XMLDOM初学笔记(三)
【本文是在阅读www.w3school.com.cn的教程时随手记下的内容,以免遗忘】
属性和方法向 XML DOM 定义了编程接口。
编程接口
DOM 把 XML 模拟为一系列节点接口。可通过 JavaScript 或其他编程语言来访问节点。在本教程中,我们使用 JavaScript。
对 DOM 的编程接口是通过一套标准的属性和方法来定义的。
属性经常按照"某事物是什么"的方式来使用(例如节点名是 "book")。
方法经常按照"对某事物做什么"的方式来使用(例如删除 "book" 节点)。
XML DOM 属性
一些典型的 DOM 属性:
- x.nodeName - x 的名称
- x.nodeValue - x 的值
- x.parentNode - x 的父节点
- x.childNodes - x 的子节点
- x.attributes - x 的属性节点
注释:在上面的列表中,x 是一个节点对象。
XML DOM 方法
- x.getElementsByTagName(name) - 获取带有指定标签名称的所有元素
- x.appendChild(node) - 向 x 插入子节点
- x.removeChild(node) - 从 x 删除子节点
注释:在上面的列表中,x 是一个节点对象。
实例
从 books.xml 中的 <title> 元素获取文本的 JavaScript 代码:
 txt
=
xmlDoc.getElementsByTagName(
"
title
"
)[
0
].childNodes[
0
].nodeValue
txt
=
xmlDoc.getElementsByTagName(
"
title
"
)[
0
].childNodes[
0
].nodeValue
在此语句执行后,txt 保存的值是 "Everyday Italian"。
解释:
- xmlDoc - 由解析器创建的 XML DOM
- getElementsByTagName("title")[0] - 第一个 <title> 元素
- childNodes[0] - <title> 元素的第一个子节点 (文本节点)
- nodeValue - 节点的值 (文本自身)
访问节点
您可以通过三种方法来访问节点:
- 通过使用 getElementsByTagName() 方法
- 通过循环(遍历)节点树
- 通过利用节点的关系在节点树中导航
getElementsByTagName() 方法
getElementsByTagName() 返回拥有指定标签名的所有元素。
语法
node.getElementsByTagName(
"
tagname
"
);
实例
下面的例子返回 x 元素下的所有 <title> 元素:
x.getElementsByTagName(
"
title
"
);
请注意,上面的例子仅返回 x 节点下的 <title> 元素。要返回 XML 文档中的所有 <title> 元素,请使用:
xmlDoc.getElementsByTagName(
"
title
"
);
在这里,xmlDoc 就是文档本身(文档节点)。
DOM Node List
getElementsByTagName() 方法返回节点列表 (node list)。节点列表是节点的数组。
下面的代码通过使用 loadXMLDoc() 把 "books.xml" 载入 xmlDoc 中,然后在变量 x 中存储 <title> 节点的一个列表:
xmlDoc
=
loadXMLDoc(
"
books.xml
"
); x
=
xmlDoc.getElementsByTagName(
"
title
"
);
可通过下标访问 x 中的 <title> 元素。要访问第三个 <title>,您可以编写:
y
=
x[
2
];
注释:下标以 0 起始。
DOM Node List Length
length 属性定义节点列表的长度(即节点的数目)。
您能够通过使用 length 属性来循环一个节点列表:
xmlDoc
=
loadXMLDoc(
"
books.xml
"
); x
=
xmlDoc.getElementsByTagName(
"
title
"
);
for
(i
=
0
;i
<
x.length;i
++
)  {
{ 

 document.write(x[i].childNodes[0].nodeValue); document.write("<br />");
document.write(x[i].childNodes[0].nodeValue); document.write("<br />"); 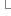 }
}
Node Type
XML 文档的 documentElement 属性是根节点。
节点的 nodeName 属性是节点的名称。
节点的 nodeType 属性是节点的类型。
遍历节点
下面的代码循环根节点的子节点,同时也是元素节点:
xmlDoc
=
loadXMLDoc(
"
books.xml
"
); x
=
xmlDoc.documentElement.childNodes;
for
(i
=
0
;i
<
x.length;i
++
)
{ if (x[i].nodeType==1)  {//Process only element nodes (type 1)
{//Process only element nodes (type 1)  document.write(x[i].nodeName); document.write("<br />");
document.write(x[i].nodeName); document.write("<br />"); 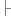 } }
} }
利用节点的关系进行导航
下面的代码通过利用节点的关系在节点树中进行导航:
xmlDoc
=
loadXMLDoc(
"
books.xml
"
); x
=
xmlDoc.getElementsByTagName(
"
book
"
)[
0
].childNodes; y
=
xmlDoc.getElementsByTagName(
"
book
"
)[
0
].firstChild;
for
(i
=
0
;i
<
x.length;i
++
)
{ if (y.nodeType==1) {//Process only element nodes (type 1) document.write(y.nodeName + "<br />"); } y=y.nextSibling; }