postgresql查询的处理过程
本文简单描述了Postgresql服务器接收到查询后到返回给客户端结果之间一般操作顺序,总的流程图如下:
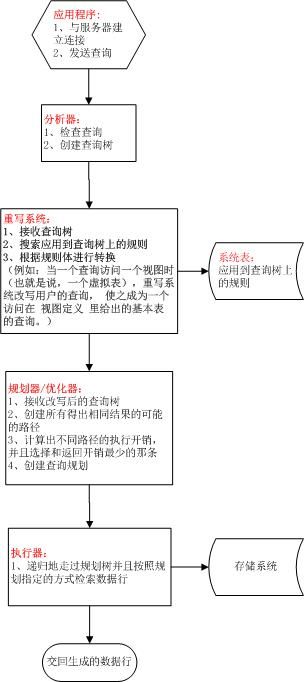
第一步:
客户端程序可以是任何符合 PostgreSQL 协议规范的程序,如 JDBC 驱动。PostgreSQL 服务器使用 postmaster 主进程对特定的TCP/IP端口进行监听,当有客户端发出连接请求时,postmaster 主进程派生出一个新的叫 postgres 的服务器进程与客户端进行通信。 postgres 进程之间使用信号灯和共享内存进行通信,以确保在并行的数据访问过程中的数据完整性。一旦建立起来连接, 客户端进程就可以向服务器进程(postgres进程)发送查询了,查询是通过纯文本传输的。
第二步:
查询发送到服务器进程之后,服务器进程(postgres进程)调用分析器检查分析查询字串的语法。检查分析阶段分为两个过程:裸分析和语意分析。
(1)裸分析
分析器首先检查查询字串的语法,如果语法正确,则创建一个分析树, 否则返回错误。Postgresql使用著名的Unix工具 lex 和 yacc来构建分析器和词法器。词法器在文件 scan.l里定义,负责识别标识符,SQL 关键字等,对于发现的每个关键字或者标识符都会生成一
个标记并且传递给分析器;分析器在文件 gram.y 里定义,包含一套语法规则和触发规则时执行的动作。 动作代码(实际上是 C 代码)用于建立分析树。
(2)语意分析
在分析器处理之后,转换处理程序接收分析器传过来的分析树, 解析语意(语意理解查询中引用了哪个表,哪个函数以及哪个操作符),生成查询树。本过程生成的查询树在很大程度上类似于裸分析阶段生成的分析树,但是在细节上有很多区别。 比如,在分析树里的 FuncCall 节点代表那些看上去像函数调用的东西。 根据引用的名字是一个普通函数还是一个聚集函数, 这个可能被转换成一个 FuncExpr 或者一个 Aggref 节点。 同样,有关字段和表达式结果的具体数据类型也添加到查询树中。
第三步:
重写系统是一个存在于分析器阶段和规划器/优化器之间的一个模块,输入和输出都是查询树。
第四步:
规划器/优化器的任务是创建一个优化后的执行规划。 SQL 查询根据每个关系(实际上就是表)上索引的不同,可以以多种不同的方式执行。
对一个关系总是可以进行一次顺序查找, 所以总是会创建只使用顺序查找的规划。 假设一个关系上定义着一个索引(例如 B-tree 索引), 并且一条查询包含约束 relation.attribute OPR constant,如果 relation.attribute 碰巧匹配 B-tree 索引的关键字并且
OPR 又是列出在索引的操作符表中的操作符中的一个, 那么将会创建一个使用 B-tree 索引扫描该关系的规划。 如果还有别的索引, 而且查询里面的约束又和那个索引的关键字匹配,则还会生成更多的规划。有三种可能的连接策略:
嵌套循环连接:对左边的关系里面找到的每条元组都对右边关系进行一次扫描。 这个策略容易实现,但是可能会很耗费时间。 (但是,如果右边的关系可以用索引扫描,那么这个可能就是个好策略。 我们可以用来自左手边关系的当前行的数值为键字进行对右手边关系
的索引扫描。)
融合排序连接:在连接开始之前,每个关系都对连接字段进行排序。 然后对两个关系并行扫描,匹配的行就组合起来形成连接行。 这种联合更有吸引力,因为每个关系都只用扫描一次。 要求的排序步骤可以通过明确的排序步骤,或者是使用连接键字上的索引按照恰当
的顺序扫描关系。
散列连接:首先扫描右边的关系,并用连接的字段作为散列键字装载进入一个散列表, 然后扫描左边的关系,并将找到的每行用作散列键字来以定位表里匹配的行。
在寻找完所有可能的单个关系的规划后, 接着创建连接各个关系的规划。 规划器/优化器首先考虑在 WHERE 条件里存在连接子句的连接(比如 where rel1.attr1=rel2.attr2),没有连接子句的的连接只会在没有别的选择的时候才考虑,规划器/优化器为它们认为可能 的所有的连接关系对生成规划,检查不同的连接顺序可能,找出开销最小的。
不论使用何种规划,最终都会生成相同的结果集。如果可能,查询优化器将检查每个可能的执行规划,最终选择认为运行最快的执行规划。在有些情况下,特别是在正在执行的查询涉及大量连接操作的时候,检查一个查询所有可能的执行方式会花去很多时间和内存空间
,为了在合理的时间里判断一个合理的(而不是优化的)查询计划, PostgreSQL 使用“基因查询优化”。
第五步:
执行器接受规划器/优化器传过来的查询规划后进行递归处理,抽取所需要的行集合。执行器处理所有的四种基本 SQL 查询类型: SELECT,INSERT,UPDATE, 和 DELETE。对于 SELECT 而言,顶层的执行器代码发送查询规划树返回的每一行给客户端。 对于 INSERT,查询规划树返回的每一行都插入到 INSERT 声明的目标表中。 (一个简单的 INSERT ... VALUES 命令创建一个简单的规划树,包含一个 Result 节点,它只计算得出一个结果行。 但是 INSERT ... SELECT 可能需要执行器的全部能力。) 对于 UPDATE,规划器安排每个计算出来的行都包括所有更新的字段,加上原来的目标行的 TID (元组 ID,或者行 ID); 执行器的顶层使用这些信息创建一个新的更新过的行,并且标记旧行被删除。对于 DELETE, 规划实际上返回的唯一的一个字段是 TID,然后执行器的顶层简单地使用这个 TID 访问每个目标行,并且把它们标记为已删除。