特征匹配python-opencv代码
目录
特征匹配算法介绍:
Brute-Force蛮力匹配
1对1的匹配
k对最佳匹配
特征匹配理论介绍:
特征匹配python程序:
特征点提取介绍:
harris特征:
#### cv2.cornerHarris()
- img: 数据类型为 float32 的入图像
- blockSize: 角点检测中指定区域的大小
- ksize: Sobel求导中使用的窗口大小
- k: 取值参数为 [0,04,0.06]
import cv2
import numpy as np
img = cv2.imread('test_1.jpg')
print ('img.shape:',img.shape)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# gray = np.float32(gray)
dst = cv2.cornerHarris(gray, 2, 3, 0.04)
print ('dst.shape:',dst.shape)
sift特征:
import cv2
import numpy as np
img = cv2.imread('test_1.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
sift = cv2.xfeatures2d.SIFT_create()
kp = sift.detect(gray, None)
img = cv2.drawKeypoints(gray, kp, img)
cv2.imshow('drawKeypoints', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
kp, des = sift.compute(gray, kp)
特征匹配算法介绍:
Brute-Force蛮力匹配
crossCheck表示两个特征点要互相匹,例如A中的第i个特征点与B中的第j个特征点最近的,并且B中的第j个特征点到A中的第i个特征点也是
#NORM_L2: 归一化数组的(欧几里德距离),如果其他特征计算方法需要考虑不同的匹配计算方式
bf = cv2.BFMatcher(crossCheck=True)
1对1的匹配
bf.match(des1, des2)
k对最佳匹配
bf = cv2.BFMatcher()
matches = bf.knnMatch(des1, des2, k=2)
如果需要更快速完成操作,可以尝试使用cv2.FlannBasedMatcher
特征匹配理论介绍:
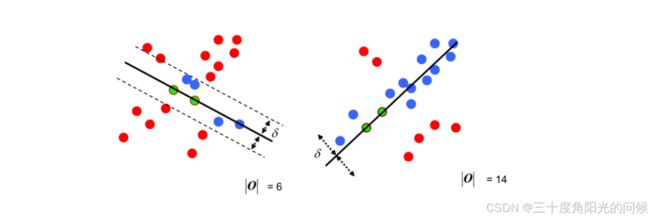
随机抽样一致算法(Random sample consensus,RANSAC)
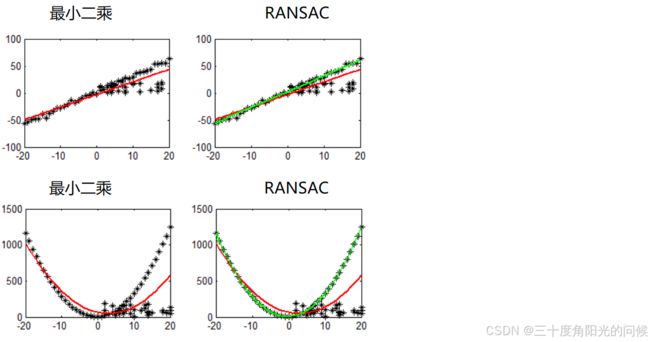
选择初始样本点进行拟合,给定一个容忍范围,不断进行迭代
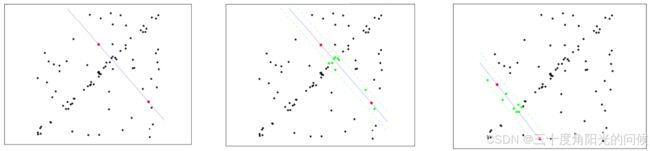
每一次拟合后,容差范围内都有对应的数据点数,找出数据点个数最多的情况,就是最终的拟合结果
单应性矩阵
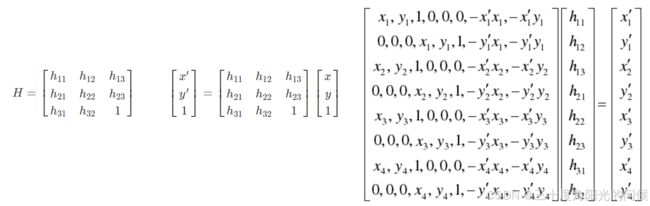
特征匹配python程序:
### 特征匹配
#### Brute-Force蛮力匹配
import cv2
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
img1 = cv2.imread('box.png', 0)
img2 = cv2.imread('box_in_scene.png', 0)
def cv_show(name,img):
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
cv_show('img1',img1)
cv_show('img2',img2)
sift = cv2.xfeatures2d.SIFT_create()
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
# crossCheck表示两个特征点要互相匹,例如A中的第i个特征点与B中的第j个特征点最近的,并且B中的第j个特征点到A中的第i个特征点也是
#NORM_L2: 归一化数组的(欧几里德距离),如果其他特征计算方法需要考虑不同的匹配计算方式
bf = cv2.BFMatcher(crossCheck=True)
#### 1对1的匹配
matches = bf.match(des1, des2)
matches = sorted(matches, key=lambda x: x.distance)
img3 = cv2.drawMatches(img1, kp1, img2, kp2, matches[:10], None,flags=2)
cv_show('img3',img3)
#### k对最佳匹配
bf = cv2.BFMatcher()
matches = bf.knnMatch(des1, des2, k=2)
good = []
for m, n in matches:
if m.distance < 0.75 * n.distance:
good.append([m])
img3 = cv2.drawMatchesKnn(img1,kp1,img2,kp2,good,None,flags=2)
cv_show('img3',img3)
如果需要更快速完成操作,可以尝试使用cv2.FlannBasedMatcher
### 随机抽样一致算法(Random sample consensus,RANSAC)

选择初始样本点进行拟合,给定一个容忍范围,不断进行迭代

每一次拟合后,容差范围内都有对应的数据点数,找出数据点个数最多的情况,就是最终的拟合结果

#### 单应性矩阵
