

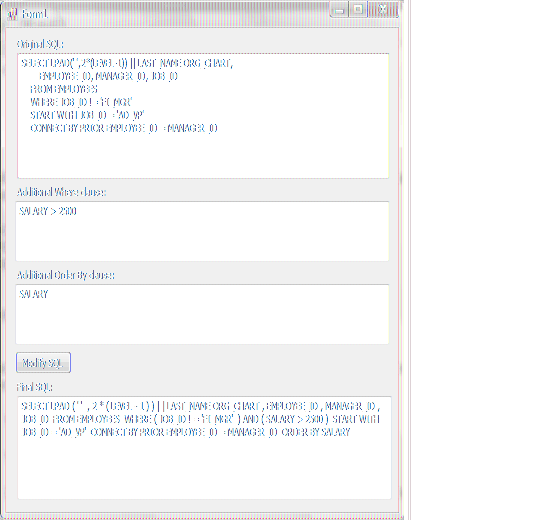
Introduction
Sometimes it is necessary to apply a custom filter to an existing SQL query (to perform search by a custom criteria) or to order the query results depending on the user action (when you work with large amounts of data and display only a small part of it to the user, such as displaying only N first records). I faced this problem while implementing a reusable control for searching. In this control the user should be able to specify a filter and order the search results as he needs. A SQL query is specified in the control’s data source and it can contain any parts including sub-queries. In this case it is not enough just to add a custom ‘where’ clause to the end of the query as it may already contain parts which should follow the where clause according to the SQL syntax. This article describes a simple SQL parser which allows you to add or modify the ‘where’ and ‘order by’ clauses of a SQL query (PL/SQL).
Background
Any document can be separated into tags (special words or specially formatted characters which have some extra meaning; it depends on the document format and task which sequence of character should be treated as a tag), words, separators (points, commas, braces, etc.), and white spaces. Tags can contain other elements such as sub-tags, words, etc. The parser presented in this article separates a text (sequence of characters) into elements mentioned above and builds a tree from them. Later this tree can be restructured, some its nodes can be changed or removed according to the task.
Every tag in the document is represented with a special class (every type of tag has its own class). While parsing a document, the parser reads the document symbol by symbol and determines whether the current sequence of characters is a tag or a simple text. If it is a tag, the parser creates an instance of the class which represents the tag.
Every class which describes a tag is derived from an abstract class named TagBase and has common information about the tag (whether it has contents, its type (string identifier), value, and whether it can be terminated by the end of the document (whether its ending should be specified explicitly)).The parser has a static set of classes (types) which correspond to the set of the tags of the document format (the Tags property). When the parser needs to determine whether there is a tag at the current position of the document, it enumerates through its collection of tag types. For every tag type (element in the collection) it requests a special attribute (derived from the MatchTagAttributeBaseclass). This attribute has a special method named Match, which returns a value indicating whether this type of tag is located at the specified position in the document. If so, the parser creates an instance of that class. After an instance of a tag class is created, it is converted into an XML node and then added into the XML tree which reflects the structure of the query.
Here is how a tag class declaration looks like:
[TagType(“STRING_LITERAL”)] [MatchStringLiteralTag] internal class StringLiteralTag : TagBase { ... } internal class MatchStringLiteralTagAttribute : MatchTagAttributeBase { public override bool Match(string sql, int position) { ... } }
Here is the class diagram of the tags used in the SQL parser:
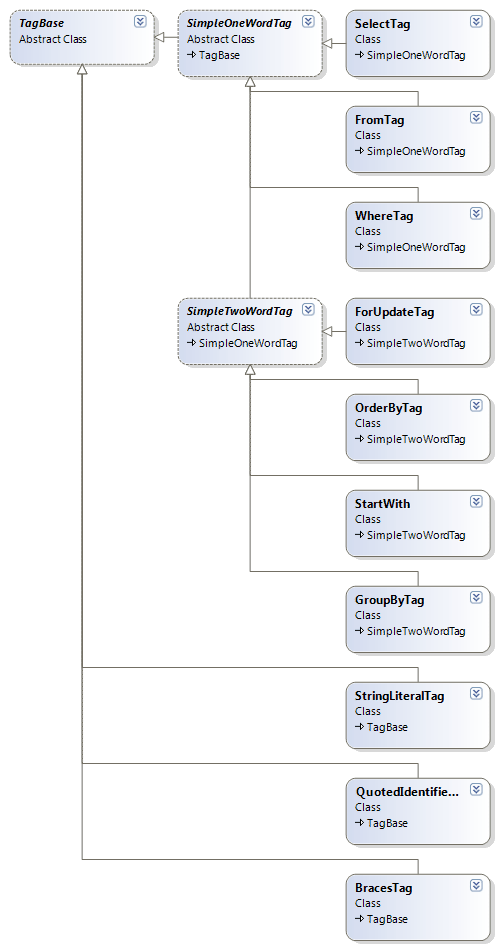
This list of tags does not include all the tags which may be present in a SQL query, it includes only those tags which are necessary for modifying the ‘where’ and ‘order by’ clauses of a query.
Using the Code
To modify a SQL query, you should first create an instance of the SqlParser class and then invoke its Parsemethod:
SqlParser myParser = new SqlParser(); myParser.Parse(mySqlQuery);
If you need to modify the ‘where’ clause, you should modify the WhereClause property of the parser:
string myOrginalWhereClause = myParser.WhereClause; if (string.IsNullOrEmpty(myOrginalWhereClause)) myParser.WhereClause = myAdditionalWhereClause; else myParser.WhereClause = string.Format("({0}) AND ({1})", myOrginalWhereClause, myAdditionalWhereClause);
If you need to modify the ‘order by’ clause, you should modify the OrderByClause property of the parser:
string myOrginalOrderByClause = myParser.OrderByClause; if (string.IsNullOrEmpty(myOrginalOrderByClause)) myParser.OrderByClause = myAdditionalOrderByClause; else myParser.OrderByClause = string.Format("{0}, {1}", myOrginalOrderByClause, myAdditionalOrderByClause);
After all the necessary modifications, you can get the final SQL query by using the ToText method:
myParser.ToText();
Ways to Make Code Faster
There are a few ways to make the code work faster. When the parser builds a tree, it uses the XmlDocument class. This is useful for debugging as we can save the tree to a file and then look through it with an internet browser or another tool. Also we can search certain nodes with the x-path syntax. But the parser will work faster if we make our own tree-like data structure without redundant functionality.
Also, it may be preferable not to use reflection as it is quite slow compared to other parser operations (the method which returns attributes of a class may be accessed thousands of times when parsing large documents). Instead we can make some data structures which will store metadata about tag classes. It is not so substantial for the SQL parser, but it may be much more substantial for parsers of large documents.