CVPR 2012 just ended in Providence and I wanted to quickly summarize some of my personal highlights, lessons and thoughts.
FREAK: Fast Retina Keypoint
FREAK is a new orientation-invarient binary descriptor proposed by Alexandre Alahi et al. It can be extracted on a patch by comparing two values in the gaussian pyramid to get every bit, similar to BRIEF. They show impressive results for discriminative power, speed, and also draw interesting connections to a model of early visual processing in the retina. Major bonus points are awarded for a beautiful
C++ Open Source OpenCV compatible implementation on Github.
Philosophically and more generally, I have become a big fan of binary descriptors because they are not wasteful, in the sense that every single bit is utilized to its full potential and nothing is wasted describing the 10th decimal place. They also enable lightning-fast computation on some architectures. I'm looking forward to running a few experiments with this!
Tracking & SVMs for binary descriptors
Suppose you want to track a known object over time in an image stream. A standard way to do this would be to compute features keypoints on the object image (using SIFT-like keypoints, say), and use RANSAC with some distance metric to robustly estimate the homography to the keypoints in the scene. Simply doing this per frame can do a decent job of detecting the object, but in the tracking scenario you can do much better by training a discriminative model (an SVM, for example) for every keypoint, where you mine negative examples from patches in the scene that are everywhere around the keypoint. This has been established in the past, for example in the
Predator system.
But now suppose you have binary descriptors, such as FREAK above. Normally it is lightning fast to compute hamming distances on these, but suddenly you have an SVM with float weights, so we're back to slow dot products, right? Well, not necessarily thanks to this trick I noticed in this [
Efficient Online Structured Output Learning for Keypoint-Based Object Tracking [pdf]] paper. The idea is to train the SVM as normal on the bit vectors, but then approximate the trained weights as a linear combination of some binary basis vectors. In practice, you can use around 2 or 3 bit vectors that, when appropriately combined with (fast) bitwise operations and linear combinations thereafter produce a result that approximates the full dot product. The end result is that you can use a discriminative model with binary vectors and enjoy all the benefits of fast binary operations. All this comes at a small cost of accuracy due the approximation, but in practice it looks like this works!
Hedging your bets: richer outputs
I'd like to see more papers such as
"Optimizing Accuracy-Specificity Trade-offs in Large Scale Visual Recognition" from Jia Deng. Jia works a lot with ImageNet, and working with these large datasets demands more interesting treatment of object categories than 1-of-K labels. The problem is that in almost all recognition tasks we work with rather arbitrarily chosen concepts that lazily slice through an entire rich, complex object hierarchy that contains a lot of compositional structure, attributes, etc. I'd like to see more work that acknowledges this aspect of the real world.
In this work, an image recognition system is described that can analyze an input image at various levels of confidence and layers of abstraction. For example if you provide an image of a car, it may tell you that it is 60% sure it's a Smart Car, 90% sure it is a car, 95% that it is a vehicle, and 99% sure that it is an entity (the root node in the ImageNet hierarchy). I like this quite a lot philosophically, and I hope to see other algorithms that strive for richer outputs and predictions.
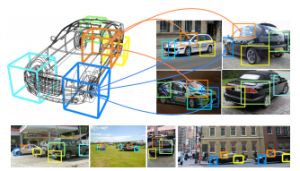
Speaking of rich outputs, I was pleased to see a few papers (such as the one above, from Pepik et al.) that try to go beyond bounding boxes, or even pixel-wise labelings. If we hope to build models of scenes in all their complexity, we will have to reason about all the contents of a scene and their spatial relationships in the true, 3D world. It should not be enough to stop at a bounding box. This particular paper improves only a tiny bit on previous state of the art though, so my immediate reaction (since I didn't fully read the paper) is that there is more room for improvement here. However, I still like the philosophy.

100Hz pedestrian detection
This paper [pdf] by Rodrigo Benenson presented a very fast pedestrian detection algorithm. The author claimed at the oral that they can run the detector at 170Hz today. The detector is based on simple HOG model, and the reason they are able to run at such incredibly high speeds is that they use a trick from Piotr Dollar's paper[The fastest detector in the west [pdf]] that shows how you can closely approximate features between scales. This allows them to train only a small set of svm models at different scales, but crucially they can get away with only computing the HOG features on a single scale.

Steerable Part Models
Here's the problem: DPM model has all these part filters that you have to slide through your images, and it can get expensive as you get more and more parts for different objects, etc. The idea presented in
this paper by Hamed Pirsiavash is to express all parts as a linear combination of a few basis parts. At test time, simply slide basis parts through the image and compute the outputs for all parts using the appropriately learned coefficients. The basis learning is very similar to sparse coding, where you iteratively solve convex problems holding some variables fixed. The authors are currently looking into using Sparse Coding as an alternative as well.
I liked this paper because it has strong connections to Deep Learning methods. In fact, I think I can express this model's feed forward computation as something like a Yann LeCun style convolutional network, which is rather interesting. The steps are always the same: filtering (AND), concatenation, normalizing & pooling (OR), alternating. For example, a single HOG cell is equivalent to filtering with gabors of 9 different directions, followed by normalization and average pooling.
Neural Networks: denoising and misc thoughts
This paper [
Image denoising: Can plain Neural Networks compete with BM3D? [pdf]] by Harold C. Burger shows that you can train a Multi Layer Perceptron to do image denoising (including, more interestingly, JPEG artifact "noise" when using high compression) and it will work well if your MLP is large enough, if you have a LOT of data, and if you are willing to train for a month. What was interesting to me was not the denoising, but my brief meditation after I saw the paper on strengths and weaknesses of MLPs in general. This might be obvious, but it seems to me that MLP's excel at tasks where N >> D (i.e. much much more data than dimension) and especially when you can afford the training time. In these scenarios, MLP essentially parametrically encodes the right answer for every possible input. In other words, in this limit MLP becomes almost like a nearest neighbor regressor, except it is parametric. I think. Purely a speculation :)
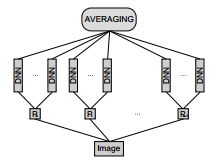
Neural Networks and Averaging
Here's a fun paper: "
Multi-column Deep Neural Networks for Image Classification". What happens when you train a Yann LeCun style NN on CIFAR-10? You get about 16% error. If you retrain the network 8 times from different initializations, you consistently get about the same 16% result. But if you take these 8 networks and average their output you get 11%. You have to love model averaging...
Basically what I think is going on is that every network by itself covers the data with the right label, but also casts projections over the entire space outside of training instances that are all essentially of random label. However, if you have 8 such networks that all cast different random labels outside of the data, averaging their outputs washes out this effect and regularizes the final prediction. I suppose this is all just a complicated way of thinking about overfitting. There must be some interesting theory surrounding this.
Conditional Regression Forests for Human Pose Estimation
This is just an obligatory mention of this new
Random forests paper, where Microsoft improves on their prior work in pose estimation from a depth image. The reason for this is that I'm currently in love with Random Forests philosophically, and I wish they were more popular as they are beautiful, elegant, super efficient and flexible models. They are certainly very popular among data scientists (for example, they are now used as _the_ blackbox baseline for many competitions at Kaggle), but they don't get mentioned very often in academia or courses and I'm trying to figure out why. Anyway, in this paper they look at how one can better account for the variation in height and size of people.
This paper shows that patch level segmentation is basically a solved problems, and humans perform on par with our best algorithms. It is when you give people context of the entire image when they start to outperform the algorithms. I thought this was rather obvious, but the paper offers some quantitative support and they had cool demo at the poster.
This was an oral by Antonio Torralba that demonstrated a cool CSI style image analysis. Basically, if you have a video of a scene and someone occludes the source of light, they can become an accidental anti-pinhole, which lets you reconstruct the image of the scene behind the camera. Okay, this description doesn't make sense but it's a fun effect.
This paper has a lot of very interesting tips and tricks for dealing with large datasets. Definitely worth at least a skim. I plan to go through this myself in detail when I get time.
Misc notes
- There was a Nao robot that danced around in one of the demo rooms. I got the impression that they are targeting more of a K12 education with the robot, though.
- We had lobster for dinner. I felt bad eating it because it looked too close to alive.
- Sebastian Thrun gave a good talk on self driving car. I saw most of it before in previous talks on the same subject, and I can now reliably predict most of his jokes :D
- They kept running out of coffee throughout the day. I am of the opinion that coffee should never be sacrificed :(
I invite thoughts, and let me know if I missed something cool!