riscv简单常用汇编指令xv6
文章目录
- 前言
- entry.S
-
- mret
- asm volatile
-
- read csr
- write csr
- riscv常见csr寄存器
- ecall, 系统调用指令
-
- cpu执行异常处理指令的三种事件
- 异常处理相关寄存器
-
- 用户态trap
-
- sret指令
- 页表切换操作
- 用户态系统调用过程总结
- 内核态trap
- 缺页异常
- 中断与设备驱动
- Locking
- 调度
- 文件系统
- 操作系统拥有的资源
- xv6系统启动过程
-
- 1. 准备C代码执行环境
- 2. 进入main
- char *argv[] = { init, 0 };
- ???
- 其它C语言知识
前言
riscv
在目录下,执行make qemu-gdb ,进程会阻塞.
另开一个终端,在目录下,执行gdb-multiarch kernel/kernel
进入gdb后 b _entry将断点打在最开始处
退出qemu:
first press Ctrl + A (A is just key a, not the alt key),
then release the keys,
afterwards press X.
gdb
GNU gdb (GDB) 7.10.1
Copyright © 2015 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later http://gnu.org/licenses/gpl.html
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type “show copying”
and “show warranty” for details.
This GDB was configured as “x86_64-unknown-linux-gnu”.
Type “show configuration” for configuration details.
For bug reporting instructions, please see:
http://www.gnu.org/software/gdb/bugs/.
Find the GDB manual and other documentation resources online at:
http://www.gnu.org/software/gdb/documentation/.
For help, type “help”.
Type “apropos word” to search for commands related to “word”…
Reading symbols from ./xterm…BFD: BFD (GNU Binutils) 2.25.51 internal error, aborting at elf64-x86-64.c line 5770 in elf_x86_64_get_plt_sym_val
BFD: Please report this bug.
entry.S
.section .text
.section是一条伪指令,用于定义代码的段。该句告诉汇编器将接下来的指令放入.text段(代码段)。
.global _entry
_entry:
.global用于定义全局符号。在汇编中,符号是表示一个地址的标签。
该句表示将 _entry 这个符号标记为全局,这样它可以被其他模块或链接过程引用。通常,程序的入口点会被标记为全局,以确保链接器正确找到程序的起始地址。
la sp, stack0
la是加载地址(Load Address)的缩写,它将stack0的地址加载到栈指针寄存器sp中。
li a0, 1024*4
li是加载立即数(Load Immediate)的缩写,它将1024*4(4KB)加载到寄存器a0中。这个值通常用作栈的大小。
ld sp, 8(a0)
将存储在地址 8 + a0 处的数据加载到栈指针寄存器sp中
csrr a1, mhartid
csrr:这是一个用于读取 CSR(Control and Status Register) 寄存器的指令,其中 “csrr” 是 “CSR Read” 的缩写。
a1:这是目标寄存器,即读取到的 CSR 寄存器的值将被存储在寄存器 a1 中。
mhartid:这是一个 CSR 寄存器的符号名称,表示 Machine Hart ID。Hart 在 RISC-V 中指的是硬件线程,而 mhartid 包含了当前硬件线程的 ID。
这条指令的作用是将当前硬件线程的 ID 读取并存储到寄存器 a1 中。硬件线程 ID 通常用于区分不同的处理器核心或硬件线程,特别是在多核处理器系统中。寄存器 a1 在这里用于保存读取到的硬件线程 ID 的值。
addi a1, a1, 1
addi是加立即数的缩写,这里将a1中的值加1。
mul a0, a0, a1
mul是乘法指令,它将a0和a1的值相乘,结果存储在a0中。这个结果通常用作栈的总大小。
add sp, sp, a0
add是加法指令,它将sp和a0的值相加,结果存储在sp中。这样做是为了调整栈指针,使其指向新的栈顶。
call start
call是一个伪指令,实际上会生成一个jal(Jump and Link)指令,用于调用start函数。
spin:
j spin
这是一个简单的自旋循环,通过无条件跳转指令j使程序在spin标签处不断循环执行。
mret
在RISC-V指令集中,mret是一条特权级别切换指令,用于从机器模式返回到先前的特权级别。这通常用于从机器级别返回到之前的机器模式上下文。
asm volatile("csrw mstatus, %0" : : "r" (x));
asm volatile("csrw mepc, %0" : : "r" (x));
asm volatile("mret"); // mstatus的特权级和mepc寄存器的值生效。及x特权,程序跳转到x处执行
- 将机器级别的程序计数器(PC)设置为机器模式下的值。
- 将机器级别的特权状态切换回到先前的特权级别(通常是用户模式或超级用户模式)。
这样,mret指令使得从高特权级别切换回低特权级别成为可能,比如从内核态返回到用户态。
asm volatile
read csr
asm volatile("csrr %0, mstatus" : "=r" (x) );
c内嵌汇编
asm volatile:这表示内嵌汇编是“volatile”的,这意味着编译器不会对其进行优化,以确保汇编代码的执行顺序不被改变。
“csrr %0, mstatus”:这是实际的汇编指令。csrr 是RISC-V指令集中的一个指令,用于从一个控制寄存器(CSR,Control and Status Register)中读取数据。mstatus 是一个CSR的名称,通常用于保存机器状态信息。
: "=r" (x):这是输出约束(output constraint),指定了汇编代码输出的位置。“=r” 表示将结果放在一个通用寄存器中,而 (x) 则是这个通用寄存器对应的C变量。
mstatus, Machine Status Register是RISC-V架构中的一个控制和状态寄存器(CSR),用于保存和控制机器级别的状态信息。这个寄存器包含了一系列位,每一位都对应着不同的机器状态或控制标志。以下是一些mstatus寄存器中可能包含的一些位的常见含义:
-
MIE(Machine Interrupt Enable):位3是MIE位,用于启用或禁用机器级中断。当MIE被置位时,机器级中断将被启用。
-
MPIE(Machine Previous Interrupt Enable):位7是MPIE位,用于保存中断之前的MIE状态。在中断处理过程中,MPIE会被设置为MIE的值,以便在中断结束后还原中断前的MIE状态。
-
MPP(Machine Previous Privilege):位11和12是MPP位,用于保存中断之前的特权级别。这两位共同表示中断之前的特权级别,可能是用户态(User)、监管态(Supervisor)或机器态(Machine)。
write csr
asm volatile("csrw mstatus, %0" : : "r" (x));
: : "r" (x): 这是内嵌汇编的输入输出约束部分。“r” (x) 表示将变量 x 放到一个通用寄存器中,供汇编代码使用。
#define MSTATUS_MPP_MASK (3L << 11)
#define MSTATUS_MPP_S (1L << 11)
mstatus_val &= ~MSTATUS_MPP_MASK;
mstatus_val |= MSTATUS_MPP_S;
riscv常见csr寄存器
RISC-V指令集中的CSR(Control and Status Register)寄存器用于控制和监视处理器的状态。以下是一些常见的CSR寄存器及其作用:
-
mvendorid(Machine Vendor ID):用于标识实现RISC-V架构的硬件供应商。
-
marchid(Machine Architecture ID):指定RISC-V的体系结构版本。
-
mimpid(Machine Implementation ID):表示具体的硬件实现。
-
mhartid(Machine Hart ID):用于标识处理器的硬件线程。
-
mstatus(Machine Status):包含有关处理器当前状态的信息,例如中断使能和处理器模式。
-
mie(Machine Interrupt Enable):用于启用或禁用中断。
-
mcause(Machine Cause):标识最后一次异常或中断的原因。
-
mtvec(Machine Trap Vector):包含异常处理程序的基址,用于处理中断和异常。
-
mscratch:用于存储临时数据,例如异常处理时保存的寄存器值。
-
mepc(Machine Exception Program Counter):保存导致异常的指令地址。
-
mcounteren:用于控制计数器(cycle、time等)是否可由用户模式访问。
-
mip(Machine Interrupt Pending):指示哪些中断是激活的。
-
stap:配置和管理地址翻译和保护机制。具体来说,satp寄存器主要用于设置页表的基址以及选择页表的模式,从而启用虚拟地址到物理地址的转换。
asm volatile("csrw mepc %0"::"r"( (uint64)main ));
将main的地址写入mepc,当调用mret是以便程序“继续”从main执行
ecall, 系统调用指令
# RISC-V Assembly code example with ecall
.section .text
.globl _start
_start:
# Your assembly code here
# Make a system call
li a7, 10 # 系统调用号存储在a7寄存器 scause寄存器存储事件号
ecall
# End of program
j _start
ecall是一个用于发起系统调用(system call)的指令。系统调用是用户程序与操作系统进行交互的一种方式,允许用户程序请求操作系统提供的服务,如文件操作、进程管理等。
cpu执行异常处理指令的三种事件
- 系统调用,即,当用户程序执行ecall指令时。
- 非法指令,如除以0、无效的虚拟地址
- 设备中断,当设备信号需要被处理时,如硬件完成读写
异常处理相关寄存器
- stvec: 内核将事件处理程序地址写到该寄存器,RISC-V跳转到stvec的地址处理事件
- sepc: 当事件发生时,cpu保存pc指针(因为后面stvec的值会覆盖它)。sret(异常处理结束的返回指令)指令copy sepc到pc。内核能够写入sepc来控制sret的去向
- scause: RISC-V将事件号写入这里
- sscratch: 内核在这里放置一个值,该值在trap处理程序一开始就很有用
- sstatus: SIE位控制设备中断开关,SPP位指示事件是来自用户模式还是管理员模式,并且控制sret的返回
以上寄存器在用户模式是不可读写的。
在机器模式下也有一组相似的控制寄存器来处理异常;
多核芯片的每个cpu都有它自己的一组寄存器,任意时刻都有可能有任意个cpu处理trap。
- 如果trap是设备中断,且sstatus SIE位被清零,以下几条都不做
- 通过清除sstatus SIE位关闭中断
- 复制pc到sepc
- 保存当前运行模式(用户模式或超级用户模式)到sstatus的SPP位
- 设置scause为trap原因
- 设为超级用户模式
- 复制stvec到pc
- 从新的pc处开始执行
注意到,cpu不会切换到内核页表,也不会切换到内核栈,也不会保存除了pc寄存器外的其他寄存器。内核软件必须完成这些工作。cpu最小化工作是为了为软件提供最大的灵活性,如某些系统为了性能可能不会进行页表切换。
用户态trap
.align 4确保接下来的指令或数据将被放置在4字节的边界上。其中.align为伪指令
csrw sscratch, a0 这条指令的作用是将 a0 寄存器的值写入到 sscratch CSR 中。这可以用于保存当前软件线程的一些临时状态,以备将来的恢复。在上下文切换时,操作系统可能会使用 sscratch 来保存当前线程的一些上下文信息。
sd ra, 40(a0) 的含义是将通用寄存器 ra 中的值存储到内存中,存储的目标地址是 a0 寄存器中的值加上 40。sd 指令: sd 是 “Store Doubleword” 的缩写,用于将一个双字(64位)的数据存储到内存中。40(a0): 这表示存储目标的内存地址。具体地,它是 a0 寄存器中的值加上 40。这是一种相对地址寻址方式,表示存储目标的地址是 a0 中的值加上 40。
在 RISC-V 架构中,这些寄存器具有以下作用:
-
ra- Return Address: 这是返回地址寄存器,用于保存函数调用的返回地址。 -
sp- Stack Pointer: 栈指针寄存器,指向当前函数的栈顶。 -
gp- Global Pointer: 全局指针寄存器,通常用于访问全局数据区。 -
tp- Thread Pointer: 线程(核id)指针寄存器,用于线程相关的指针。 -
t0,t1,t2- Temporary Registers: 临时寄存器,可以用于存储临时数据。 -
s0,s1, …,s11- Saved Registers: 保存寄存器,用于保存在函数调用中需要保留的寄存器值。 -
a0,a1, …,a7- Argument Registers: 参数寄存器,用于传递函数参数。 -
t3,t4,t5,t6- Temporary Registers: 更多的临时寄存器。
每个寄存器都有其特定的用途,例如用于保存返回地址、参数传递、临时存储等。在函数调用时,一些寄存器的值可能会被保存和恢复,以确保程序的正确执行。这些寄存器的具体用途也可能取决于特定的编程约定和编译器。
sfence.vma zero, zero 是 RISC-V 汇编中的一条指令,用于执行虚拟地址到物理地址的刷新操作。
-
sfence.vma指令:sfence.vma是 “Store Fence Virtual Memory to Physical Memory” 的缩写。这是一种内存屏障指令,它确保在它之前的所有内存操作都完成,然后刷新(同步)虚拟地址到物理地址的映射。 -
zero寄存器: 在 RISC-V 中,zero寄存器始终包含常量值零。在这里,两个zero寄存器作为参数,表示没有特定的虚拟地址范围需要刷新。 -
虚拟地址到物理地址的刷新: 在操作系统和硬件的交互中,虚拟地址和物理地址之间存在映射关系。这种刷新操作确保最新的虚拟地址到物理地址的映射关系被刷新,以反映最新的变化。这在多核系统中的共享内存环境中特别重要,以确保不同核之间的一致性。
总的来说,sfence.vma zero, zero 指令用于确保之前的内存操作已经完成,并刷新虚拟地址到物理地址的映射,以保持内存一致性。
sret指令
用于从中断或异常处理程序中返回到调用者
在执行该指令之前:
- 设置status寄存寄存器的 cpu运行模式,终端开关等
- 设置sepc寄存器
- 设置satp页表寄存器
- 切换页表
- 将a0寄存器设置为TRAPFRAME
- 恢复所有寄存器
- 调用sret (将spec寄存器的值写入pc寄存器等…程序从pc处开始执行) 返回用户模式
下面的c代码与对应的汇编
unsigned long int satp = 456;
((void (*)(unsigned long int))trampoline_userret)(satp);
// asm
li a5,456 # 将立即数456写到寄存器a5
sd a5,-24(s0) # 将a5的值写入地址s0-24(改地址在栈上)
lui a5,%hi(trampoline_userret)
addi a5,a5,%lo(trampoline_userret)
ld a0,-24(s0) # 将之间保存的456加载到寄存器a0上
jalr a5 # 跳转到a5(即,跳转到trampoline_userret)
//
页表切换操作
sfence.vma zero, zero
csrw satp, TLB
sfence.vma zero, zero
用户态系统调用过程总结
- 用户态执行
将init地址放入a0,argv放入a1,将调用号放入a7#include "syscall.h" # exec(init, argv) .globl start start: la a0, init la a1, argv li a7, SYS_exec ecall # char init[] = "/init\0"; init: .string "/init\0" # char *argv[] = { init, 0 }; .p2align 2 argv: .long init .long 0 - 执行ecall,即,程序从uservec处开始执行
- 程序执行到uint64 sys_exec(void);
sys_exec会调用copyinstr,该函数会在内核页表下正确拷贝用户页表的参数 - 将调用结果放入a0
- 最后调用sret返回用户态
内核态trap
当在内核态发生trap时,
-
执行一些动作。由于stvec存的是kernelvec,所以pc指向kernelvec,即代码从该处执行
-
保存内核态寄存器到内核栈上
-
读取sepc(中断前执行的指令),sstatus获取与硬件相关的状态,scause获取trap原因
-
判断trap类型:a supervisor external interrupt, via PLIC;software interrupt from a machine-mode timer interrupt, forwarded by timervec in kernelvec.S.
// returns 2 if timer interrupt,
// 1 if other device,
// 0 if not recognized.// 处理设备中断
// give up the CPU if this is a timer interrupt. -
设置sepc和sstatus寄存器为 3. 的值,即恢复之前的状态
-
函数执行完}后,继续从函数调用(call)后面的指令执行
-
恢复寄存器状态
-
调用sret,结束trap
在用户态时stvec = usertrap,当从用户态进入内核态时,stvec被设置为kernelvec。当setvec的usertrap执行时,中断自动关闭,直到启用。
缺页异常
scause寄存器知识缺页类型,stval寄存器包含未能被映射的地址
中断与设备驱动
设备驱动的执行分为两个部分:1.通过系统调用,内核线程的顶层操作,如read,write执行IO。此时代码请求硬件开始操作并等待其完成 2.设备完成操作并产生一个中断,此时驱动中断处理程序作为底层操作唤醒进程并执行后续操作
UART硬件在软件中显示为一组内存映射的控制寄存器。硬件设备映射到特定的物理地址上。操纵物理地址并非是与内存交互而是和设备。有几组UART控制寄存器,每个1字节。偏移量从#define UART0 0x10001000开始。
如何初始化UART控制台?
反应在软件上就是对相关寄存器(地址)进行读写控制即可
读取过程:
如LSR寄存器包含判断输入字符是否准备读取的位,如果字符可从RHR寄存器读取,每当从该寄存器读取一个字符时,UART硬件从内部FIFO中删除等待字符,并清除LSR中的“ready”位(当FIFO为空时)。UART的发送硬件和接收硬件是不相依赖的,如果软件向THR写入一个字节,UART就发送该字节。
// map major device number to device functions.
struct devsw {
int (*read)(int, uint64, int);
int (*write)(int, uint64, int);
#define NDEV 10
} devsw[NDEV];
#define CONSOLE 1
devsw[CONSOLE].read = consoleread;
devsw[CONSOLE].write = consolewrite;
consoleread等待从内核缓冲区cons.buf中读取数据
当用户输入字符时,UART硬件向RISC-V请求中断,然后系统进入trap处理代码,改代码经过检查scause中断原因最终调用devintr->uartintr,最终通过读取RHR获取字符。consoleintr(控制台中断处理函数)负责将读的字符存入cons.buf,在满足条件时,consoleintr唤醒consoleread(如果有的话),uartintr结束即异常处理结束,consoleread负责将内核缓冲区数据拷贝到用户缓冲区,然后返回用户空间。
每当UART发送完一个字节,他会产生一个中断,uartintr调用uartstart检查设备是否完成发送,并处理设备下一个输出字符。因此,如果一个程序向控制台输出多个字节,一般第一个字节由uartputc调用uartstart完成,缓冲区剩余的字节以中断的方式由uartintr调用uartstart完成发送。
通常设备活动与程序活动通过buffer和中断实现结构。控制台驱动可以处理输入,即便没有进程在等待读取;随后的读取将会看到输入的数据。同样的,程序无需等待设备而输出数据。这种解耦允许进程并发的执行IO,进而提高性能,当设备十分慢时尤为重要。这种思想有时被称为IO并发。
驱动中的并发中断处理程序运行时再产生中断是不好的行为,中断处理程序应当做较少的工作,如仅将数据拷贝到缓冲区然后唤醒其他代码
计时器中断系统编程时钟硬件周期性的中断每个CPU
RISC-V要求定时器中断在机器模式下进行,而不是在监控模式下进行。RISCV机器模式在没有分页的情况下执行,并且有一组单独的控制寄存器,所以它不是在机器模式下运行普通xv6内核代码而实现的。因此,xv6处理定时器中断与上述trap机制完全分开。
计时器中断可以发生在任意时刻;在临界操作时内核无法关闭计时器中断。因此计时器中断处理程序需要接收这项工作,并且保证以一种不会被中断的内核代码的方式。实现计时器中断处理程序的基础方式时请求RISC-V引发一个“软中断”并立即返回。RISC-V以普通trap机制向内核发送软中断并允许内核关闭该中断。由计时器中断产生的软中断的异常处理程序在devintr中。
机器模式下的计时器中断处理代码为timervec。它仅仅保存了少部分的寄存器,通知CLINT(Core Local Interrupt)何时产生下一个计时器中断,请求RISC-V产生一个软中断,恢复寄存器然后返回。
- sip:与软中断相关的寄存器
Locking
锁保证同一时间内只有一个CPU拥有锁,即同一时间只有一个核执行临界代码。
分两种情况考虑:
- 单核CPU,多线程
只需保证在执行临界代码时不进行线程切换即可,但可以切换到不同进程的线程 - 多核CPU,多线程
在1的基础上再加上,多个核心不能同时执行临界代码
系统中的锁
| name | description |
|---|---|
| bcache.lock | Protects allocation of block buffer cache entries |
| cons.lock | Serializes access to console hardware, avoids intermixed output |
| ftable.lock | Serializes allocation of a struct file in file table |
| itable.lock | Protects allocation of in-memory inode entries |
| vdisk_lock | Serializes access to disk hardware and queue of DMA descriptors |
| kmem.lock | Serializes allocation of memory |
| log.lock | Serializes operations on the transaction log |
| pipe’s pi->lock | Serializes operations on each pipe |
| pid_lock | Serializes increments of next_pid |
| proc’s p->lock | Serializes changes to process’s state |
| wait_lock | Helps wait avoid lost wakeups |
| tickslock | Serializes operations on the ticks counter |
| inode’s ip->lock | Serializes operations on each inode and its content |
| buf’s b->lock | Serializes operations on each block buffer |
指令与内存序
为了提高性能,编译器可能不会按照代码书写的顺序编译成指令,CPU可能也不会按照指令顺序去执行。
__sync_synchronize()是内存屏障:告诉编译器和CPU禁止跨越屏障作指令重排序。
当acquire spinlock时不允许中断与yield
sleeplock, yield CPU和释放spinlock是原子操作???sleeplock允许中断,因此不能用在中断处理程序中,也不能用在spinlock的临界代码段
Pthreads(POSIX threads) has support for user-level locks, barriers, etc. Pthread also allows a programmer to optionally specify that a lock should be reentrant.
调度
多路复用的两种方式:1. sleep, wakeup机制,如等待设备或IO完成,等待子进程结束或sleep调用。2. 周期性的强迫进程发生切换。
每个核心都有自己一组寄存器,该组寄存器(struct context)被称为上下文。
当在swtch函数调用结束并非返回到sched函数而是scheduler函数。
每个物理核都有一个对应的全局变量struct cpu。
睡眠与唤醒机制
生产者与消费者模型机制
void V(struct semaphore *s)
{
acquire(&s->lock);
s->count += 1;
wakeup(s);
release(&s->lock);
}
void P(struct semaphore *s)
{
acquire(&s->lock);
while(s->count == 0)
sleep(s, &s->lock); # 标记为SLEEPING态并放弃CPU
s->count -= 1;
release(&s->lock);
}
文件系统
设计文件系统面对的挑战
- 文件系统需要磁盘上的数据结构来表示命名目录和文件的树,记录保存每个文件内容的块的标识,以及记录磁盘的哪些区域是空闲的
- 文件系统需要支持crash recovery
- 不同的进程可能会同时访问文件系统的文件,所以文件系统代码必须协调以维护不变量
- 文件系统需要对高频访问数据进行内存缓存
a simple filesystem layer:
±----------------±----------------+
| layer name | description |
±----------------±----------------+
| file descriptor |
| path name |
| directory | inode with special contents
| inode | inode allocator, reading writing, metadata
| logging | crash recovery
| buffer cache | raw data
| disk |
±----------------±----------------+
磁盘以sector为单位(一般为512Byte), block大小为sector的整数倍,sector有号码,block也有号码,根据sector号从硬盘中读写数据。
struct buf {
int valid; // 从硬盘中读完数据后赋为1
// 读写数据前设为1,当硬盘完成操作后中断处理程序将其设为0
int disk; // does disk "own" buf?
uint dev; // 设备号
uint blockno; // block 号码
struct sleeplock lock;
uint refcnt;
struct buf *prev; // LRU cache list
struct buf *next;
uchar data[BSIZE]; // 从硬盘读写的数据,此为一个block
};
定义struct buf[NBUF]; 通过bread(dev, blockno)获取到一个buf指针,并带有读取的硬盘数据。
bp = bread(dev, 1);其中bp->data的部分数据即为superblock的内容
iNode层:
// On-disk inode structure
struct dinode {
short type; // File type
short major; // Major device number (T_DEVICE only)
short minor; // Minor device number (T_DEVICE only)
short nlink; // Number of links to inode in file system
uint size; // Size of file (bytes)
uint addrs[NDIRECT+1]; // Data block addresses
};
// 内存中的iNode在itable中
// in-memory copy of an inode
struct inode {
uint dev; // Device number
uint inum; // Inode number
int ref; // Reference count, if ref == 0 release this
struct sleeplock lock; // protects everything below here
int valid; // inode has been read from disk?
short type; // copy of disk inode
short major;
short minor;
short nlink;
uint size;
uint addrs[NDIRECT+1];
};
Path:
内存文件系统的iNode=1
root目录的iNode=2
mount -t tmpfs -o size=32M tmpfs /mnt/tmpfs/
ls -id /mnt/tmpfs/
ls -id /
File Descriptor:
struct file结构体可表示一个文件、管道、设备等系统资源,某个系统资源的struct file结构体可同时出现在不同进程的文件表中,一个进程的文件表可出现多次,在全局文件表ftable中也可出现多次。
filealloc将文件的ref+1, fileclose将文件的ref-1,当ref==0时释放该结构体对应的系统资源,filestate获取inode信息,fileread、filewrite根据struct file的类型调用对应的函数读写数据
操作系统拥有的资源
- 各种类型的锁
- 调度器
- 进程表
- 文件表
- 运行时创建的系统资源,比如管道等
xv6系统启动过程
调试所需gdb命令:
| b [file:]line/symbol info b d num |
打断点 显示所有断点 删除某个断点 |
| info registers | 显示所有寄存器的值 |
| display $sp undisplay sp |
显示sp寄存器的值 不再显示 |
| p var | 打印某个变量… |
| si | 下一条汇编执行令 |
| n | 下一行c代码 |
| s | 下一行c代码,进入函数体 |
| finish | 结束函数 |
1. 准备C代码执行环境
qemu -kernal将内核装载到0x80000000处,然后让每个hart(cpu核)跳转到这里执行
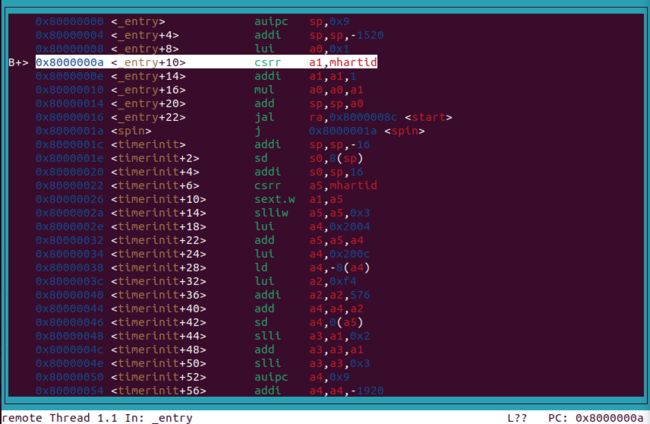
将stack0放在16的整数倍地址上
__attribute__ ((aligned (16))) char stack0[4096 * NCPU];
栈大小为4096
sp = 0x80008a10, stack0 = 0x80008a10
为何stack0的地址为0x80008a10,是有谁设置的?由编译器按顺序排列得到的吗?如何保证_entry在内核的首条代码处?
cpu1:sp(now) -> 0x8000aa10
stacksize = 4k
cpu0:sp(now) -> 0x80009a10
stacksize = 4k
all core of cpu: sp(before) -> 0x80008a10
对每个CPU核心的栈初始化之后跳转到C函数void start();处执行
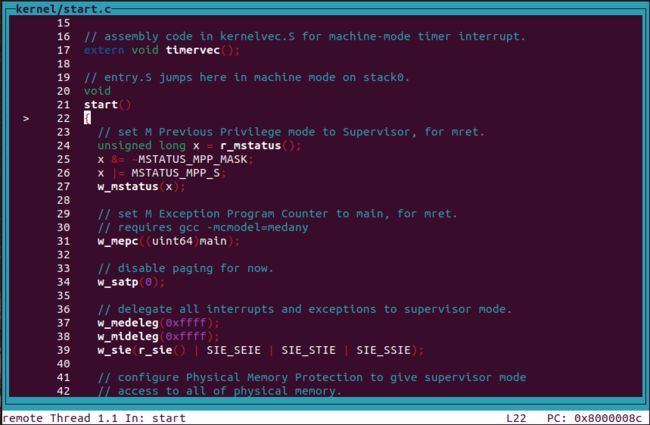
mepc = 0x80000E72 (main)
start函数对寄存器等硬件资源进行设置后跳转至void main()处执行
2. 进入main
tips: 似乎不能通过si的方式直接进入main需要打断点
cpuid为0的核执行内核代码,其它核进入while(started == 0); ,当cpu0执行完内核代码后将started设为1,所有核心进入scheduler()死循环中。
- 控制台初始化
devsw[CONSOLE].read = consoleread;
devsw[CONSOLE].write = consolewrite; - printfinit
初始化printf函数的锁,当调用printf时都会获取锁保证字符串线程安全的输出至终端,只有在panic时无锁输出 - kinit(); // physical page allocator
分配物理页表,将每个页的每个字节都写入垃圾直1 - kvminit(); // create kernel page table
创建内核页表。
从之前分配好的物理内存页中获取一个4k大小的块(一页)
第二个参数指向一个从第三个参数为起始的物理地址,从第二个参数开始为虚拟地址创建PTEs
最后为每个程序都分配好内核栈(vx6预先设定好最多只能有64个进程) - kvminithart(); // turn on paging
开启虚拟内存功能 - procinit(); // process table
初始化进程表 - trapinit(); // trap vectors
- trapinithart(); // install kernel trap vector
初始化内核态异常处理代码w_stvec((uint64)kernelvec); - plicinit(); // set up interrupt controller
设置中断控制器
(uint32)(PLIC + UART0_IRQ4) = 1;
(uint32)(PLIC + VIRTIO0_IRQ4) = 1; - plicinithart(); // ask PLIC for device interrupts
- binit(); // buffer cache
- 文件系统相关
iinit(); // inode table
fileinit(); // file table
virtio_disk_init(); // emulated hard disk - 启动第一个用户进程:
从而进程表中有了一个有效的进程
#exec(init, argv)
.globl start
start:
la a0, init
la a1, argv
li a7, SYS_exec
ecall
#for( ; ; ) exit();
exit:
li a7, SYS_exit
ecall
jal exit
init:
.string “/init\0” - 进入调度器
调度器的swtch(&c->context, &p->context);函数不会直接返回到下一句,而是…
char *argv[] = { init, 0 };
.p2align 2
argv:
.long init
.long 0
???
riscv xv6系统中,trampoline和trapframe的虚拟地址在用户页表和内核页表中是相同的吗
trampoline是内核页表和用户页表相同的地址
trapframe不同???但地址固定
当产生计时器中断时会执行timervec:代码执行完后会去哪执行?
其它C语言知识
// 存放系统调用的指针
static uint64 (*syscalls[])(void) = {
[SYS_fork] sys_fork,
[SYS_exit] sys_exit,
[SYS_wait] sys_wait,
[SYS_pipe] sys_pipe,
[SYS_read] sys_read,
[SYS_kill] sys_kill,
[SYS_exec] sys_exec,
[SYS_fstat] sys_fstat,
[SYS_chdir] sys_chdir,
[SYS_dup] sys_dup,
[SYS_getpid] sys_getpid,
[SYS_sbrk] sys_sbrk,
[SYS_sleep] sys_sleep,
[SYS_uptime] sys_uptime,
[SYS_open] sys_open,
[SYS_write] sys_write,
[SYS_mknod] sys_mknod,
[SYS_unlink] sys_unlink,
[SYS_link] sys_link,
[SYS_mkdir] sys_mkdir,
[SYS_close] sys_close,
};
// 或者
int arr[] = {
[1] = sys_fork,
[2] = sys_exit,
};