Flink内存调优
Flink内存调优
JVM
我们知道Flink是基于JobManager和TaskManager管理和运行任务,而他们都是以Java进程的形式运行的,所以在了解 Flink 内存时,我们需要先了解一下Java运行时环境Java虚拟机(JVM) 。
JVM 是可运行 Java 代码的假想计算机 ,包括程序计数器、Java 虚拟机栈、本地方法栈、Java 堆 和方法区。JVM 是运行在操作系统之上的,它与硬件没有直接的交互。
JVM 数据运行区
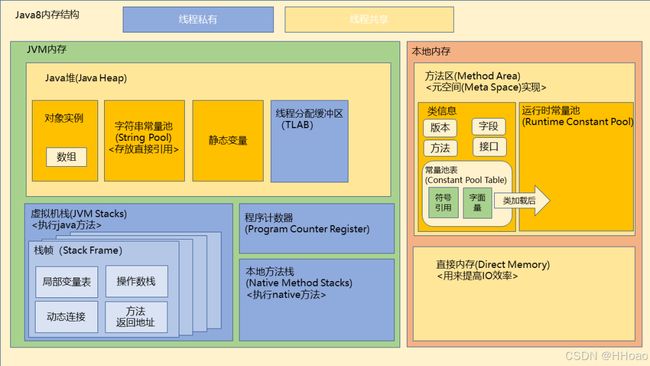
Java 虚拟机在执行 Java 程序的过程中会把它在主存中管理的内存部分划分成多个区域,每个区域存放不同类型的数据。
- 程序计数器:是一个数据结构,用于保存当前正常执行的程序的内存地址。
- JVM虚拟机栈:与线程生命周期相同,用于存储局部变量表,操作栈,方法返回值。
- 本地方法栈**:**跟虚拟机栈很像,不过它是为虚拟机使用到的 Native 方法服务。
- 方法区(元空间):储存虚拟机加载的类信息,常量,静态变量,编译后的代码。
- JVM 堆:存放所有对象的实例。
堆外内存(off-heap memory)
虽然 Java 提供了多种算法进行垃圾回收,但仍然无法彻底解决堆内内存过大带来的长时间的 GC 停顿的问题,以及操作系统对堆内内存不可知的问题。
基于上述问题,Java 虚拟机开辟出了堆外内存(off-heap memory)。堆外内存意味着把一些对象的实例分配在 Java 虚拟机堆内内存以外的内存区域,这些内存直接受操作系统(而不是虚拟机)管理。这样做的结果就是能保持一个较小的堆,以减少垃圾收集对应用的影响。同时因为这部分区域直接受操作系统的管理,别的进程和设备(例如 GPU )可以直接通过操作系统对其进行访问,减少了从虚拟机中复制内存数据的过程。
堆外内存与堆内内存联系
虽然堆外内存本身不受垃圾回收算法的管辖,但是因为其是由 ByteBuffer 所创造出来的,因此这个 buffer 自身作为一个实例化的对象,其自身的信息(例如堆外内存在主存中的起始地址等信息)必须存储在堆内内存中。
JVM 内存管理缺陷
由于在 JVM 内存中存储大量的数据 (包括缓存和高效处理)时,JVM 内存会面临很多问题,包括如下:
- Java 对象存储**密度低。**Java 的对象在内存中存储包含 3 个主要部分:对象头、实例 数据、对齐填充部分。例如,一个只包含 boolean 属性的对象占 16byte:对象头占 8byte, boolean 属性占 1byte,为了对齐达到 8 的倍数额外占 7byte。而实际上只需要一个 bit(1/8 字节)就够了。
- **Full GC 会极大地影响性能。**尤其是为了处理更大数据而开了很大内存空间的 JVM 来说,GC 会达到秒级甚至分钟级。
- **OOM 问题影响稳定性。**OutOfMemoryError 是分布式计算框架经常会遇到的问题, 当 JVM 中所有对象大小超过分配给 JVM 的内存大小时,就会发生 OutOfMemoryError 错误, 导致 JVM 崩溃,分布式框架的健壮性和性能都会受到影响。
- **缓存未命中问题。**CPU 进行计算的时候,是从 CPU 缓存中获取数据。现代体系的 CPU 会有多级缓存,而加载的时候是以 Cache Line 为单位加载。如果能够将对象连续存储, 这样就会大大降低 Cache Miss。使得 CPU 集中处理业务,而不是空转。
Flink内存模型
Flink内部封装了一套自己的内存组件,MemorySegment内存分片是最小的内存单位,Flink通过实现DataInputView接口来更好的控制MemorySegment
MemorySegment
内存分片,控制内存的单位,以下是它的属性:
this.heapMemory = buffer;
this.offHeapBuffer = null;
this.size = buffer.length;
this.address = BYTE_ARRAY_BASE_OFFSET;
this.addressLimit = this.address + this.size;
this.owner = owner;
this.allowWrap = true;
this.cleaner = null;
this.isFreedAtomic = new AtomicBoolean(false);
DataInputView
DataInputView继承DataInput接口
DataInput
void readFully(byte b[]) throws IOException;
void readFully(byte b[], int off, int len) throws IOException;
boolean readBoolean() throws IOException;
byte readByte() throws IOException;
int readUnsignedByte() throws IOException;
short readShort() throws IOException;
int readUnsignedShort() throws IOException;
char readChar() throws IOException;
int readInt() throws IOException;
long readLong() throws IOException;
float readFloat() throws IOException;
double readDouble() throws IOException;
String readLine() throws IOException;
String readUTF() throws IOException;
DataInputView
void skipBytesToRead(int numBytes) throws IOException;
int read(byte[] b, int off, int len) throws IOException;
int read(byte[] b) throws IOException;
常见的StreamTask中数据就是通过NonSpanningWrapper传输的
NonSpanningWrapper
// 数据分片
private MemorySegment segment;
// 目前数据总量,包括已经读取的数据和未读取的数据
private int limit;
// 已读数据位置,表示已读取的数据量,1 字节 = 1 position
private int position;
// 还有多少数据
private int remaining() {
return this.limit - this.position;
}
// 是否还有数据
boolean hasRemaining() {
return remaining() > 0;
}
// 清空数据
void clear() {
this.segment = null;
this.limit = 0;
this.position = 0;
}
// 跳过n个字节
@Override
public final int skipBytes(int n) {
int toSkip = Math.min(n, remaining());
this.position += toSkip;
return toSkip;
}
Flink 内存管理
基于 JVM 内存存在一些问题,并且在大数据场景下,无法在内存中存储海量数据,计算效率无法提高。Flink 社区采用自主内存管理设计,设计了两种内存模型 JobManager 内存模型和 TaskManager 内存模型。
Flink 并不是将大量对象存在堆内存上,而是将对象都序列化到一个预分配的内存块上, 这个内存块叫做 MemorySegment,它代表了一段固定长度的内存(默认大小为 32KB),也是 Flink 中最小的内存分配单元,并且提供了非常高效的读写方法,很多运算可以直接操作 二进制数据,不需要反序列化即可执行。每条记录都会以序列化的形式存储在一个或多个 MemorySegment 中。如果需要处理的数据多于可以保存在内存中的数据,Flink 的运算符会将部分数据溢出到磁盘。
TaskManager和JobManager内存模型
一般情况下TaskManager和JobManager都是单独的Java进程,所以配置参数都是基于Java内存空间进行配置,如堆、直接内存、元空间等。
通常来说一个Java进程的总内存可以通过如下计算:
总内存=堆内存+直接内存+元空间
同样,JobManager和TaskManager也是如此,只是它们又把其中的一些又分为了几部分
JobManager
JobManager在Yarn中的进程的内存是在YarnClusterDescriptor的startAppMaster中设置的,它会先创建JobManagerProcessSpec进程规范,然后再申请容器资源
final JobManagerProcessSpec processSpec =
JobManagerProcessUtils.processSpecFromConfigWithNewOptionToInterpretLegacyHeap(
flinkConfiguration, JobManagerOptions.TOTAL_PROCESS_MEMORY);
final ContainerLaunchContext amContainer =
setupApplicationMasterContainer(yarnClusterEntrypoint, hasKrb5, processSpec);
JobManager总进程内存:
总进程内存 = Flink总内存 + JVM元空间内存 + 用于其他 JVM 开销的内存
Flink总内存 = JVM堆内存 + 非堆内存(直接内存)
可通过如下JobManager配置参数表达:
jobmanager.memory.process.size = jobmanager.memory.flink.size + jobmanager.memory.jvm-metaspace.size + jobmanager.memory.jvm-overhead.size
jobmanager.memory.flink.size = jobmanager.memory.heap.size + jobmanager.memory.off-heap.size
以下是设置了 jobmanager.memory.process.size: 1600m 参数的JobManager内存空间图片:
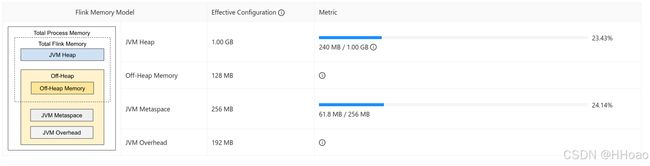
JVM Metaspace = jobmanager.memory.jvm-metaspace.size(Default) = 256MB
Off-Heap Memory = jobmanager.memory.off-heap.size(Default) = 128MB
JVM Heap = Total Process Memory - JVM Overhead - JVM Metaspace -Off-Heap Memory = 1600MB - 192MB - 256MB - 128MB = 1024MB = 1GB
TaskManager
TaskManager在Yarn中的进程内存通过ActiveResourceManager#requestNewWorker设置的,先使用配置创建TaskExecutorProcessSpec进程资源规范,然后直接请求ResourceManager申请进程资源
final TaskExecutorProcessSpec taskExecutorProcessSpec =
TaskExecutorProcessUtils.processSpecFromWorkerResourceSpec(
flinkConfig, workerResourceSpec);
resourceManagerDriver.requestResource(taskExecutorProcessSpec));
TaskManager总进程内存:
总进程内存 = Flink总内存 + 元空间内存 + 用于其他 JVM 开销的内存
Flink总内存 = JVM堆内存 + 管理内存 + 直接内存
JVM堆内存 = 框架堆内存 + 任务堆内存
直接内存 = 框架非堆内存 + 任务非堆内存 + 网络内存
可通过如下TaskManager配置参数表达:
taskmanager.memory.process.size = taskmanager.memory.flink.size + taskmanager.memory.jvm-metaspace.size + taskmanager.memory.jvm-overhead.size
taskmanager.memory.flink.size = JVM堆内存 + taskmanager.memory.managed.size + 直接内存
JVM堆内存 = taskmanager.memory.task.heap.size + taskmanager.memory.framework.heap.size
直接内存 = taskmanager.memory.framework.off-heap.size + taskmanager.memory.task.off-heap.size + 网络内存
设置了 taskmanager.memory.process.size: 1024m 参数的TaskManager内存空间:
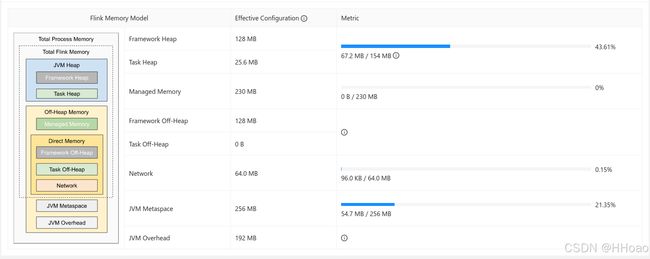
Totoal Flink Memory = (Total Process Memory - JVM Metaspace(Default) - JVM Overhead(Default)) = 1024MB - 256MB - 192MB = 576MB
Framework Off-Heap = taskmanager.memory.framework.off-heap.size(Default) = 128MB
Framework Heap = taskmanager.memory.framework.heap.size(Default) = 128MB
Task Off-Heap = taskmanager.memory.task.off-heap.size(Default) = 0
Network=Math.max(Totoal Flink Memory * taskmanager.memory.network.fraction(Default), taskmanager.memory.network.min(Default)) = Math.max(576MB * 0.1, 1024MB * 0.1) = Math.max(57.6MB, 64.0MB) = 64MB
Managed Memory=Totoal Flink Memory * taskmanager.memory.managed.fraction(Default) = 576MB * 0.4 = 230.4MB
Task Heap = Total Flink Memory - Network - Task Off-Heap - Framework Off-Heap - Managed Memory - Framework Heap = 576M - 64M - 0M - 128M - 230.4M - 128M = 25.6M
注意事项
管理内存默认通过taskmanager.memory.managed.fraction参数配置,默认为taskmanager.memory.managed.fraction * taskmanager.memory.managed.fraction
网络内存默认通过taskmanager.memory.network.fraction,taskmanager.memory.network.min、taskmanager.memory.network.max参数配置,如果taskmanager.memory.network.fraction * taskmanager.memory.managed.fraction小于taskmanager.memory.network.min大小,那么就取taskmanager.memory.network.min大小,如果大于taskmanager.memory.network.max大小,那么就取taskmanager.memory.network.max值
启动JobManager和TaskManager必须配置以下几项配置之一(因为只要配置了其中一个就可以推出总内存大小),但是不要同时配置以下多个配置,因为容易造成配置冲突:
- JobManager
jobmanager.memory.process.sizejobmanager.memory.flink.sizejobmanager.memory.heap.size
- TaskManager
taskmanager.memory.task.heap.size和taskmanager.memory.managed.sizetaskmanager.memory.flink.sizetaskmanager.memory.process.size
那配置上面三个配置有何技巧呢?
- 如果部署于容器(Yarn、Kubernetes)当中,那么最好配置
jobmanager.memory.process.size和taskmanager.memory.process.size,它声明总共应该分配给 Flink JVM 进程多少内存,并与请求的容器的大小相对应。 - 如果通过独立模式(Standalone)运行,那么最好配置Flink总内存
taskmanager.memory.flink.size和jobmanager.memory.flink.size,因为总进程内存并不是很重要,JVM 开销不受 Flink 或部署环境控制,在这种情况下执行机器的物理资源很重要。
如果 Flink 或用户代码分配的非托管堆外(本机)内存超出容器大小,则作业可能会失败,因为部署环境可能会杀死有问题的容器。
以下是设置了 jobmanager.memory.process.size: 1600m 参数的JobManager内存空间图片和设置了 taskmanager.memory.process.size: 1024m 参数的TaskManager内存空间:
Flink内存调优
Configure memory for state backends
部署 Flink 流应用程序时,使用的状态后端类型将决定集群的最佳内存配置,这仅与TaskManager相关。
HashMap state backend
当运行无状态作业或使用 HashMapStateBackend 时,将托管内存设置为零。这将确保为 JVM 上的用户代码分配最大量的堆内存。
RocksDB state backend
EmbeddedRocksDBStateBackend 使用本机内存。默认情况下,RocksDB 设置为将本机内存分配限制为托管内存的大小。因此,为您的状态保留足够的托管内存非常重要。如果禁用默认的 RocksDB 内存控制,并且 RocksDB 分配的内存超过请求的容器大小(总进程内存)的限制,TaskManager 可能会在容器化部署中被终止。另请参阅如何调整 RocksDB 内存和 state.backend.rocksdb.memory.management。
Configure memory for batch jobs
Flink 的批处理运算符利用托管内存来更高效地运行。这样做,可以直接对原始数据执行某些操作,而无需反序列化为 Java 对象。这意味着托管内存配置会对应用程序的性能产生实际影响。 Flink 将尝试分配和使用为批处理作业配置的尽可能多的托管内存,但不会超出其限制。这可以防止 OutOfMemoryError 的出现,因为 Flink 准确地知道它需要利用多少内存。如果托管内存不够,Flink 会优雅地溢出到磁盘。
QA
1. 什么是托管内存(Managed Memory)
托管内存由 Flink 管理,并作为本机内存(堆外)进行分配。以下工作负载使用托管内存:
- 流作业可以将其用于 RocksDB 状态后端。
- 流式处理和批处理作业都可以使用它进行排序、哈希表、中间结果的缓存。
- 流处理和批处理作业都可以使用它在 Python 进程中执行用户定义的函数。
2. 框架堆外内存和任务堆外内存的区别是什么?
任务堆外内存为由用户代码分配的堆外内存, 给Flink框架分配的堆外内存为框架堆外内存
3. JobManager的JVM Heap用途和配置依据是什么?
JVM Heap的用途:
- Flink框架
- 在作业提交期间(例如,对于某些批处理源)或在Checkpoint完成回调中执行的用户代码
JVM 堆所需的大小主要由正在运行的作业数量、作业结构以及上述用户代码的要求决定。
4. JobManager的堆外内存用途是什么?
JobManager的堆外内存用途:
- Flink 框架网络通信等使用直接内存的地方
- 在作业提交期间(例如,对于某些批处理源)或在检查点完成回调中执行的用户代码
5. 如果出现OutOfMemoryError: Java heap space怎么办?
该异常通常表明 JVM Heap 太小。您可以尝试通过增加总内存来增加 JVM 堆大小。您还可以直接增加 TaskManager 的任务堆内存或 JobManager 的 JVM 堆内存。您也增加 TaskManager 的框架堆内存,但只有在确定 Flink 框架本身需要更多内存时才应更改此选项。
6. 如果出现OutOfMemoryError: Direct buffer memory怎么办?
该异常通常表明JVM直接内存限制太小或者存在直接内存泄漏。检查用户代码或其他外部依赖项是否使用 JVM 直接内存以及是否已正确说明。您可以尝试通过调整直接堆外内存来增加其限制。
7. 如果出现OutOfMemoryError: Metaspace怎么办?
该异常通常表明JVM元空间限制配置得太小。您可以尝试增加TaskManagers或JobManagers的JVM元空间选项。
8. 如果出现IOException: Insufficient number of network buffers怎么办?
这仅与TaskManagers有关,该异常通常表明配置的网络内存大小不够大。您可以尝试通过调整网络参数来增加网络内存。
9. 如果Yarn或者Kubernetes出现Container Memory Exceeded怎么办?
如果 Flink 容器尝试分配超出其请求大小(Yarn 或 Kubernetes)的内存,这通常表明 Flink 没有预留足够的本机内存。您可以通过使用外部监控系统或从容器被部署环境终止时的错误消息来观察这一点。
如果您在JobManager进程中遇到此问题,还可以通过设置 jobmanager.memory.enable-jvm-direct-memory-limit 选项来启用JVM Direct Memory限制,以排除可能的JVM Direct Memory泄漏。
如果使用RocksDBStateBackend:
- 并且内存控制被禁用:您可以尝试增加TaskManager的托管内存。
- 并且内存控制已启用,并且在保存点或完整检查点期间非堆内存增加:这可能是由于
glibc内存分配器导致的(请参阅 glibc bug)。您可以尝试为TaskManagers添加环境变量MALLOC_ARENA_MAX=1。
或者,您可以增加 JVM 开销。
总结:
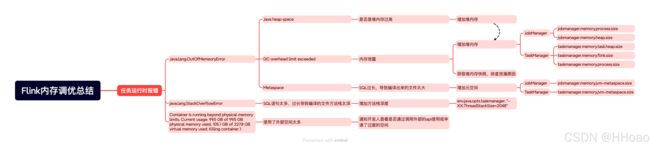
遇到任务错误时需要进行如下步骤:
-
查看日志线索,看yarn ui上面的历史信息,日志报错信息
-
判断是否为内存错误,例如出现Memory、Metaspace、GC、Heap或Stack等关键字
-
判断内存错误属于哪一类
- Metaspace:元空间
- Directory Memory:直接内存
- GC:堆内存
- Heap Memory:堆内存
- Stack:本地方法栈
-
通过查看Java内存区域介绍查看错误类别的相关出现的点
- 元空间:类型信息、常量、静态变量、即时编译器编译后的代码缓存等数据
- 直接内存:NIO(New Input/Output)、通道(Channel)、缓冲区(Buffer)等IO相关点
- Heap Memory、GC:垃圾收集,对象创建
- Stack:方法深度
-
详细这些点可能在Flink程序中出现的点
- 元空间:Flink SQL代码需要编译成Java类,可能会导致编译出来的类太大而超出元空间等
- 直接内存:IO、Buffer、Channel和网络相关,是否网络波动大,传输量大
- Heap Memory:是否存在代码块内存泄漏
- Stack:Flink SQL代码需要编译成Java类,可能会导致编译出来的类相同方法调用栈太深、出现递归等
-
根据问题出现的时机调整相关Flink参数:
-
元空间:
jobmanager.memory.jvm-metaspace.size、taskmanager.memory.jvm-metaspace.size -
直接内存:
-
作业提交
jobmanager.memory.off-heap.size、taskmanager.memory.framework.off-heap.size、taskmanager.memory.task.off-heap.size、 -
作业运行
-
-
Heap Memory
-
-
如果Flink没有相关参数,那么可以根据JVM相关参数配合Flink参数进行调整,例如:
- Stack:
env.java.opts.taskmanager: "-XX:ThreadStackSize=2048"
- Stack:
-
查看Flink UI和日志查看参数是否生效
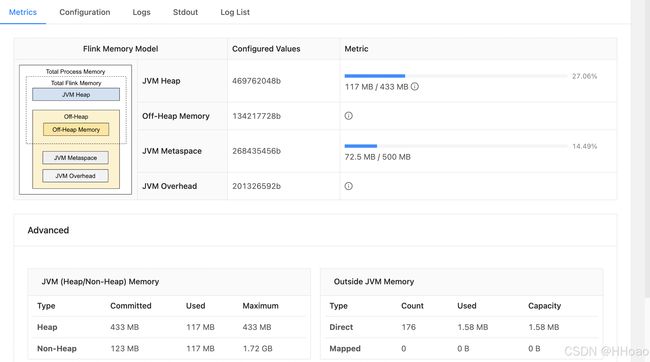
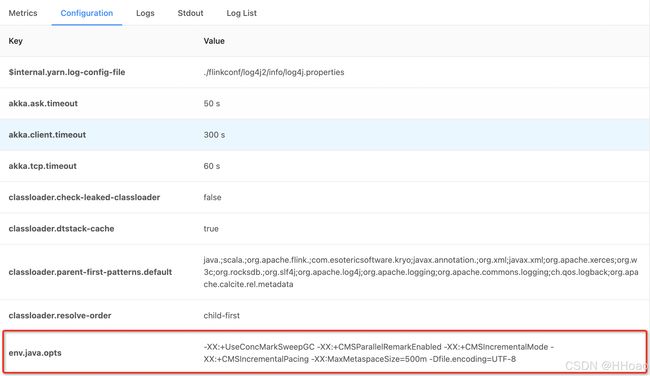
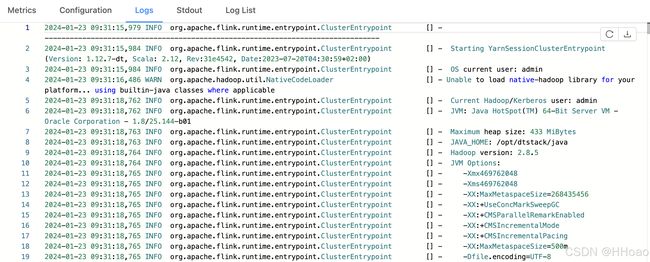
-
如果问题还没解决或者是内存泄漏相关问题,那么就找开发人员解决
相关问题
-
Container is running beyond physical memory limits. Current usage: 99.5 GB of 99.5 GB physical memory used; 105.1 GB of 227.8 GB virtual memory used. Killing container.1
常见于:网络波动过大、通过调用外部的api使用或申请空间
相关问题:http://zenpms.dtstack.cn/zentao/bug-view-98135.html
-
java.lang.StackOverflowError
org.apache.flink.util.FlinkRuntimeException: org.apache.flink.api.common.InvalidProgramException: Table program cannot be compiled. This is a bug. Please file an issue. …
常见于:SQL过长导致创建的文件过大
问题链接:http://zenpms.dtstack.cn/zentao/bug-view-99976.html
-
Java.lang.OutOfMemeoryError:Metaspace
调整taskmanager.memory.jvm-metaspace.size
常见于:SQL语句过多导致编译出来的方法栈太深
相关问题:http://zenpms.dtstack.cn/zentao/bug-view-38792.html
引用
- Flink配置:https://nightlies.apache.org/flink/flink-docs-release-1.18/docs/deployment/config/#memory-configuration
- 设置Flink进程内存:https://nightlies.apache.org/flink/flink-docs-release-1.18/docs/deployment/memory/mem_setup/
- 设置TaskManager内存:https://nightlies.apache.org/flink/flink-docs-release-1.18/docs/deployment/memory/mem_setup_tm/
- 设置JobManager内存:https://nightlies.apache.org/flink/flink-docs-release-1.18/docs/deployment/memory/mem_setup_jobmanager/
- 内存调优:https://nightlies.apache.org/flink/flink-docs-release-1.18/docs/deployment/memory/mem_tuning/
- 故障排查:https://nightlies.apache.org/flink/flink-docs-release-1.18/docs/deployment/memory/mem_trouble/#container-memory-exceeded
- 网络内存调优指南:https://nightlies.apache.org/flink/flink-docs-release-1.18/docs/deployment/memory/network_mem_tuning/
- Flink1.14.0内存优化你不懂?:https://cloud.tencent.com/developer/article/1893333
Java内存区域术语以及Flink配置参数:
JVM内存区域术语
-
程序计数器(Program Counter Register)
程序计数器是一块较小的内存空间,它可以看作是当前线程所执行的字节码的行号指示器。在 Java 虚拟机的概念模型里,字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,它是程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。
由于 Java 虚拟机的多线程是通过线程轮流切换、分配处理器执行时间的方式来实现的,在任何一个确定的时刻,一个处理器(对于多核处理器来说是一个内核)都只会执行一条线程中的指令。因此,为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各条线程之间计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。
如果线程正在执行的是一个 Java 方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;如果正在执行的是本地(Native)方法,这个计数器值则应为空。此内存区域是唯一一个在《Java 虚拟机规范》中没有规定任何OutOfMemoryError 情况的区域。
-
虚拟机栈 (Java Virtual Machine Stack)
与程序计数器一样,Java 虚拟机栈也是线程私有的,它的生命周期与线程相同。虚拟机栈描述的是 Java 方法执行的线程内存模型:每个方法被执行的时候,Java 虚拟机都会同步创建一个栈帧用于存储局部变量表、操作数栈、动态连接、方法出口等信息。每一个方法被调用直至执行完毕的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。
如果线程请求的栈深度大于虚拟机所允许的深度,将抛出 StackOverflowError 异常;
-
本地方法栈(Native Method Stacks)
本地方法栈与虚拟机栈所发挥的作用是非常相似的,其区别只是虚拟机栈为虚拟机执行 Java 方法(也就是字节码)服务,而本地方法栈则是为虚拟机使用到的本地(Native)方法服务。
与虚拟机栈一样,本地方法栈也会在栈深度溢出或者栈扩展失败时分别抛出 StackOverflowError 和OutOfMemoryError 异常。
-
Java堆(Java Heap)
对于 Java 应用程序来说,Java 堆是虚拟机所管理的内存中最大的一块,是被所有线程共享的和垃圾收集器管理的一块内存区域,在虚拟机启动时创建,一些资料中它也被称作“GC 堆”。此内存区域的唯一目的就是存放对象实例,Java 世界里“几乎”所有的对象实例都在这里分配内存。
可通过参数-Xmx 和-Xms 设定,如果在 Java 堆中没有内存完成实例分配,并且堆也无法再扩展时,Java 虚拟机将会抛出 OutOfMemoryError 异常。
-
本地内存(Native Memory)和主内存(Main Memory)
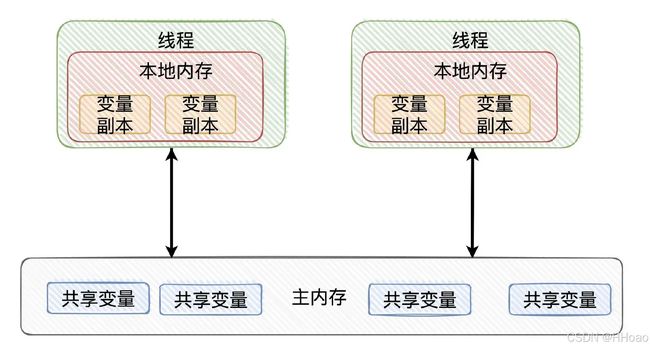
Java线程之间的通信采用的是共享内存模型,这里提到的共享内存模型指的就是Java内存模型 (JMM),决定一个线程对共享变量的写入何时对另一个线程可见。
从抽象的角度来看,Java内存模型定义了线程和主内存(物理内存)之间的抽象关系:线程之间的共享变量存储在主内存中,线程被CPU执行,每个线程都有一个私有的本地内存(如CPU的高速缓存),本地内存中存储了该线程以读/写共享变量的副本。
本地内存是Java内存模型的一个抽象概念,并不真实存在;它涵盖了缓存,写缓冲区,寄存器以及其他的硬件和编译器优化。
本地内存也称为C-Heap,是供JVM自身进程使用的,当Java Heap空间不足时会触发GC,但本地内存空间不够却不会触发GC。
-
方法区(Method Area)(元空间Metaspace)
方法区(Method Area)与 Java 堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等数据。
-
元空间
在Java8中,使用元空间实现了方法区,元空间存在于本地内存(Native memory)中。
默认情况下元空间是可以无限使用本地内存的,但为了不让它如此膨胀,JVM同样提供了参数来限制它使用的使用。
- -XX:MetaspaceSize,class metadata的初始空间配额,以bytes为单位,达到该值就会触发垃圾收集进行类型卸载,同时GC会对该值进行调整:如果释放了大量的空间,就适当的降低该值;如果释放了很少的空间,那么在不超过MaxMetaspaceSize(如果设置了的话),适当的提高该值。
- -XX:MaxMetaspaceSize,可以为class metadata分配的最大空间。默认是没有限制的。
- -XX:MinMetaspaceFreeRatio,在GC之后,最小的Metaspace剩余空间容量的百分比,减少为class metadata分配空间导致的垃圾收集。
- -XX:MaxMetaspaceFreeRatio,在GC之后,最大的Metaspace剩余空间容量的百分比,减少为class metadata释放空间导致的垃圾收集。
-
运行时常量池
运行时常量池(Runtime Constant Pool)是方法区的一部分。Class 文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池表(Constant Pool Table),用于存放编译期生成的各种字面量与符号引用,这部分内容将在类加载后存放到方法区的运行时常量池中。
运行时常量池相对于 Class 文件常量池的另外一个重要特征是具备动态性,Java运行期间可以将新的常量放入常量池中,这种特性被开发人员利用得比较多的便是 String 类的 intern()方法。
既然运行时常量池是方法区的一部分,自然受到方法区内存的限制,当常量池无法再申请到内存时会抛出 OutOfMemoryError 异常。
-
-
直接内存(Direct Memory)
在 JDK 1.4 中新加入了 NIO(New Input/Output)类,引入了一种基于通道(Channel)与缓冲区(Buffer)的 I/O 方式,它可以使用 Native 函数库直接分配堆外内存,然后通过一个存储在 Java 堆里面的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样能在一些场景中显著提高性能,因为避免了在 Java 堆和 Native 堆中来回复制数据。
直接内存的容量大小可以通过 -XX:MaxDirectMemorySize参数来制定,如果不指定,则默认与Java堆最大值(由Xmx制定)一致。
显然,直接内存的分配不会受到 Java 堆大小的限制,但是,既然是内存,则肯定还是会受到本机总内存(包括物理内存、SWAP 分区或者分页文件)大小以及处理器寻址空间的限制,一般服务器管理员配置虚拟机参数时,会根据实际内存去设置-Xmx
等参数信息,但经常忽略掉直接内存,使得各个内存区域总和大于物理内存限制(包括物理的和操作系统级的限制),从而导致动态扩展时出现 OutOfMemoryError 异常
Flink内存参数
堆内存相关:
| **Component ** | **Configuration options ** | **Description ** | Default |
|---|---|---|---|
| JVM Heap | jobmanager.memory.heap.size | JobManager的 JVM 堆内存大小。 | none |
| Framework Heap Memory | taskmanager.memory.framework.heap.size | Flink框架专用的JVM Heap内存(高级选项) | 128mb |
| Task Heap Memory | taskmanager.memory.task.heap.size | JVM Heap 内存专用于 Flink 应用程序运行算子和用户代码 | none |
元空间相关:
| **Component ** | **Configuration options ** | **Description ** | Default |
|---|---|---|---|
| JVM metaspace | jobmanager.memory.jvm-metaspace.size | Flink JVM进程的Metaspace大小 | 256mb |
| JVM metaspace | taskmanager.memory.jvm-metaspace.size | Flink JVM进程的Metaspace大小 | 256mb |
直接内存相关:
| **Component ** | **Configuration options ** | **Description ** | Default |
|---|---|---|---|
| Off-heap | jobmanager.memory.off-heap.size | JobManager的堆外内存大小。此选项涵盖所有堆外内存使用,包括直接内存分配和本地内存分配。 | |
| Framework Off-heap Memory | taskmanager.memory.framework.off-heap.size | 专用于 Flink 框架的堆外直接(或本机)内存(高级选项) | 128mb |
| Task Off-heap Memory | taskmanager.memory.task.off-heap.size | 堆外直接(或本地)内存专用于 Flink 应用程序运行算子 | 0 |
| Network Memory | taskmanager.memory.network.min taskmanager.memory.network.max taskmanager.memory.network.fraction | 为任务之间的数据记录交换而保留的直接内存(例如,用于通过网络传输的缓冲)是总 Flink 内存的有上限的部分。该内存用于分配网络缓冲区 |
其他
| Component 成分 | **Configuration options ** | **Description ** | Default |
|---|---|---|---|
| Process Memory | jobmanager.memory.process.size | JobManager 的总进程内存大小。这包括 JobManager JVM 进程消耗的所有内存,包括 Flink 总内存、JVM 元空间和 JVM 开销。在容器化设置中,应将其设置为容器内存。 | none |
| Flink Memory | jobmanager.memory.flink.size | JobManager 的 Flink 总内存大小。这包括 JobManager 消耗的所有内存,JVM 元空间和 JVM 开销除外。它由JVM堆内存和堆外内存组成。另请参阅 | none |
| Off-heap | jobmanager.memory.off-heap.size | JobManager的堆外内存大小。此选项涵盖所有堆外内存使用,包括直接内存分配和本地内存分配。 | 128mb |
| JVM metaspace | jobmanager.memory.jvm-metaspace.size | Flink JVM进程的Metaspace大小 | 256mb |
| JVM Overhead | jobmanager.memory.jvm-overhead.min jobmanager.memory.jvm-overhead.max jobmanager.memory.jvm-overhead.fraction | 本地内存是为其他 JVM 开销保留的:例如线程堆栈、代码缓存、垃圾收集空间等,它是总进程内存的上限部分 | 192mb、1gb、0.1 |
| **Component ** | **Configuration options ** | **Description ** | Default |
|---|---|---|---|
| Process Memory | taskmanager.memory.process.size | TaskExecutor的总进程内存大小。这包括 TaskExecutor 消耗的所有内存,包括 Flink 总内存、JVM 元空间和 JVM 开销。在容器化设置中,应将其设置为容器内存。 | none |
| Flink Memory | taskmanager.memory.flink.size | TaskExecutor 的 Flink 总内存大小。这包括 TaskExecutor 消耗的所有内存,JVM 元空间和 JVM 开销除外。它由框架堆内存、任务堆内存、任务堆外内存、托管内存和网络内存组成。 | none |
| taskmanager.memory.framework.off-heap.batch-shuffle.size | batch shuffle用于shuffle数据读取的内存大小(当前仅由排序洗牌和混合洗牌使用)。注意:1)内存是从 ‘taskmanager.memory.framework.off-heap.size’ 中削减的,因此必须小于该值,这意味着您可能还需要增加 'taskmanager.memory.framework.off-heap.size’增加此配置值后; 2) 此内存大小会影响 shuffle 性能,对于大规模批处理作业,您可以增加此配置值(例如,增加到 128M 或 256M) | 64mb | |
| Managed memory | taskmanager.memory.managed.size taskmanager.memory.managed.fraction | TaskManager的managed内存大小。这是TaskManager管理的堆外内存的大小,保留用于排序、哈希表、中间结果缓存和 RocksDB 状态后端。如果没有指定则通过fraction来配置内存大小,fraction使用Flink Memory的fraction作为managed内存大小(这时必须得指明taskmanager.memory.flink.size) | none、0.4 |
| JVM Overhead | taskmanager.memory.jvm-overhead.min taskmanager.memory.jvm-overhead.max taskmanager.memory.jvm-overhead.fraction | 为其他 JVM 开销保留本地内存:例如线程堆栈、代码缓存、垃圾收集空间等,它是总进程内存的上限部分 | 192mb、1gb、0.1 |
通过直接配置JVM参数设置内存参数:
| **Component ** | **Configuration options ** | **Description ** | Default |
|---|---|---|---|
| env.java.opts.all | (none) | String | 用于启动所有 Flink 进程的 JVM 的 Java 选项。 |
| env.java.opts.client | (none) | String | 用于启动 Flink 客户端 JVM 的 Java 选项。 |
| env.java.opts.historyserver | (none) | String | 用于启动 HistoryServer 的 JVM 的 Java 选项。 |
| env.java.opts.jobmanager | (none) | String | 用于启动 JobManager 的 JVM 的 Java 选项。 |
| env.java.opts.taskmanager | (none) | String | 用于启动 TaskManager 的 JVM 的 Java 选项。 |