mysql基本介绍和优化技巧
一. mysql框架和基本介绍
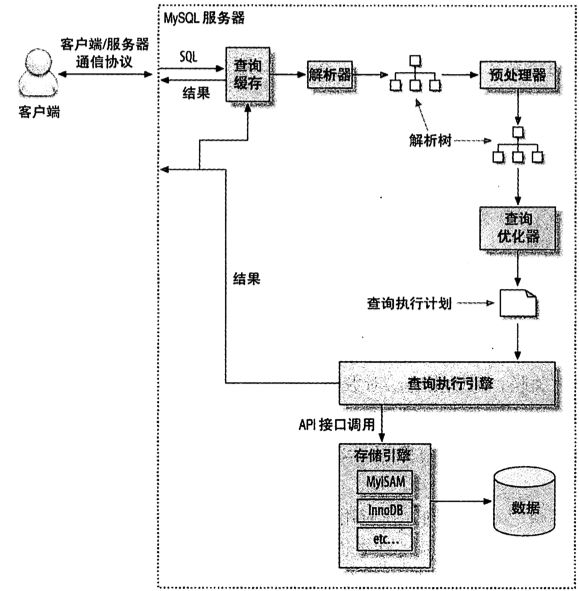
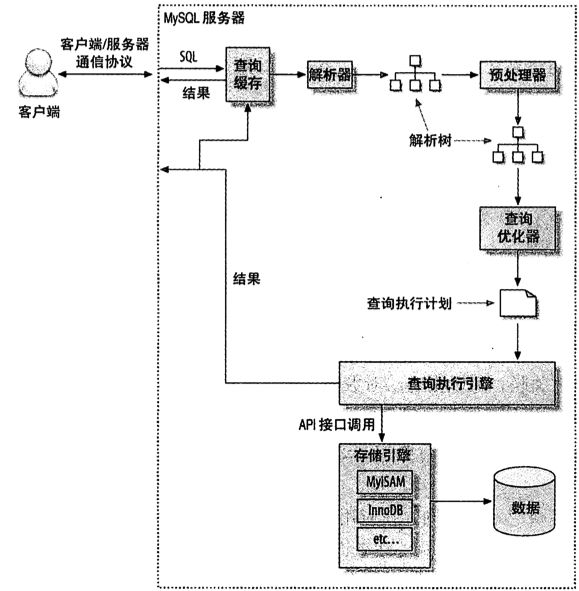
1. 框架图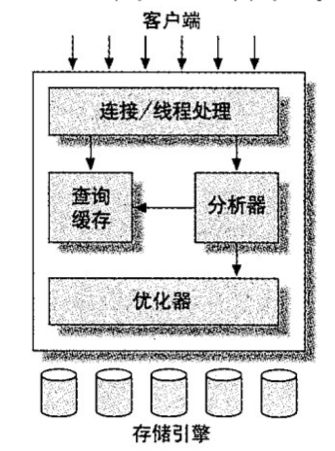
更详细:
2. 存储引擎
MYISAM与INNODB对比:
MYISAM:mysql5.1及以前版本的默认存储引擎。支持全文检索,压缩,表级锁等,但不支持事务,行级锁,崩溃后的数据恢复等
INNODB:mysql5.5及之后的默认存储引擎。支持事务,行级锁,数据恢复,mysql5.6 中的innodb(1.2)支持全文检索。
如何选择:innodb对于绝大多数的用户都是最佳的选择,除非某些存储引擎能满足特殊需求且使用者很了解这种存储引擎。
二. 查询性能的方法
1. 配置文件 my.cnf (linux),
读配置文件的一般顺序:
1) /etc/my.cnf
2) DATADIR/my.cnf
3) ~/.my.cnf
可以通过命令获知:
mysqld --verbose --help | grep -A 1 'Default options’
结果:
/etc/my.cnf /etc/mysql/my.cnf /usr/local/mysql/etc/my.cnf ~/.my.cnf
2. 环境变量
从my,cnf读取环境变量值,
查看变量值方法: show variables like “”, (不清楚变量名时,用模糊匹配%)
例如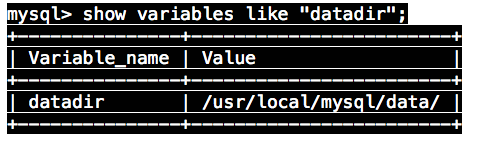
设置(全局)变量方法:
set (global) 变量名=变量值
例如设置 开启慢查询日志
set global slow_query_log=1;
设置后查看变量值
show variables like "%slow%”;
| slow_query_log | ON
变量列表:http://dev.mysql.com/doc/refman/5.6/en/mysqld-option-tables.html
分析sql语句时一些有用且默认不开启的变量:
1) 慢查询日志: 开关 slow_query_log, 阈值:long_query_time (单位 秒)
2) sql剖析工具profile,开关:profiling,历史记录数:profiling_history_size(最大为100)
3) 记录每条sql语句,开关:general_log, log文件位置:general_log_file
… …
3. 查看sql服务状态
语法 SHOW [GLOBAL | SESSION] STATUS [LIKE 'pattern' | WHERE expr]清除状态 FLUSH STATUS;
清除表缓存
reset query cache ;
FLUSH TABLE [TABLE NAME]
用法举例
FLUSH STATUS;
SELECT ...;
SHOW SESSION STATUS LIKE 'Handler_read%’; (SHOW SESSION STATUS LIKE 'Handler_%’;)
EXPLAIN SELECT …;
具体参数可以参考:
http://lxneng.iteye.com/blog/451985
http://hi.baidu.com/thinkinginlamp/item/8d038333c6b0674a3075a1d3
4. 查询剖析工具 show profiles
开启
set profiling=1;
set profiling_history_size=50 最大为100
用法:
show profiles;
show profile; //展示最后一条query时间消耗
show profile for query ID; // 替换ID值 从show profiles 表里。
显示更多内容
show profile cpu,block io for query 4;
5. 获取查询计划的信息 explain
用法 explain [sql查询语句]
例如:
注意每列的含义
三. 数据类型优化
1. 选择优化的数据类型原则
1)尽量使用可以正确存储数据的最小数据类型。例如: 只存0-200,用tinyint unsigned 更好。
2)选择简单的数据类型。例如整形比字符操作代价更低,存储时间用datetime而不是字符串,用整形存储ip。
2. 数据类型(主要说整形和字符串)
1)整型
TINYINT 1 字节 (-128,127) (0,255) 小整数值
SMALLINT 2 字节 (-32 768,32 767) (0,65 535) 大整数值
MEDIUMINT 3 字节 (-8 388 608,8 388 607) (0,16 777 215) 大整数值
INT或INTEGER 4 字节 (-2 147 483 648,2 147 483 647) (0,4 294 967 295) 大整数值
BIGINT 8 字节 (-9 233 372 036 854 775 808,9 223 372 036 854 775 807) (0,18 446 744 073 709 551 615) 极大整数值
思考:tinyint(1)和tinyint(2)存储空间相比较?
2)字符串
varchar:内容+长度,0-255字节。
char:长度不足时,空格补足,0-255字节。
如何选择:
选择用varchar:字符串的最大长度比平均长度大很多,列更新少。但是一定要估算好长度(排序时)。
text和blob,大数据类型。
3)浮点,时间,位 等
四. 高性能索引
1. 索引基础
索引结果为B+树。
B树:
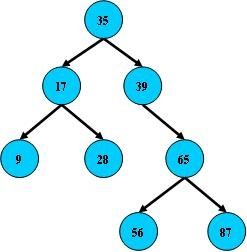
B-树:
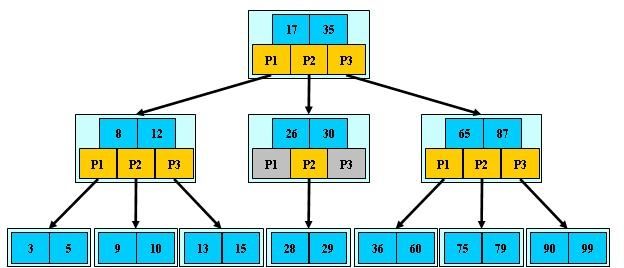
B+树:
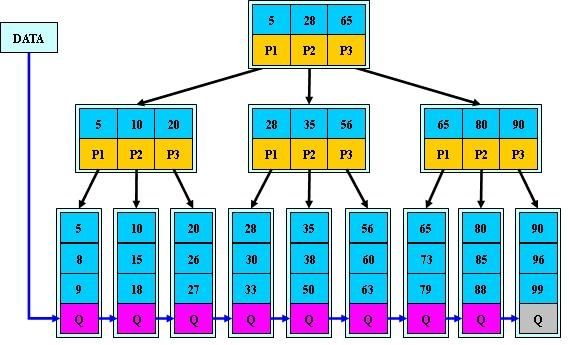
MYISAM 主索引(辅助索引结构与其相同):
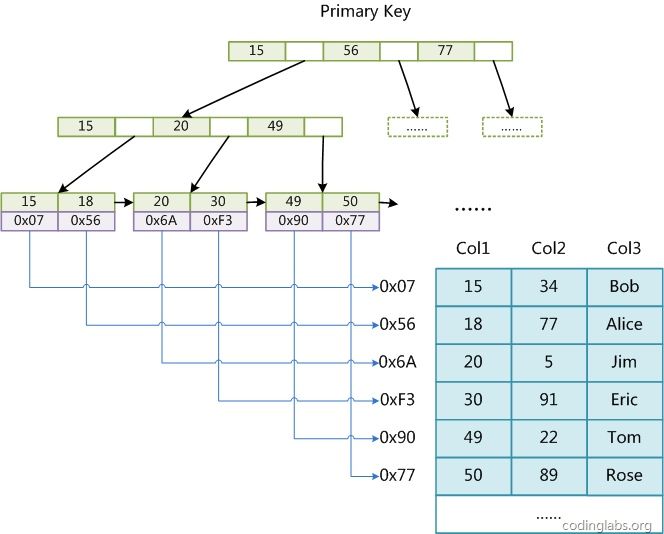
INNODB 主索引:
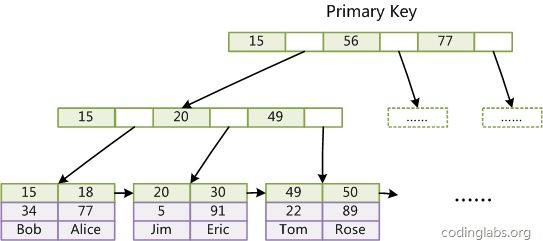
INNODB辅助索引:
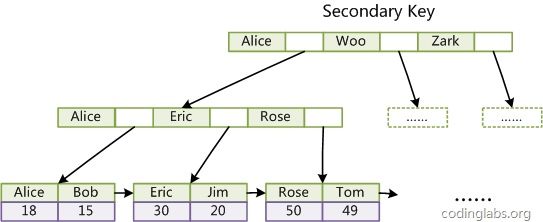
索引优点:
1) 索引大大减少了服务器需要扫描的数据量;
2) 索引可以帮助服务器避免排序和临时表;
3) 索引可以将随机I/O变为顺序I/O。
2. 高性能索引策略
1) 独立的列
将索引单独放到比较符号的一侧,否则无法利用索引。
2)前缀索引和索引选择性

3)合适的索引顺序
4)覆盖索引
极大的提高性能。
5)使用索引扫描做排序
其他策略:
1)多条件过滤,尽量重复利用索引,(sex,country,age)有索引,现在有查询条件 sex,country,region,age 或者sex,country,region,city,age需要再建索引吗?
例如:(gender,name) gender,gender name
select * from staff where name like “123”;
select * from staff where gender in (0,1) and name like “123";
2) 避免多个范围查询
3)延迟关联
select * from table2 order by cnt,id limit 100000,10;
select * from table2 join (select id from table2 order by cnt limit 100000,10) as x using(id) ;
五. 查询性能优化
1) 查询执行的基础
2) 查询优化器的局限性
union限制
(select first_name,last_name from actor order by last_name) union (select first_name,last_name from customer order by last_name) order by last_name limit 20;
(select first_name,last_name from actor order by last_name limit 20) union (select first_name,last_name from customer order by last_name limit 20) order by last_name limit 20 ;
在同一个表上查询和更新
update foo as outer set cnt= (select count(*) from foo as inner where inner.type=outer.type);
update foo join (select type,count(*) as cnt from foo group by type) as der using(type) set foo.cnt=der.cnt;
3)优化特定关联查询
优化关联:
explain select * from film inner join (film_actor,actor) on (film.film_id = film_actor.film_id and film_actor.actor_id = actor.actor_id); explain select straight_join * from film inner join (film_actor,actor) on (film.film_id = film_actor.film_id and film_actor.actor_id = actor.actor_id);
优化limit
优化sql_calc_found_rows
select sql_calc_found_rows * from table2 order by cnt,id limit 100000,10;
select found_rows();
selelt count(*) from table ..