2_python进阶—闭包、迭代器、生成器、装饰器
文章目录
- 一、闭包
-
- 1.1 闭包的好处
- 1.2 检测闭包
- 1.3 问题,如何在函数外边调用内部函数呢?
- 二、迭代器
-
- 2.1 可迭代对象
- 2.2 dir()来查看一个对象
- 2.3 迭代器讲解
-
- 2.3.1 模拟for循环(重点)
- 2.4 迭代器与可迭代对象区别
-
- 2.4.1 方法一
- 2.4.2 方法二
- 2.4.3 判断文件句柄f是迭代器又是可迭代对象
- 2.5 迭代器特点
- 三、生成器
-
- 3.1 生成器的三种创建办法(Python)
- 3.2 return和yield区别
- 3.3 send()方法
-
- 3.3.1 send( )和__ next__区别
- 3.3.2 把生成器里面的东西转化成列表
- 3.4 生成器表达式(重要)( )
- 3.5 生成器表达式和列表推导式的区别
- 3.6 面试题
- 四、推导式(没有元组推导式)
-
- 4.1 列表推导式 [ ]
- 4.2 字典推导式{ }
- 4.3 集合推导式{ }
- 五、装饰器 property
一、闭包
- 什么是闭包?
- 内部函数访问外部函数的局部变量
def func():
name = "alex" # 常驻内存 防止其他程序改变这个变量
def inner():
print(name) # 在内层函数中调用了外层函数的变量,叫闭包, 可以让一个局部变量常驻内存
return inner
ret = func()
ret() # 执行的是inner()
ret()
alex
alex
1.1 闭包的好处
-
如果一个函数执行完毕,则这个函数中的变量以及局部命名空间中的内容都将会被销毁。
-
python规定,如果你在内部函数中访问了外层函数中的变量。那么这个变量将不会消亡,将会常驻在内存中。
-
也就是说:使用闭包,可以保证外层函数中的变量在内存中常驻。
-
综上,闭包的作用就是让一个变量能够常驻内存,供后面的程序使用。
from urllib.request import urlopen
def but():
content = urlopen("http://www.h3c.com/cn/").read()
def inner():
return content # 在函数内部使用了外部的变量 . 闭包
return inner
print("加载中........")
fn = but() # 这个时候就开始加载 h3c 的内容
# 后⾯需要⽤到这⾥⾯的内容就不需要在执⾏⾮常耗时的⽹络连接操作了
content = fn() # 获取内容
print(content)
content2 = fn() # 重新获取内容
print(content2)
1.2 检测闭包
- 使用
函数名.__closure__来检测函数是否是闭包。 - 返回cell是闭包
- 返回None不是闭包
def func1():
name = "alex"
def func2():
print(name) # 闭包
func2()
print(func2.__closure__)
func1()
alex
(,) |
1.3 问题,如何在函数外边调用内部函数呢?
def outer():
name = "alex"
# 内部函数
def inner():
print(name) # 闭包
return inner
fn = outer() # 访问外部函数,获取到内部函数的函数地址
fn() # 访问内部函数
# alex
那如果多层嵌套呢?很简单,只需要一层一层的往外层返回就行了
def func1():
def func2():
def func3():
print("hello")
return func3
return func2
func1()()()
# hello
二、迭代器
迭代器把可迭代对象中的内容一个一个从头到尾点一遍。
2.1 可迭代对象
# 可迭代对象: str, list, tuple, set, f文件, dict
# 上面可迭代对象中,只有 文件句柄f,range 是可迭代器。
# 所有的以上数据类型中都有一个函数__iter__(), 所有包含了__iter__()的数据类型都是可迭代的数据类型 Iterable
2.2 dir()来查看一个对象
# dir()来查看一个对象,数据类型中包含了哪些东西
lst = [1,2,3] # list
print(dir(lst))
print("__iter__" in dir(lst))
s = "王玛"
print("__iter__" in dir(s)) # 判断__iter__是否在dir()中,在True
2.3 迭代器讲解
# list是一个Iterable.可迭代的
lst = ["小白", "小花", "小紫", "小红"]
it = lst.__iter__() # 获取迭代器
# 迭代器往外拿元素. __next__()
print(it.__next__()) # 小白
print(it.__next__()) # 小花
print(it.__next__()) # 小紫
print(it.__next__()) # 小红
print(it.__next__()) # 迭代到最后一个元素之后. 再进行迭代就报错了
2.3.1 模拟for循环(重点)
lst = ["小白", "小花", "小紫", "小红"]
# 模拟for循环
it = lst.__iter__() # 获取迭代器
while True:
try:
name = it.__next__()
print(name)
except StopIteration: # 拿完了
break
# 小白
# 小花
# 小紫
# 小红
2.4 迭代器与可迭代对象区别
- 迭代器一定是可迭代对象
- 可迭代对象不一定是迭代器
2.4.1 方法一
lst = [1, 2, 3]
it = lst.__iter__()
print("__iter__" in dir(lst)) # 确定是一个可迭代的 True
print("__next__" in dir(lst)) # 确定不是一个迭代器 False
2.4.2 方法二
lst = [1, 2, 3]
from collections import Iterable # 可迭代的
from collections import Iterator # 迭代器
# isinstence(对象, 类型) 判断xx对象是否是xxx类型的
print(isinstance(lst, Iterable)) # True
print(isinstance(lst, Iterator)) # False
it = lst.__iter__()
print(isinstance(it, Iterable)) # 判断是否是可迭代的 迭代器一定是可迭代的 True
print(isinstance(it, Iterator)) # 迭代器里面一定有__next__(), __iter__() True
2.4.3 判断文件句柄f是迭代器又是可迭代对象
f = open("01 今日内容大纲", mode="r", encoding="utf-8")
print(isinstance(f, Iterable)) # True
print(isinstance(f, Iterator)) # True
2.5 迭代器特点
-
Iterable:可迭代对象. 内部包含
__iter__( )函数 -
Iterator:迭代器.内部包含
__iter__( )同时包含__next__(). -
迭代器的特点:
- 1.节省内存.
- 2.惰性机制
- 3.不能反复,只能向下执行.
三、生成器
- 生成器的本质就是迭代器
- 生成器要值的时候才取值
3.1 生成器的三种创建办法(Python)
1.通过生成器函数
2.通过生成器表达式创建生成器
3.通过数据转换
1、生成器函数:
函数中包含了yield的就是生成器函数
注意:生成器函数被执行. 获取到的是生成器. 而不是函数的执行
2、生成器表达式:
(结果 for 变量 in 可迭代对象 if 条件筛选)
取值:
1. __next__()
2. send(值) 给上一个yield位置传一个值, 第一个和最后一个yield不用传值
3. 可以for循环
4. list(g)
3. 各种推倒式和生成器表达式(没有元组推导式)
1. 列表推倒式 [结果 for 变量 in 可迭代对象 if 筛选]
2. 字典推倒式 {结果 for 变量 in 可迭代对象 if 筛选} 结果=>key:value
3. 集合推倒式 {结果 for 变量 in 可迭代对象 if 筛选} 结果=>key
3.2 return和yield区别
def func():
print("111")
return 222
ret = func() # ret = 222
print(ret)
# 111
# 222
将函数中的return换成yield就是生成器
def func():
print("111")
yield 222 # 函数中包含了yield, 当前这个函数就不再是普通的函数了. 是生成器函数
ret = func()
print(ret)
#结果: 以下是生成器
def func():
print("111")
yield 222
gener = func() # 这个时候函数不会执行,而是获取/创建生成器
ret = gener.__next__() # 这个时候函数才会执行,yield的作用和return一样,也是返回 # 222
print(ret)
def func():
print("我是周周")
yield "昆昆" # 函数中包含了yield, 当前这个函数就不再是普通的函数了. 是生成器函数
print("我是王力")
yield "李云???"
# print("你好啊") # 最后一个yield之后如果再进行__next__() 会报错
g = func() # 通过函数func()来创建一个生成器
print(g.__next__()) #执行: 周周,昆昆
print(g.__next__()) #执行: 王力,李云
从中我们可以看到yield和return的效果是一样的。区别是:yield是分段来执行一个函数,return直接停止执行函数。
# return 直接返回结果. 结束函数的调用;一次性全部拿出,很占内存
# yield 返回结果.可以让函数分段执行;一次就一个,用多少生成多少。生成器是一个一个指向下一个。
3.3 send()方法
def func():
print("大碴粥")
a = yield "11"
print(a)
print("不理")
b = yield "22"
print("大麻花")
c = yield "33"
g = func() # 创建生成器
print(g.__next__())
print(g.send(1))
print(g.__next__())
# 结果:
大碴粥
11
1
狗不理
22
大麻花
33
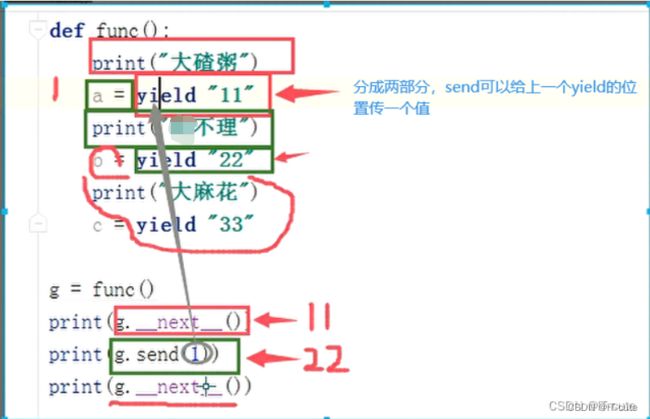
3.3.1 send( )和__ next__区别
send() 和__next__() 都可以让生成器向下执行一次;
send() 可以给上一个yield位置传递值,不能给最后一个yield发送值。 在第一次执行生成器代码的时候不能用send().
3.3.2 把生成器里面的东西转化成列表
def func():
yield 11
yield 22
yield 33
yield 44
g = func()
lst = list(g) # g必须是可迭代对象
print(lst)
# [11, 22, 33, 44]
3.4 生成器表达式(重要)( )
- 生成器表达式和列表推导式的语法基本上是一样的,只是把 [ ] 替换成 ( )
- 生成器表达式可以直接获取生成器对象。
- 生成器对象可以直接进行for循环。
- 生成器具有惰性机制。
# (结果 for 变量 in 可迭代对象 if 条件筛选)
gen = (i for i in range(10))
print(gen)
# 结果:
# at 0x106768f10>
生成器表达式也可以进行筛选 :
# 获取1-100内能被3整除的数
gen = (i for i in range(1, 100) if i % 3 == 0)
for num in gen:
print(num)
# 3 6 9 ...99
3.5 生成器表达式和列表推导式的区别
生成器表达式和列表推导式的区别:
- 1.列表推导式比较耗内存。一次性加载.生成器表达式几乎不占用内存.使用的时候才分配和使用内存
- 2.得到的值不一样.列表推导式得到的是一个列表.生成器表达式获取的是一个生成器.
举个栗子.同样一篮子鸡蛋。
- 列表推导式:直接拿到一篮子鸡蛋.
- 生成器表达式:拿到一个老母鸡,需要鸡蛋就给你下鸡蛋.
生成器的惰性机制:生成器只有在访问的时候才取值。说白了,你找他要他才给你值。不找他要,他是不会执行的。
# 生成器的惰性机制
def func():
print(111)
yield 222
g = func() # 生成器g
g1 = (i for i in g) # 生成器g1,但是g1的数据来源于g
g2 = (i for i in g1) # 生成器g2,来源于g1
print(list(g)) # 获取g中的数据,这时func()才会被执行,打印111获取到222,g完毕
print(list(g1)) # 获取g1中的数据,g1的数据来源是g,但是g已经取完了,g1也就没有数据
print(list(g2)) # 和g1同理
# 111
# [222]
# []
# []
3.6 面试题
def add(a, b):
return a + b
def gen():
for r_i in range(4):
yield r_i # 0,1,2,3
g = gen() # 生成生成器
for n in [2, 10]: # n=2,10 两个值
g = (add(n, i) for i in g)
# n = 2
# g = (add(n, i) for i in gen())
# n =10
# g = (add(n, i) for i in g = (add(10, i) for i in [0,1,2,3]))
print(list(g)) # 这里面所有的n都是10,都是最后一个值
# [20, 21, 22, 23]
四、推导式(没有元组推导式)
4.1 列表推导式 [ ]
# 给出一个列表,通过循环, 里面装1-14的数据
lst = []
for i in range(1,15):
lst.append("python%s" % i)
print(lst)
# ['python1', 'python2', 'python3', 'python4', 'python5', 'python6', 'python7', 'python8', 'python9', 'python10', 'python11', 'python12', 'python13', 'python14']
替换成列表推导式:
# 列表推倒式; 最终给你的是列表
# 语法 [最终结果(变量) for 变量 in 可迭代对象]
lst = [i for i in range(1,15)]
print(lst)
# [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]
找出100以内的偶数:
# [最终结果 for 变量 in 可迭代对象 if 条件]
lst = [i for i in range(1,101) if i%2==0]
print(lst)
4.2 字典推导式{ }
# 把字典中的key和value互换
dic = {'a': 1, 'b': '2'}
new_dic = {dic[key]: key for key in dic}
print(new_dic)
# {1: 'a', '2': 'b'}
# 在以下list中. 从lst1中获取的数据和lst2中相对应的位置的数据组成⼀个新字典
lst1 = ['jay', 'jj', 'sylar']
lst2 = ['周周', '林林俊', '王涛']
dic = {lst1[i]: lst2[i] for i in range(len(lst1))}
print(dic)
# {'jay': '周周', 'jj': '林林俊', 'sylar': '王涛'}
4.3 集合推导式{ }
集合推导式:
- 集合推导式可以帮我们直接生成一个集合。
- 集合的特点:无序,不重复。所以集合推导式自带去重功能。
lst = [1, -1, 8, -8, 12]
# 绝对值去重
s = {abs(i) for i in lst}
print(s)
# {8, 1, 12}
五、装饰器 property
# property 装饰器函数,内置函数,帮助你将类中的方法伪装成属性,特性(特殊的属性)
# 调用方法的时候不需要主动加括号
# 让程序的逻辑性更合理
# @方法名.setter 装饰器,修改被property装饰的属性的时候会调用被这个装饰器装饰的方法,除了self之外还有一个参数,被修改的值
# @方法名.deleter 装饰器,当要删除被property装饰的属性的时候会调用被这个装饰器装饰的方法
class Circle:
def __init__(self, r):
self.r = r
# self.area = 3.14*self.r**2
@property
def area(self): # 这个方法计算结果本身就是一个属性,但是这个属性会随着这个类/对象的一些基础变量的变化而变化
return 3.14 * self.r ** 2
c = Circle(5)
print(c.area) # 78.5
c.r = 10
print(c.area) # 314.0
# 偏其他语言 property+私有的 合用 ,这个时候更多的也会用到setter和deleter
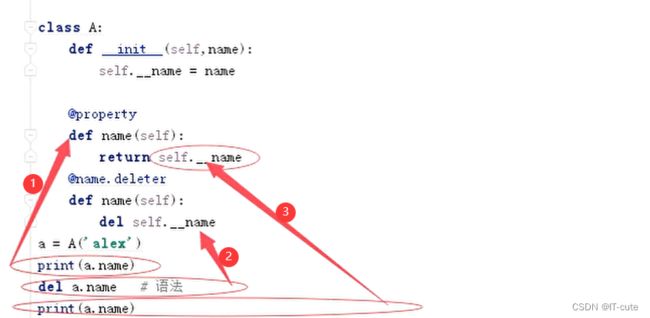
class A:
def __init__(self,name):
self.__name = name
@property
def name(self):
return self.__name
@name.setter
def name(self,new_name):
if type(new_name) is str:
self.__name = new_name
@name.deleter
def name(self):
del self.__name
a = A('alex')
a.name = 123
print(a.name) # alex
# del a.name # 语法
# print(a.name)