SQL进阶提升(疑惑篇order by)-学习sql server2005 step by step(十一)
这篇主要发出两个疑惑,希望有兴趣的人解答,谢谢!
1.newid()疑惑
1 create table tb (aa int,bb char(1 ))
2 insert tb values(1,'A' )
3 insert tb values(1,'B' )
4 insert tb values(1,'C' )
5 insert tb values(1,'D' )
6
7 insert tb values(2,'E' )
8 insert tb values(2,'F' )
9 insert tb values(2,'G' )
10 insert tb values(2,'H' )
11
12 insert tb values(3,'I' )
13 insert tb values(3,'J' )
14 insert tb values(3,'K' )
15 insert tb values(3,'L' )
16 ------
17 --SQL1
18 SELECT * FROM tb a
19 WHERE bb IN
20 (
21 SELECT TOP 1 bb FROM tb
22 WHERE aa= a.aa
23 ORDER BY NEWID ()
24 )
25
26 --SQL2
27 SELECT * FROM tb a
28 WHERE bb =
29 (
30 SELECT TOP 1 bb FROM tb
31 WHERE aa= a.aa
32 ORDER BY NEWID ()
33 )
34
35 drop table tb
多次运行查询语句,运行后看到=与in的区别,用in的时候得出的结果行数会变化,可能是一行,可能是多行,但是用=的时候始终产生得到三行结果
查看了执行计划
--SQL1的执行计划是
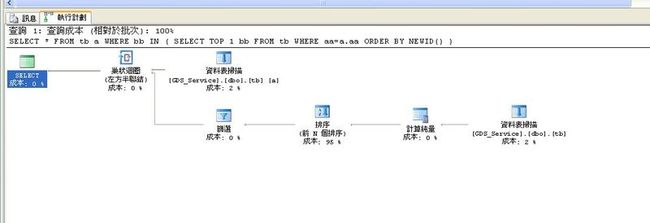
--SQL2的执行计划是

希望有人能够详细讲解一下
2.select与order by的冲突
使用 SELECT 语句,轮询表中的数据,并且处理变量数据时,如果有ORDER BY语句,则得不到想要的结果,但去掉ORDER BY,结果正常。
具体的问题表现参考下面的问题重现代码
问题重现代码
1 -- 测试数据
2
3 DECLARE @T TABLE (id int ,value nvarchar ( 16 ))
4
5 INSERT INTO @T SELECT
6
7 1 , N ' 好人 ' UNION ALL SELECT
8
9 2 , N ' 坏人 ' UNION ALL SELECT
10
11 3 , N ' 吃饭 ' UNION ALL SELECT
12
13 4 , N ' 垃圾 '
14
15
16
17 -- 赋值处理
18
19 DECLARE @str nvarchar ( 4000 )
20
21 SET @str = N ' 我不是一个好人,也不是垃圾 '
22
23 SELECT @str = REPLACE ( @str , value, N ' <u> ' + value + N ' </u> ' )
24
25 FROM @T
26
27 WHERE CHARINDEX (value, @str ) > 0
28
29 -- ORDER BY CHARINDEX(value, @str) DESC
30
31 SELECT @str
32
33
34
35 /* -- 结果(当赋值处理语句注释掉ORDER BY 时)
36
37 我不是一个<u>好人</u>,也不是<u>垃圾</u>
38
39 -- */
40
41
42
43 /* -- 结果(当赋值处理语句加上ORDER BY 时)
44
45 我不是一个<u>好人</u>,也不是垃圾
46
47 -- */
48
问题分析:
问题分析:
两个处理语句的结果不同,通过查看它们的执行计划应该可以看出原因所在,为此,通过
SET SHOWPLAN_ALL ON
输出了两种执行语句的执行计划(仅StmtText部分,有兴趣的读者在自己的电脑上测试的时候,可以去了解其他部分的信息)
StmtText
Step
DECLARE @str nvarchar(4000) SET @str = N'我不是一个好人,也不是垃圾'
SELECT @str = REPLACE(@str, value, N'<u>' + value + N'</u>') FROM @T WHERE CHARINDEX(value, @str) > 0
4
|--
Compute Scalar(DEFINE:([Expr1002]=replace([@str], @T.[value], '<u>'+@T.[value]+'</u>')))
3
|--
Filter(WHERE:(charindex(@T.[value], [@str], NULL)>0))
2
|--
Table Scan(OBJECT:(@T))
1
DECLARE @str nvarchar(4000) SET @str = N'我不是一个好人,也不是垃圾'
SELECT @str = REPLACE(@str, value, N'<u>' + value + N'</u>') FROM @T WHERE CHARINDEX(value, @str) > 0 ORDER BY CHARINDEX(value, @str) DESC
5
|--
Sort(ORDER BY:([Expr1003] DESC))
4
|--
Compute Scalar(DEFINE:([Expr1002]=replace([@str], @T.[value], '<u>'+@T.[value]+'</u>'), [Expr1003]=charindex(@T.[value], [@str], NULL)))
3
|--
Filter(WHERE:(charindex(@T.[value], [@str], NULL)>0))
2
|--
Table Scan(OBJECT:(@T))
1
从上面的列表可以看出,两种处理的最大差异,在于赋值前,是否有ORDER BY 子句,从一般的理解上,可能会认为是否排序并不重要,但换个角度来看问题,就比较容易理解为什么有ORDER BY子句后得不到我们想要的结果了:
当有ORDER BY子句时,对于SELECT @str = 这种赋值处理,SQL Server认为赋值处理肯定只会保留最后一条记录的处理结果,而ORDER BY子句确定了数据顺序,也就知道最后一条记录是那个,因此只会处理ORDER BY的最后一条记录。(读者可以自行去测试一下,调整ORDER BY顺序,看看结果是否与我的推论相符)
当没有ORDER BY子句时,因为无法确定数据顺序,所以SQL Server必须扫描满足条件的每条数据来得到结果,这样每扫描一条记录都会处理一次,所以结果是我们所预知的
问题解决方法:
修改处理语句,使查询优化器使用与我们需要结果一致的执行方法,可以解决这个问题。
对于示例中的处理语句,可以调整如下:
1 DECLARE @str nvarchar ( 4000 )
2
3 SET @str = N ' 我不是一个好人,也不是垃圾 '
4
5 SELECT @str = REPLACE ( @str , value, N ' <u> ' + value + N ' </u> ' )
6
7 FROM (
8
9 SELECT TOP 100 PERCENT
10
11 value
12
13 FROM @T
14
15 WHERE CHARINDEX (value, @str ) > 0
16
17 ORDER BY CHARINDEX (value, @str ) DESC
18
19 )A
20
21 SELECT @str
22
希望大家踊跃参与解答。