = new StringTokenizer(value.toString());
2 while (itr.hasMoreTokens()) { 3 word.set(itr.nextToken()); 4 context.write(word, one); 5 }
这里将输入的行进行解析分割之后,利用Context的write方法进行保存。而Context是实现了MapContext接口的一个抽象内部类。此处把解析出的每个单词作为key,将整形1作为对应的value,表示此单词出现了一次。map就是一个分的过程,reduce就是合的过程。Map任务的个数和前面的split的数目对应,作为map函数的输入。Map任务的具体执行见下一小节。
4.3.2 Map任务分析
Map任务被提交到Yarn后,被ApplicationMaster启动,任务的形式是YarnChild进程,在其中会执行MapTask的run方法。无论是MapTask还是ReduceTask都是继承的Task这个抽象类。
run方法的执行步骤有:
Step1:
判断是否有Reduce任务,如果没有的话,Map任务结束,就整个提交的作业结束;如果有的话,当Map任务完成的时候设置当前进度为66.7%,Sort完成的时候设置进度为33.3%。
Step2:
启动TaskReporter线程,用于更新当前的状态。
Step3:
初始化任务,设置任务的当前状态为RUNNING,设置输出目录等。
Step4:
判断当前是否是jobCleanup任务、jobSetup任务、taskCleanup任务及相应的处理。
Step5:
调用runNewMapper方法,执行具体的map。
Step6:
作业完成之后,调用done方法,进行任务的清理、计数器更新、任务状态更新等。
4.3.3 runNewMapper分析
下面我们来看看这个runNewMapper方法。代码如下:
1 private <INKEY,INVALUE,OUTKEY,OUTVALUE>
2 void runNewMapper(final JobConf job,
3 final TaskSplitIndex splitIndex, 4 final TaskUmbilicalProtocol umbilical, 5 TaskReporter reporter 6 ) throws IOException, ClassNotFoundException, 7 InterruptedException { 8 // make a task context so we can get the classes 9 org.apache.hadoop.mapreduce.TaskAttemptContext taskContext = new org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl(job, getTaskID(), reporter); 10 11 // make a mapper
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE> mapper = (org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>) 12 ReflectionUtils.newInstance(taskContext.getMapperClass(), job); 13 14 // make the input format org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE> inputFormat = (org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE>) 16 ReflectionUtils.newInstance(taskContext.getInputFormatClass(), job);
18 // rebuild the input split 19 org.apache.hadoop.mapreduce.InputSplit split = null;20 21 split = getSplitDetails(new path(splitIndex.getSplitLocation()), splitIndex.getStartOffset()); 24 25 LOG.info("Processing split: " + split); 26 org.apache.hadoop.mapreduce.RecordReader<INKEY,INVALUE> input = new NewTrackingRecordReader<INKEY,INVALUE> (split, inputFormat, reporter, taskContext); 27 28 job.setBoolean(JobContext.SKIP_RECORDS, isSkipping()); 29 org.apache.hadoop.mapreduce.RecordWriter output = null; 30 31 // get an output object 32 if (job.getNumReduceTasks() == 0) { 33 output = new NewDirectOutputCollector(taskContext, job, umbilical, reporter); 34 } else { 35 output = new NewOutputCollector(taskContext, job, umbilical, reporter); 36 } 37 38 org.apache.hadoop.mapreduce.MapContext<INKEY, INVALUE, OUTKEY, OUTVALUE> mapContext = new MapContextImpl<INKEY, INVALUE, OUTKEY, OUTVALUE>(job, getTaskID(), input, output, committer, reporter, split); 39 org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>.Context mapperContext = new WrappedMapper<INKEY, INVALUE, OUTKEY, OUTVALUE>().getMapContext(mapContext); 40 41 try { 42 input.initialize(split, mapperContext); 43 mapper.run(mapperContext); 44 mapPhase.complete(); 45 setPhase(TaskStatus.Phase.SORT); 46 statusUpdate(umbilical); 47 input.close(); 48 input = null; 49 output.close(mapperContext); 50 output = null; 51 } finally { 52 closeQuietly(input); 53 closeQuietly(output, mapperContext); 54 } 55 }
此方法的主要执行流程是:
Step1:
获取配置信息类对象TaskAttemptContextImpl、自己开发的Mapper的实例mapper、用户指定的InputFormat对象 (默认是TextInputFormat)、任务对应的分片信息split。
其中TaskAttemptContextImpl类实现TaskAttemptContext接口,而TaskAttemptContext接口又继承于JobContext和Progressable接口,但是相对于JobContext增加了一些有关task的信息。通过TaskAttemptContextImpl对象可以获得很多与任务执行相关的类,比如用户定义的Mapper类,InputFormat类等。
Step2:
根据inputFormat构建一个NewTrackingRecordReader对象,这个对象中的RecordReader<K,V> real是LineRecordReader,用于读取分片中的内容,传递给Mapper的map方法做处理的。
Step3:
然后创建org.apache.hadoop.mapreduce.RecordWriter对象,作为任务的输出,如果没有reducer,就设置此RecordWriter对象为NewDirectOutputCollector(taskContext, job, umbilical, reporter)直接输出到HDFS上;如果有reducer,就设置此RecordWriter对象为NewOutputCollector(taskContext, job, umbilical, reporter)作为输出。
NewOutputCollector是有reducer的作业的map的输出。这个类的主要包含的对象是MapOutputCollector<K,V> collector,是利用反射工具构造出来的:
1 ReflectionUtils.newInstance(job.getClass(JobContext.MAP_OUTPUT_COLLECTOR_CLASS_ATTR, MapOutputBuffer.class, MapOutputCollector.class), job);
如果Reduce的个数大于1,则实例化org.apache.hadoop.mapreduce.Partitioner<K,V> (默认是HashPartitioner.class),用来对mapper的输出数据进行分区,即数据要汇总到哪个reducer上,NewOutputCollector的write方法会调用collector.collect(key, value,partitioner.getPartition(key, value, partitions));否则设置分区个数为0。
Step4:
打开输入文件(构建一个LineReader对象,在这实现文件内容的具体读)并且将文件指针指向文件头。由LineRecordReader的initialize方法完成。
实际上读文件内容的是类中的LineReader对象in,该对象在initialize方法中进行了初始化,会根据输入文件的文件类型(压缩或不压缩)传入相应输入流对象。LineReader会从输入流对象中通过:
in.readLine(new Text(), 0, maxBytesToConsume(start));
方法每次读取一行放入Text对象str中,并返回读取数据的长度。
LineRecordReader.nextKeyValue()方法会设置两个对象key和value,key是一个偏移量指的是当前这行数据在输入文件中的偏移量(注意这个偏移量可不是对应单个分片内的偏移量,而是针对整个文中的偏移量),value是通过LineReader的对象in读取的一行内容:
1 in.readLine(value, maxLineLength, Math.max(maxBytesToConsume(pos), maxLineLength));
如果没有数据可读了,这个方法会返回false,否则true。
另外,getCurrentKey()和getCurrentValue()是获取当前的key和value,调用这俩方法之前需要先调用nextKeyValue()为key和value赋新值,否则会重复。
这样就跟org.apache.hadoop.mapreduce.Mapper中的run方法关联起来了。
Step5:
执行org.apache.hadoop.mapreduce.Mapper的run方法。
1 public void run(Context context) throws IOException, InterruptedException {
3 setup(context); 5 try { 7 while (context.nextKeyValue()) { 9 map(context.getCurrentKey(), context.getCurrentValue(), context); 11 } 13 } finally { 15 cleanup(context); 17 } 19 }
Step5.1:
首先会执行setup方法,用于设定用户自定义的一些参数等,方便在下面的操作步骤中读取。参数是设置在Context中的。此对象的初始化在MapTask类中的runNewMapper方法中:
1 org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>.Context
3 mapperContext = new WrappedMapper<INKEY, INVALUE, OUTKEY, OUTVALUE>().getMapContext(mapContext);
会将LineRecordReader的实例对象和NewOutputCollector的实例对象传进去,下面的nextKeyValue()、getCurrentValue()、getCurrentKey()会调用reader的相应方法,从而实现了Mapper.run方法中的nextKeyValue()不断获取key和value。
Step5.2:
循环中的map方法就是用户自定的map。map方法逻辑处理完之后,最后都会有context.write(K,V)方法用来将计算数据输出。此write方法最后调用的是NewOutputCollector.write方法,write方法会调用MapOutputBuffer.collect(key, value,partitioner.getPartition(key, value, partitions))方法,用于汇报进度、序列化数据并将其缓存等,主要是里面还有个Spill的过程,下一小节会详细介绍。
Step5.3:
当读完数据之后,会调用cleanup方法来做一些清理工作,这点我们同样可以利用,我们可以根据自己的需要重写cleanup方法。
Step6:
最后是输出流的关闭output.close(mapperContext),该方法会执行MapOutputBuffer.flush()操作会将剩余的数据也通过sortAndSpill()方法写入本地文件,并在最后调用mergeParts()方法合并所有spill文件。sortAndSpill方法在4.3.4小节中会介绍。
4.3.4 Spill分析
Spill的汉语意思是溢出,spill处理就是溢出写。怎么个溢出法呢?Spill过程包括输出、排序、溢写、合并等步骤,有点复杂,如图所示:
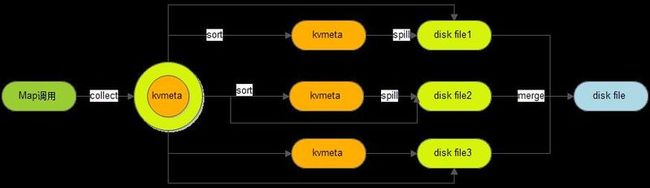
每个Map任务不断地以<key, value>对的形式把数据输出到在内存中构造的一个环形数据结构中。使用环形数据结构是为了更有效地使用内存空间,在内存中放置尽可能多的数据。
这个数据结构其实就是个字节数组,叫kvbuffer,这里面不只有<key, value>数据,还放置了一些索引数据,并且给放置索引数据的区域起了一个kvmeta的别名。
kvbuffer = new byte[maxMemUsage];
bufvoid = kvbuffer.length; kvmeta = ByteBuffer.wrap(kvbuffer).order(ByteOrder.nativeOrder()).asIntBuffer(); setEquator(0); bufstart = bufend = bufindex = equator; kvstart = kvend = kvindex;
kvmeta是对记录Record<key, value>在kvbuffer中的索引,是个四元组,包括:value的起始位置、key的起始位置、partition值、value的长度,占用四个Int长度,kvmeta的存放指针kvindex每次都是向下跳四步,然后再向上一个坑一个坑地填充四元组的数据。比如kvindex初始位置是-4,当第一个<key, value>写完之后,(kvindex+0)的位置存放value的起始位置、(kvindex+1)的位置存放key的起始位置、(kindex+2)的位置存放partition的值、(kvindex+3)的位置存放value的长度,然后kvindex跳到-8位置,等第二个<key, value>和索引写完之后,kvindex跳到-32位置。
<key, value>数据区域和索引数据区域在kvbuffer中是相邻不重叠的两个区域,用一个分界点来划分两者,而分割点是变化的,每次Spill之后都会更新一次。初始的分界点是0,<key, value>数据的存储方向是向上增长,索引数据的存储方向是向下增长,如图所示:
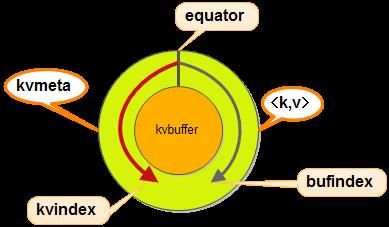
其中,kvbuffer的大小maxMemUsage的默认是100M。涉及到的变量有点多:
(1)kvstart是有效记录开始的下标;
(2)kvindex是下一个可做记录的位置;
(3)kvend在开始Spill的时候它会被赋值为kvindex的值,Spill结束时,它的值会被赋给kvstart,这时候kvstart==kvend。这就是说,如果kvstart不等于kvend,系统正在spill,否则,kvstart==kvend,系统处于普通工作状态;
(4)bufvoid,用于表明实际使用的缓冲区结尾;
(5)bufmark,用于标记记录的结尾;
(6)bufindex初始值为0,一个Int型的key写完之后,bufindex增长为4,一个Int型的value写完之后,bufindex增长为8
在kvindex和bufindex之间(包括equator节点)的那一坨数据就是未被Spill的数据。如果这部分数据所占用的空间大于等于Spill的指定百分比(默认是80%),则开始调用startSpill方法进行溢写。对应的方法为:
1 private void startSpill() {
2
3 assert !spillInProgress; 4 5 kvend = (kvindex + NMETA) % kvmeta.capacity(); 6 7 bufend = bufmark; 8 9 spillInProgress = true; 10 11 LOG.info("Spilling map output"); 12 13 LOG.info("bufstart = " + bufstart + "; bufend = " + bufmark + 14 15 "; bufvoid = " + bufvoid); 16 17 LOG.info("kvstart = " + kvstart + "(" + (kvstart * 4) + 18 19 "); kvend = " + kvend + "(" + (kvend * 4) + 20 21 "); length = " + (distanceTo(kvend, kvstart, 22 23 kvmeta.capacity()) + 1) + "/" + maxRec); 24 25 spillReady.signal(); 26 27 }
这里会触发信号量,使得在MapTask类的init方法中正在等待的SpillThread线程继续运行。
1 while (true) {
3 spillDone.signal(); 5 while (!spillInProgress) { 7 spillReady.await(); 9 } 10 11 try { 13 spillLock.unlock(); 15 sortAndSpill(); 17 } catch (Throwable t) { 19 sortSpillException = t; 21 } finally { 23 spillLock.lock(); 25 if (bufend < bufstart) { 27 bufvoid = kvbuffer.length; 29 } 30 31 kvstart = kvend; 33 bufstart = bufend; 35 spillInProgress = false; 37 } 39 }
继续调用sortAndSpill方法,此方法负责将buf中的数据刷到磁盘。主要是根据排过序的kvmeta把每个partition的<key, value>数据写到文件中,一个partition对应的数据搞完之后顺序地搞下个partition,直到把所有的partition遍历完(partiton的个数就是reduce的个数)。
Step1:
先计算写入文件的大小;
1 final long size = (bufend >= bufstart
3 ? bufend - bufstart 5 : (bufvoid - bufend) + bufstart) + 7 partitions * APPROX_HEADER_LENGTH;
Step2:
然后获取写到本地(非HDFS)文件的文件名,会有一个编号,例如output/spill2.out;命名格式对应的代码为:
1 return lDirAlloc.getLocalPathForWrite(MRJobConfig.OUTPUT + "/spill" 2 3 + spillNumber + ".out", size, getConf());
Step3:
使用快排对缓冲区kvbuffe中区间[bufstart,bufend)内的数据进行排序,先按分区编号partition进行升序,然后按照key进行升序。这样经过排序后,数据以分区为单位聚集在一起,且同一分区内所有数据按照key有序;
Step4:
构建一个IFile.Writer对象将输出流传进去,输出到指定的文件当中,这个对象支持行级的压缩。
1 writer = new Writer<K, V>(job, out, keyClass, valClass, codec, spilledRecordsCounter);
如果用户设置了Combiner(实际上是一个Reducer),则写入文件之前会对每个分区中的数据进行一次聚集操作,通过combinerRunner.combine(kvIter, combineCollector)实现,进而会执行reducer.run方法,只不过输出和正常的reducer不一样而已,这里最终会调用IFile.Writer的append方法实现本地文件的写入。
Step5:
将元数据信息写到内存索引数据结构SpillRecord中。如果内存中索引大于1MB,则写到文件名类似于output/spill2.out.index的文件中,“2”就是当前Spill的次数。
1 if (totalIndexCacheMemory >= indexCacheMemoryLimit) {
2
3 // create spill index file
4
5 Path indexFilename =
6
7 mapOutputFile.getSpillIndexFileForWrite(numSpills, partitions 8 9 * MAP_OUTPUT_INDEX_RECORD_LENGTH); 10 11 spillRec.writeToFile(indexFilename, job); 12 13 } else { 14 15 indexCacheList.add(spillRec); 16 17 totalIndexCacheMemory += 18 19 spillRec.size() * MAP_OUTPUT_INDEX_RECORD_LENGTH; 20 21 }
index文件中不光存储了索引数据,还存储了crc32的校验数据。index文件不一定在磁盘上创建,如果内存(默认1M空间)中能放得下就放在内存中。
out文件、index文件和partition数据文件的对应关系为:
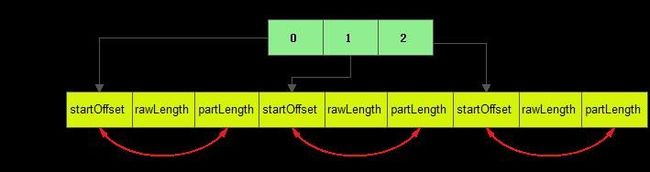
索引文件的信息主要包括partition的元数据的偏移量、大小、压缩后的大小等。
Step6:
Spill结束的时候,会调用resetSpill方法进行重置。
1 private void resetSpill() {
2
3 final int e = equator; 4 5 bufstart = bufend = e; 6 7 final int aligned = e - (e % METASIZE); 8 9 // set start/end to point to first meta record 10 11 // Cast one of the operands to long to avoid integer overflow 12 13 kvstart = kvend = (int) 14 15 (((long)aligned - METASIZE + kvbuffer.length) % kvbuffer.length) / 4; 16 17 LOG.info("(RESET) equator " + e + " kv " + kvstart + "(" + 18 19 (kvstart * 4) + ")" + " kvi " + kvindex + "(" + (kvindex * 4) + ")"); 20 21 }
也就是取kvbuffer中剩余空间的中间位置,用这个位置设置为新的分界点。
4.3.5 合并
Map任务如果输出数据量很大,可能会进行好几次Spill,out文件和Index文件会产生很多,分布在不同的磁盘上。这时候就需要merge操作把这些文件进行合并。
Merge会从所有的本地目录上扫描得到Index文件,然后把索引信息存储在一个列表里,最后根据列表来创建一个叫file.out的文件和一个叫file.out.Index的文件用来存储最终的输出和索引。
每个artition都应一个段列表,记录所有的Spill文件中对应的这个partition那段数据的文件名、起始位置、长度等等。所以首先会对artition对应的所有的segment进行合并,合并成一个segment。当这个partition对应很多个segment时,会分批地进行合并,类似于堆排序。最终的索引数据仍然输出到Index文件中。对应mergeParts方法。
4.3.6 相关配置选项
Map的东西大概的就这么多。主要是读取数据然后写入内存缓冲区,缓存区满足条件就会快排,并设置partition,然后Spill到本地文件和索引文件;如果有combiner,Spill之前也会做一次聚集操作,等数据跑完会通过归并合并所有spill文件和索引文件,如果有combiner,合并之前在满足条件后会做一次综合的聚集操作。map阶段的结果都会存储在本地中(如果有reducer的话),非HDFS。
在上面的分析,包括过程的梳理中,主要涉及到以下几种配置选项:
mapreduce.job.map.output.collector.class,默认为MapTask.MapOutputBuffer;
mapreduce.map.sort.spill.percent配置内存开始溢写的百分比值,默认为0.8;
mapreduce.task.io.sort.mb配置内存bufer的大小,默认是100mb;
map.sort.class配置排序实现类,默认为QuickSort,快速排序;
mapreduce.map.output.compress.codec配置map的输出的压缩处理程序;
mapreduce.map.output.compress配置map输出是否启用压缩,默认为false
-------------------------------------------------------------------------------
如果您看了本篇博客,觉得对您有所收获,请点击右下角的 [推荐]
如果您想转载本博客,请注明出处
如果您对本文有意见或者建议,欢迎留言
感谢您的阅读,请关注我的后续博客