(Kafka源码四)生产者发送消息到broker
通过上章对缓存池的介绍,我们可以知道生产者会先将消息批次对象放入
RecordAccumulator的双端队列中,当满足一定条件时消息才发送至broekr,本文将从源码角度分析当达到什么条件才发送消息,以及生产者对broker发送回来的响应是如何处理的,对于粘包和拆包问题,生产者是如何解决的,另外,生产者对于超时的,异常的,长时间未处理的消息批次是分别怎么处理的都将在本文介绍。
消息的发送条件
首先来看看sender线程的run方法源码,通过(Kafka源码一)生产者初始化及分区策略的介绍,我们可以知道,sender线程的run方法一经启动就一直在运行
//Sender.java
void run(long now) {
//判断哪些分区有消息可以发送到broker
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
}
//RecordAccumulator.java
public ReadyCheckResult ready(Cluster cluster, long nowMs) {
//用于记录已经准备好的主机
Set<Node> readyNodes = new HashSet<>();
long nextReadyCheckDelayMs = Long.MAX_VALUE;
//记录没有找到主机的主题
Set<String> unknownLeaderTopics = new HashSet<>();
//若waiters队列不为空,说明内存池的内存已经用完了
boolean exhausted = this.free.queued() > 0;
//遍历所有的主题分区
for (Map.Entry<TopicPartition, Deque<RecordBatch>> entry : this.batches.entrySet()) {
//获取分区
TopicPartition part = entry.getKey();
//获取分区对应的双端队列
Deque<RecordBatch> deque = entry.getValue();
//通过分区获取这个分区的leader副本所在的主机
Node leader = cluster.leaderFor(part);
//加锁
synchronized (deque) {
//没有找到分区对应的主机且队列不为空
if (leader == null && !deque.isEmpty()) {
//将主题添加到集合中,以便下一次拉取该主题的元数据信息
unknownLeaderTopics.add(part.topic());
} else if (!readyNodes.contains(leader) && !muted.contains(part)) {
//从队列的首部获取消息批次
RecordBatch batch = deque.peekFirst();
//若消息批次不null,判断是否可以发送
if (batch != null) {
/*
* batch.attempts:表示重试的次数
* batch.lastAttemptMs:上次重试的时间
* retryBackoffMs:重试的时间间隔
* backingOff:判断重新发送数据的时间是否到了
*/
boolean backingOff = batch.attempts > 0 && batch.lastAttemptMs + retryBackoffMs > nowMs;
/*
* nowMs: 当前时间
* batch.lastAttemptMs:上次重试的时间
* waitedTimeMs表示当前的消息批次已经等了多长时间
*/
long waitedTimeMs = nowMs - batch.lastAttemptMs;
// 表示当前消息最多存多久就需要要发送出去,默认是lingerMs=0ms
long timeToWaitMs = backingOff ? retryBackoffMs : lingerMs;
/*
* timeToWaitMs: 最多能等待多长的时间
* waitedTimeMs: 已经等待了多久
* timeLeftMs: 还需要等待多久
*/
long timeLeftMs = Math.max(timeToWaitMs - waitedTimeMs, 0);
//若双端队列的消息批次大于1个或者刚好一个且这一个消息批次写满了
boolean full = deque.size() > 1 || batch.records.isFull();
/*
* waitedTimeMs:已经等了多长时间
* timeToWaitMs:最多需要等待多久
* expired: 等待的时间是否到了,若expired=true 代表就是等待时间已经到了,此时可以发送消息
*/
boolean expired = waitedTimeMs >= timeToWaitMs;
/*
* 1)full: 如果一个批次写满了
* 2)expired:设置的超时时间到期了
* 3)exhausted:内存池的内存不够
* 4)后面两个参数表示关闭生产者线程时,需要将缓存中的数据发送kafka集群中
*/
boolean sendable = full || expired || exhausted || closed || flushInProgress();
//可以发送消息
if (sendable && !backingOff) {
//把可以发送消息批次的分区的leader副本所在的主机加入到集合中
readyNodes.add(leader);
} else {
nextReadyCheckDelayMs = Math.min(timeLeftMs, nextReadyCheckDelayMs);
}
}
}
}
}
//返回判断的结果
return new ReadyCheckResult(readyNodes, nextReadyCheckDelayMs, unknownLeaderTopics);
}
总结一下这个ready方法做的事就是判断消息批次是否满足发送的条件,可以归纳为如下四个条件,满足任一个条件都会触发sender线程发送消息至broker
- 队列中至少有一个消息批次写满了
- 设置的超时时间到期了,默认是lingerMs=0ms
- 当内存池的内存不够时,此时会将消息批次发送到broker,以便将消息批次占用的内存释放回内存池中
- 当生产者关闭网络连接时,生产者会将队列中的消息批次发往broker
发送消息
当满足四个条件之一时,消息就可以发往broker了,在发送之前会先将发送的请求缓存在inFlightRequests的集合中,(每个主机最多缓存5个已经发送出去但是还没有接收到响应的客户端请求)
//Sender.java
void run(long now) {
//TODO 发送请求的操作
for (ClientRequest request : requests)
//绑定 op_write事件
client.send(request, now);
}
//接口
public void send(ClientRequest request, long now);
//接口的实现类
public void send(ClientRequest request, long now) {
String nodeId = request.request().destination();
if (!canSendRequest(nodeId))
throw new IllegalStateException("Attempt to send a request to node " + nodeId + " which is not ready.");
//存储发送的请求
doSend(request, now);
}
//NetworkClient.java
private void doSend(ClientRequest request, long now) {
request.setSendTimeMs(now);
//缓存请求(每个主机最多可以缓存5个发送出去但是还没有接收到响应的请求),
//当成功接收到响应时,就会从该集合中移除请求
this.inFlightRequests.add(request);
//注册OP_WRITE事件
selector.send(request.request());
}
缓存完请求且注册了OP_WRITE事件后就可以通过Selector的方法pollSelectionKeys()发送请求到broker了
//Selector.java
private void pollSelectionKeys(Iterable<SelectionKey> selectionKeys,
boolean isImmediatelyConnected,
long currentTimeNanos) {
//获取到所有key
Iterator<SelectionKey> iterator = selectionKeys.iterator();
//遍历所有的key
while (iterator.hasNext()) {
//获取迭代器的当前key
SelectionKey key = iterator.next();
//从selector移除该key
iterator.remove();
//通过key找到对应的KafkaChannel
KafkaChannel channel = channel(key);
//检测到时写数据事件
if (channel.ready() && key.isWritable()) {
//将请求发送至服务端broker,然后移除OP_WRITE的监听
Send send = channel.write();
//若已经完成响应消息的发送
if (send != null) {
//将请求的发送结果添加到已经完成发送的请求集合中
this.completedSends.add(send);
//记录channel的id
this.sensors.recordBytesSent(channel.id(), send.size());
}
}
}
}
响应消息的处理
响应消息的流程图
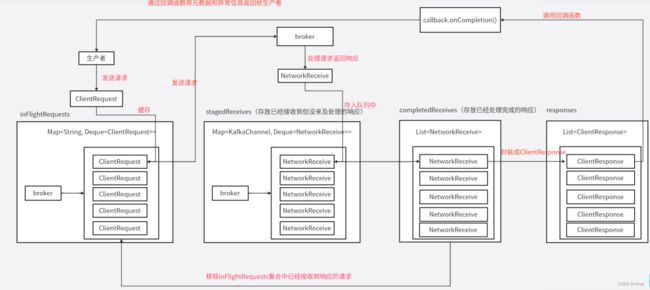
broker返回的响应首先会放入stagedReceives(该集合存放已经接收到但还没来得及处理的响应)集合中,至于broker是怎么处理请求的将在下章讲解。
private void pollSelectionKeys(Iterable<SelectionKey> selectionKeys,
boolean isImmediatelyConnected,
long currentTimeNanos) {
//获取到所有key
Iterator<SelectionKey> iterator = selectionKeys.iterator();
//遍历所有的key
while (iterator.hasNext()) {
//获取迭代器的当前key
SelectionKey key = iterator.next();
//从selector移除该key
iterator.remove();
//通过key找到对应的KafkaChannel
KafkaChannel channel = channel(key);
//若有读数据事件,说明broker返回响应了
if (channel.ready() && key.isReadable() && !hasStagedReceive(channel)) {
//服务端发送回来的响应
NetworkReceive networkReceive;
//不断的读取数据,粘包和拆包问题也是在这里解决的
while ((networkReceive = channel.read()) != null)
//将响应放入stagedReceives集合中(该集合存放已经接收到但还没来得及处理的响应)
addToStagedReceives(channel, networkReceive);
}
}
}
接着会将stagedReceives集合中的响应放入completedReceives(该队列用于存放已经接收到且已经处理完成的响应)队列中
//Selector.java
public void poll(long timeout) throws IOException {
//对stagedReceives里面的响应添加到completedReceives队列中
addToCompletedReceives();
}
//Selector.java
private void addToCompletedReceives() {
if (!this.stagedReceives.isEmpty()) {
Iterator<Map.Entry<KafkaChannel, Deque<NetworkReceive>>> iter = this.stagedReceives.entrySet().iterator();
//遍历stagedReceives集合
while (iter.hasNext()) {
Map.Entry<KafkaChannel, Deque<NetworkReceive>> entry = iter.next();
//获取连接
KafkaChannel channel = entry.getKey();
if (!channel.isMute()) {
//获取每个连接对应的队列
Deque<NetworkReceive> deque = entry.getValue();
//获取到响应
NetworkReceive networkReceive = deque.poll();
//把响应添加到completedReceives队列中
this.completedReceives.add(networkReceive);
this.sensors.recordBytesReceived(channel.id(), networkReceive.payload().limit());
//若队列为空,说明该连接的所有响应已经处理完,因此移除该连接的元素
if (deque.isEmpty())
iter.remove();
}
}
}
}
然后通过handleCompletedSends方法将completedReceives列表里的网络响应封装成客户端响应,之后handleCompletedReceives方法将会从inFlightRequests集合中移除已经接收到响应的请求,对于每个响应,生产者通过回调函数callback.onCompletion()处理响应。
//NetworkClient.java
public List<ClientResponse> poll(long timeout, long now) {
long updatedNow = this.time.milliseconds();
//用于存放客户端响应
List<ClientResponse> responses = new ArrayList<>();
//将网络响应封装成客户端响应
handleCompletedSends(responses, updatedNow);
//处理响应,从inFlightRequests集合中移除请求
handleCompletedReceives(responses, updatedNow);
//遍历broker返回给客户端的响应,调用回调函数将响应返回给客户端
for (ClientResponse response : responses) {
if (response.request().hasCallback()) {
try {
//调用回调函数将响应返回给客户端
response.request().callback().onComplete(response);
} catch (Exception e) {
log.error("Uncaught error in request completion:", e);
}
}
}
//返回响应的集合
return responses;
}
在handleCompletedSends方法会将broker发送回来的网络响应封装成客户端响应
//NetworkClient.java
private void handleCompletedSends(List<ClientResponse> responses, long now) {
//遍历每个发送请求
for (Send send : this.selector.completedSends()) {
ClientRequest request = this.inFlightRequests.lastSent(send.destination());
if (!request.expectResponse()) {
this.inFlightRequests.completeLastSent(send.destination());
//将网络响应封装成客户端响应
responses.add(new ClientResponse(request, now, false, null));
}
}
}
当响应放入completedReceives列表之后,就会通过handleCompletedReceives方法将该响应的请求从inFlightRequests移除出去
//NetworkClient.java
private void handleCompletedReceives(List<ClientResponse> responses, long now) {
for (NetworkReceive receive : this.selector.completedReceives()) {
//获取主机的id
String source = receive.source();
//从inFlightRequests集合中移除已经接收到响应的请求
ClientRequest req = inFlightRequests.completeNext(source);
//解析服务端发送回来的响应数据
Struct body = parseResponse(receive.payload(), req.request().header());
//若是元数据信息的响应信息
if (!metadataUpdater.maybeHandleCompletedReceive(req, now, body))
//将解析的相应内容封装成客户端响应
responses.add(new ClientResponse(req, now, false, body));
}
}
broker发送回来的每个响应包含元数据以及异常信息,broker通过生产者的回调函数callback.onCompletion()返回给生产者进行处理
//Sender.java
private void handleProduceResponse(ClientResponse response, Map<TopicPartition, RecordBatch> batches, long now) {
int correlationId = response.request().request().header().correlationId();
//若生产者与broker失去网络连接
if (response.wasDisconnected()) {
//对失去网络连接的消息批次进行处理
for (RecordBatch batch : batches.values())
completeBatch(batch, Errors.NETWORK_EXCEPTION, -1L, Record.NO_TIMESTAMP, correlationId, now);
} else {
//网络保持正常连接的情况下
//ack设置为-1和1的场景,需要服务端返回响应
if (response.hasResponse()) {
ProduceResponse produceResponse = new ProduceResponse(response.responseBody());
// 遍历每个分区对应的响应
for (Map.Entry<TopicPartition, ProduceResponse.PartitionResponse> entry : produceResponse.responses().entrySet()) {
//获取分区
TopicPartition tp = entry.getKey();
ProduceResponse.PartitionResponse partResp = entry.getValue();
//存储服务端发送回来的异常码
Errors error = Errors.forCode(partResp.errorCode);
//获取到当前分区对应的响应
RecordBatch batch = batches.get(tp);
//对该响应进行处理
completeBatch(batch, error, partResp.baseOffset, partResp.timestamp, correlationId, now);
}
} else {
//ack=0时,走这个分支,不需要服务端返回响应信息
for (RecordBatch batch : batches.values())
completeBatch(batch, Errors.NONE, -1L, Record.NO_TIMESTAMP, correlationId, now);
}
}
}
//Sender.java
private void completeBatch(RecordBatch batch, Errors error, long baseOffset, long timestamp, long correlationId, long now) {
//如果响应带有异常信息且这个请求是可以重试的
if (error != Errors.NONE && canRetry(batch, error)) {
//将发送失败的这个批次重新添加到队列首部,等待下一次发送
this.accumulator.reenqueue(batch, now);
} else {
//走这个分支,有两种情况,(1)没有异常
//(2)有异常,但是不满足重试的条件(1:重试次数满了 2:不让重试)
RuntimeException exception;
//若响应里面含有主题没有权限的异常
if (error == Errors.TOPIC_AUTHORIZATION_FAILED)
//添加没有权限的异常信息
exception = new TopicAuthorizationException(batch.topicPartition.topic());
else
exception = error.exception();
//把异常等信息通过客户端的回调函数返回回去
batch.done(baseOffset, timestamp, exception);
//将消息批次对象占用的内存释放回内存池
this.accumulator.deallocate(batch);
}
}
done方法将元数据和异常信息通过生产者的回调函数返回给客户端,进而客户端就可以捕获异常信息进行对应的处理了。
public void done(long baseOffset, long timestamp, RuntimeException exception) {
//遍历生产者发送出去的每条消息,每个thunk代表一条消息
//执行每条消息的回调函数
for (int i = 0; i < this.thunks.size(); i++) {
try {
Thunk thunk = this.thunks.get(i);
//如果没有异常
if (exception == null) {
//创建元数据对象
RecordMetadata metadata = new RecordMetadata(this.topicPartition, baseOffset, thunk.future.relativeOffset(),
timestamp == Record.NO_TIMESTAMP ? thunk.future.timestamp() : timestamp,
thunk.future.checksum(),
thunk.future.serializedKeySize(),
thunk.future.serializedValueSize());
//执行生产者的回调函数,异常为null
thunk.callback.onCompletion(metadata, null);
//存在异常的情况
} else {
//执行回调函数,将异常信息返回给客户端,等待客户端捕获异常处理
thunk.callback.onCompletion(null, exception);
}
} catch (Exception e) {
log.error("Error executing user-provided callback on message for topic-partition {}:", topicPartition, e);
}
}
this.produceFuture.done(topicPartition, baseOffset, exception);
}
最终生产者这边通过回调函数,捕获异常信息进行对应的处理
class DemoCallBack implements Callback {
public void onCompletion(RecordMetadata metadata, Exception exception) {
//记录已经花费了多少时间
long elapsedTime = System.currentTimeMillis() - startTime;
//出现异常
if(exception != null){
System.out.println("出现异常");
}else{
System.out.println("没有出现异常");
}
if (metadata != null) {
System.out.println(
"message(" + key + ", " + message + ") sent to partition(" + metadata.partition() +
"), " +
"offset(" + metadata.offset() + ") in " + elapsedTime + " ms");
} else {
exception.printStackTrace();
}
}
}
处理异常的消息批次
通过上面completeBatch()源码的分析我们可以知道,当消息出现异常时分为两种情况,
- 若异常消息满足重试的条件,则将消息批次重新放入队列首部,等待下一次发送
- 若异常消息不可以重试,则将异常信息通过回调函数返回给客户端,再将该消息批次对象占用的内存释放回内存池
处理超时的消息批次
sender线程启动后,run方法就会一直运行,不断的遍历每个分区对应的队列,判断队列中的每个消息批次是否超时,以下是对超时批次的源码剖析。
//Sender.java
void run(long now) {
//处理超时的消息批次
List<RecordBatch> expiredBatches = this.accumulator.abortExpiredBatches(this.requestTimeout, now);
}
//RecordAccumulator.java
public List<RecordBatch> abortExpiredBatches(int requestTimeout, long now) {
//存放超时的消息批次
List<RecordBatch> expiredBatches = new ArrayList<>();
int count = 0;
//遍历每个分区对应的队列
for (Map.Entry<TopicPartition, Deque<RecordBatch>> entry : this.batches.entrySet()) {
//获取每个分区对应的队列
Deque<RecordBatch> dq = entry.getValue();
//获取主题分区
TopicPartition tp = entry.getKey();
if (!muted.contains(tp)) {
//加锁
synchronized (dq) {
RecordBatch lastBatch = dq.peekLast();
//遍历分区的每个消息批次
Iterator<RecordBatch> batchIterator = dq.iterator();
while (batchIterator.hasNext()) {
RecordBatch batch = batchIterator.next();
boolean isFull = batch != lastBatch || batch.records.isFull();
//判断批次是否超时
if (batch.maybeExpire(requestTimeout, retryBackoffMs, now, this.lingerMs, isFull)) {
//添加到超时的列表里
expiredBatches.add(batch);
count++;
//从队列中移除该消息批次
batchIterator.remove();
//将批次的内存释放到内存池中
deallocate(batch);
} else {
//批次没超时
break;
}
}
}
}
}
if (!expiredBatches.isEmpty())
log.trace("Expired {} batches in accumulator", count);
return expiredBatches;
}
maybeExpire方法用于判断消息批次是否满足超时的条件,以下是该方法的源码
//RecordBatch.java
public boolean maybeExpire(int requestTimeoutMs, long retryBackoffMs, long now, long lingerMs, boolean isFull) {
boolean expire = false;
String errorMessage = null;
/**
* requestTimeoutMs:表示请求等待服务器响应的最长时间,默认30s
* now:当前时间
* lastAppendTime:消息批次添加到队列的时间
* now - this.lastAppendTime 当前时间减去上次添加的时间大于30秒,说明消息批次已经超时
*/
if (!this.inRetry() && isFull && requestTimeoutMs < (now - this.lastAppendTime)) {
expire = true;
//记录异常信息
errorMessage = (now - this.lastAppendTime) + " ms has passed since last append";
//若批次的创建时间+设置的超时时间 > 请求等待服务器响应的最长时间
} else if (!this.inRetry() && requestTimeoutMs < (now - (this.createdMs + lingerMs))) {
expire = true;
errorMessage = (now - (this.createdMs + lingerMs)) + " ms has passed since batch creation plus linger time";
//若当前时间-(上次重试的时间+重试时间间隔) > 请求等待服务器响应的最长时间,说明超时了
} else if (this.inRetry() && requestTimeoutMs < (now - (this.lastAttemptMs + retryBackoffMs))) {
expire = true;
errorMessage = (now - (this.lastAttemptMs + retryBackoffMs)) + " ms has passed since last attempt plus backoff time";
}
//该批次已经超时
if (expire) {
this.records.close();
//处理超时的批次,传入超时的异常信息
this.done(-1L, Record.NO_TIMESTAMP,
new TimeoutException("Expiring " + recordCount + " record(s) for " + topicPartition + " due to " + errorMessage));
}
//返回批次是否超时
return expire;
}
总结上面两个方法对于超时的消息批次,首先将该消息批次对象移除队列,添加到超时的列表中,然后释放消息批次对象占用的内存,最后将超时的异常信息通过生产者的回调函数返回给客户端。
处理长时间未得到响应的消息批次
run()方法里面的poll()方法会不断的判断是否有长时间未得到响应的消息批次,若有就会进行对应的处理
//NetworkClient.java
public List<ClientResponse> poll(long timeout, long now) {
//处理长时间没有接收到响应的消息批次
handleTimedOutRequests(responses, updatedNow);
}
private void handleTimedOutRequests(List<ClientResponse> responses, long now) {
//获取请求超时的主机
List<String> nodeIds = this.inFlightRequests.getNodesWithTimedOutRequests(now, this.requestTimeoutMs);
for (String nodeId : nodeIds) {
//关闭请求超时的主机对应的网络连接
this.selector.close(nodeId);
log.debug("Disconnecting from node {} due to request timeout.", nodeId);
//修改连接的状态为失去连接
processDisconnection(responses, nodeId, now);
}
if (nodeIds.size() > 0)
metadataUpdater.requestUpdate();
}
private void processDisconnection(List<ClientResponse> responses, String nodeId, long now) {
//修改网络连接的状态为DISCONNECTED
connectionStates.disconnected(nodeId, now);
//清除inFlightRequests集合中超时的请求
for (ClientRequest request : this.inFlightRequests.clearAll(nodeId)) {
if (!metadataUpdater.maybeHandleDisconnection(request))
//封装响应(响应的内容为null,失去连接的标志为true)
responses.add(new ClientResponse(request, now, true, null));
}
}
对于长时间未处理的响应,首先找出请求超时的主机,然后关闭生产者与超时主机的网络连接,再修改网络连接的状态为失去连接,最后自定义创建一个响应,该响应的内容为null,失去连接的状态标志为true。
粘包拆包问题
- 粘包:指的是多条消息被合并成一个数据包发送,导致消费者接收到的数据包中包含了多条消息。这种情况下,消费者需要正确地解析出多条消息,否则会导致数据解析错误。
- 拆包:指的是一条消息被拆分成多个数据包发送,导致消费者接收到的数据包中只包含了一条消息的部分内容。这种情况下,消费者需要能够正确地将多个数据包组合成一个完整的消息,否则会导致数据丢失。
原因:Kafka的粘包和拆包问题主要是由于TCP协议的特性导致的。TCP协议是一种基于字节流传输数据的,它并不保证数据包的边界,因此可能会出现粘包和拆包的情况。
解决方法
- 使用固定长度的消息头:生产者在发送消息时可以在消息头部添加一个固定长度的字段,用于表示消息的长度,消费者在接收到消息时,根据消息头中的长度字段来判断消息的边界,从而避免粘包和拆包。
- 使用分隔符:生产者在发送消息时可以在消息与消息之间添加一个特殊的分隔符,消费者在接收到消息时,可以根据分隔符来判断消息的边界,从而避免粘包和拆包的问题。但是这种方法所使用的分隔符不能出现在消息本身中,否则会导致边界的判断失误。
- 使用自定义协议:可以自定义一个协议,用于在发送和接收消息时标识消息的边界。这个协议可以包含消息长度、消息类型等信息,以便消费者能够正确地解析消息。
在Kafka中,生产者与broker的每个网络连接通过inFlightRequests集合默认最多可以缓存5个已经发送出去但是还没有收到响应的请求个数,这说明broker可能一次性往生产者发送多个响应,这就可能出现粘包问题;而生产者可能读取到服务端发送过来的多个响应,在这过程中可能出现拆包的问题。
而Kafka是使用固定长度的消息头来解决粘包和拆包问题,生产者发送消息到服务端时,会在消息头部添加一个4字节的size字段,用于表示消息的长度,当消费者收到消息后,会先读取这个size字段,然后根据size的值来读取完整的消息,从而避免粘包和拆包问题。
//Selector.java
private void pollSelectionKeys(Iterable<SelectionKey> selectionKeys,
boolean isImmediatelyConnected,
long currentTimeNanos) {
//若有读取数据的事件
if (channel.ready() && key.isReadable() && !hasStagedReceive(channel)) {
NetworkReceive networkReceive;
//不断的读取数据
while ((networkReceive = channel.read()) != null)
//将响应放入stagedReceives集合中
addToStagedReceives(channel, networkReceive);
}
}
//KafkaChannel.java
public NetworkReceive read() throws IOException {
NetworkReceive result = null;
//不断的读取数据
receive(receive);
//判断是否读取到一个完整响应消息
if (receive.complete()) {
receive.payload().rewind();
//记录读取结果
result = receive;
receive = null;
}
//返回读取结果
return result;
}
private long receive(NetworkReceive receive) throws IOException {
return receive.readFrom(transportLayer);
}
public long readFrom(ScatteringByteChannel channel) throws IOException {
return readFromReadableChannel(channel);
}
public long readFromReadableChannel(ReadableByteChannel channel) throws IOException {
int read = 0;
//如果4字节的size字段还有剩余内存
if (size.hasRemaining()) {
//先读取4字节的size表示的数值,该数值代表消息的总长度
int bytesRead = channel.read(size);
if (bytesRead < 0)
throw new EOFException();
read += bytesRead;
//当size没有剩余空间时,说明已经读取到4字节所代表的数值
if (!size.hasRemaining()) {
size.rewind();
//读取size所代表的int型数值
int receiveSize = size.getInt();
if (receiveSize < 0)
throw new InvalidReceiveException("Invalid receive (size = " + receiveSize + ")");
if (maxSize != UNLIMITED && receiveSize > maxSize)
throw new InvalidReceiveException("Invalid receive (size = " + receiveSize + " larger than " + maxSize + ")");
//receiveSize是size所代表的int数值,根据该大小分配内存空间
this.buffer = ByteBuffer.allocate(receiveSize);
}
}
if (buffer != null) {
//读取数据到buffer中
int bytesRead = channel.read(buffer);
if (bytesRead < 0)
throw new EOFException();
read += bytesRead;
}
return read;
}
complete()方法判断是否读取到完整的一条消息,用于拆包问题
public boolean complete() {
//size字段没有剩余空间且buffer申请的内存已经用完了
return !size.hasRemaining() && !buffer.hasRemaining();
}
总结
本文主要从源码角度讲解了消息的发送条件,生产者对broker发送回来的响应处理,生产者对于超时/异常/长时间未处理的消息批次是怎么处理的,以及kafka对于粘包拆包问题的解决方法。下章将从源码角度分析服务端的整体架构。