C++编程-数据排序2
目录
关于以后的更新
回顾数据排序1
一:冒泡排序
二:选择排序
今日讲解
例题六:归并排序
算法简介
题目描述
标准程序
标程分析
例题七:逆序对
算法简介
题目描述
标准程序
标程分析
本期重点:各种排序算法的比较
先言!!!
1.稳定性比较
2.时间复杂度比较
3.辅助空间的比较
4.其他
小练习
题目描述
题目描述
输入
输出
样例输入 复制
样例输出 复制
关于以后的更新
已经8月25号了,即将接近CSP-J/S,因此,在数据排序算法更新完后,我们会重点更新CSP的试卷以及知识点,希望大家在考试中旗开得胜!
回顾数据排序1
在数据排序1中,我们讲解了选择、冒泡、插入、桶、快速排序,并留下了2道题目,今天就来解答这两道题目
一:冒泡排序
#include
int main() {
int n, i, j, temp;
int a[200];
scanf("%d", &n);
for (i = 0;i < n;i++)
scanf("%d", &a[i]);
for (i = 0;i < n;i++) {
for (j = 0;j + i + 1 < n;j++) {
if (a[j] > a[j + 1]) {
temp = a[j];
a[j] = a[j + 1];
a[j + 1] = temp;
}
}
}
for (i = 0;i < n;i++) {
printf("%d ", a[i]);
}
puts("");
return 0;
}
二:选择排序
#include
#include
using namespace std;
int a[15];
int main()
{
for (int i=0;i<10;i++)
cin>>a[i];
sort(a+0,a+10);
for (int i=0;i<10;i++)
cout < 今日讲解
在本期中,我们需要讲解归并、逆序对排序的方法,还要学习各种排序算法之间的比较,那么开始吧!
例题六:归并排序
算法简介
归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
例如有8个数据需要排序:10 4 6 3 8 2 5 7
归并排序主要分两大步:分解、合并。
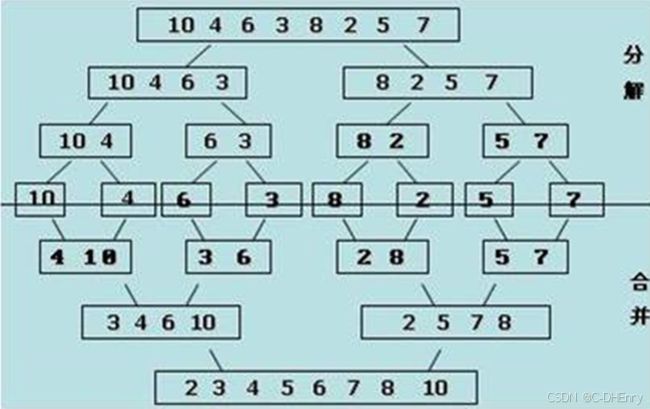
合并过程为:比较a[i]和a[j]的大小,若a[i]≤a[j],则将第一个有序表中的元素a[i]复制到r[k]中,并令i和k分别加上1;否则将第二个有序表中的元素a[j]复制到r[k]中,并令j和k分别加上1,如此循环下去,直到其中一个有序表取完,然后再将另一个有序表中剩余的元素复制到r中从下标k到下标t的单元。归并排序的算法我们通常用递归实现,先把待排序区间[s,t]以中点二分,接着把左边子区间排序,再把右边子区间排序,最后把左区间和右区间用一次归并操作合并成有序的区间[s,t]。
题目描述
用归并排序,完成归并排序的子函数
标准程序
void msort(int s,int t)
{
if(s==t) return; //如果只有一个数字则返回,无须排序
int mid=(s+t)/2;
msort(s,mid); //分解左序列
msort(mid+1,t); //分解右序列
int i=s, j=mid+1, k=s; //接下来合并
while(i<=mid && j<=t)
{
if(a[i]<=a[j])
{
r[k]=a[i]; k++; i++;
}else{
r[k]=a[j]; k++; j++;
}
}
while(i<=mid) //复制左边子序列剩余
{
r[k]=a[i]; k++; i++;
}
while(j<=t) //复制右边子序列剩余
{
r[k]=a[j]; k++; j++;
}
for(int i=s; i<=t; i++) a[i]=r[i];
return 0;
}
标程分析
归并排序的时间复杂度是O(nlogn),速度快。同时,归并排序是稳定的排序。即相等的元素的顺序不会改变。如输入记录 1(1) 3(2) 2(3) 2(4) 5(5) (括号中是记录的关键字)时输出的 1(1) 2(3) 2(4) 3(2) 5(5) 中的2 和 2 是按输入的顺序。这对要排序数据包含多个信息而要按其中的某一个信息排序,要求其它信息尽量按输入的顺序排列时很重要,这也是它比快速排序优势的地方。
例题七:逆序对
算法简介
上述提到归并排序是稳定的排序,相等的元素的顺序不会改变,进而用其可以解决逆序对的问题。首先我们了解一下什么是逆序对。
逆序对:设 A 为一个有 n 个数字的有序集 (n>1),其中所有数字各不相同。如果存在正整数 i, j 使得 1 ≤ i < j ≤ n 而且 A[i] > A[j],则
例如,数组(3,1,4,5,2)的逆序对有(3,1),(3,2),(4,2),(5,2),共4个。
所谓逆序对的问题,即对给定的数组序列,求其逆序对的数量。
从逆序对定义上分析,逆序对就是数列中任意两个数满足大的在前,小的在后的组合。如果将这些逆序对都调整成顺序(小的在前,大的在后),那么整个数列就变的有序,即排序。因而,容易想到冒泡排序的机制正好是利用消除逆序来实现排序的,也就是说,交换相邻两个逆序数,最终实现整个序列有序,那么交换的次数即为逆序对的数量。
冒泡排序可以解决逆序对问题,但是由于冒泡排序本身效率不高,时间复杂度为O(n2),对于n比较大的情况就没用武之地了。我们可以这样认为,冒泡排序求逆序对效率之所以低,是因为其在统计逆序对数量的时候是一对一对统计的,而对于范围为n的序列,逆序对数量最大可以是(n+1)*n/2,因此其效率太低。那怎样可以一下子统计多个,而不是一个一个累加呢?这个时候,归并排序就可以帮我们来解决这个问题。
在合并操作中,我们假设左右两个区间元素为:
左边:{3 4 7 9} 右边:{1 5 8 10}
那么合并操作的第一步就是比较3和1,然后将1取出来,放到辅助数组中,这个时候我们发现,右边的区间如果是当前比较的较小值,那么其会与左边剩余的数字产生逆序关系,也就是说1和3、4、7、9都产生了逆序关系,我们可以一下子统计出有4对逆序对。接下来3,4取下来放到辅助数组后,5与左边剩下的7、9产生了逆序关系,我们可以统计出2对。依此类推,8与9产生1对,那么总共有4+2+1对。这样统计的效率就会大大提高,便可较好的解决逆序对问题。
而在算法的实现中,我们只需略微修改原有归并排序,当右边序列的元素为较小值时,就统计其产生的逆序对数量,即可完成逆序对的统计。
题目描述
利用逆序对算法,完成子函数
标准程序
void msort(int s,int t)
{
if(s==t) return; //如果只有一个数字则返回,无须排序
int mid=(s+t)/2;
msort(s,mid); //分解左序列
msort(mid+1,t); //分解右序列
int i=s, j=mid+1, k=s; //接下来合并
while(i<=mid && j<=t)
{
if(a[i]<=a[j])
{ r[k]=a[i]; k++; i++;
}else{
r[k]=a[j]; k++; j++;
ans+=mid-i+1; //统计产生逆序对的数量
}
}
while(i<=mid) //复制左边子序列剩余
{
r[k]=a[i]; k++; i++;
}
while(j<=t) //复制右边子序列剩余
{
r[k]=a[j]; k++; j++;
}
for(int i=s; i<=t; i++) a[i]=r[i];
return 0;
}
标程分析
其中ans+=mid-i+1这句代码统计新增逆序对的数量,ans作为全局变量,用于统计逆序对的数量,此时ans要增加左边区间剩余元素的个数。当归并排序结束后,逆序对问题也得到解决,ans即为逆序对的数量。
本期重点:各种排序算法的比较
先言!!!
建议拿好笔记本,记好关键字。
1.稳定性比较
插入排序、冒泡排序、二叉树排序、二路归并排序及其他线形排序是稳定的。
选择排序、希尔排序、快速排序、堆排序是不稳定的。
2.时间复杂度比较
插入排序、冒泡排序、选择排序的时间复杂性为O(n2);快速排序、堆排序、归并排序的时间复杂性为O(nlog2n);桶排序的时间复杂性为O(n);
若从最好情况考虑,则直接插入排序和冒泡排序的时间复杂度最好,为O(n),其它算法的最好情况同平均情况相同;若从最坏情况考虑,则快速排序的时间复杂度为O(n2),直接插入排序和冒泡排序虽然平均情况相同,但系数大约增加一倍,所以运行速度将降低一半,最坏情况对直接选择排序、堆排序和归并排序影响不大。
由此可知,在最好情况下,直接插入排序和冒泡排序最快;在平均情况下,快速排序最快;在最坏情况下,堆排序和归并排序最快。
3.辅助空间的比较
桶排序、二路归并排序的辅助空间为O(n),快速排序的辅助空间为O(log2n),最坏情况为O(n),其它排序的辅助空间为O(1);
4.其他
插入、冒泡排序的速度较慢,但参加排序的序列局部或整体有序时,这种排序能达到较快的速度。反而在这种情况下,快速排序反而慢了。
当n较小时,对稳定性不作要求时宜用选择排序,对稳定性有要求时宜用插入或冒泡排序。
若待排序的记录的关键字在一个明显有限范围内时,且空间允许是用桶排序。
当n较大时,关键字元素比较随机,对稳定性没要求宜用快速排序。
当n较大时,关键字元素可能出现本身是有序的,对稳定性没有要求时宜用堆排序
快速排序是目前基于比较的内部排序中被认为是最好的方法,当待排序的关键字是随机分布时,快速排序的平均时间最短;
堆排序所需的辅助空间少于快速排序,并且不会出现快速排序可能出现的最坏情况。这两种排序都是不稳定的。
小练习
今天就讲这么多,下面来一道练习题
要选择合适的方法啊(别™使用sort)
排序
题目描述
题目描述
输入三个整数,按由小到大的顺序输出。
输入
三个整数
输出
由小到大输出成一行,每个数字后面跟一个空格
样例输入 复制
2 3 1样例输出 复制
1 2 3 答案在下期公布,下期还需要讲一些数据排序的一些知识点,下下期就得将CSP的内容了