【算法】动态规划
文章目录
- 一、动态规划概念
- 二、算法思想
- 三、算法步骤
- 四、应用场景
- 五、动态规划优缺点
一、动态规划概念
动态规划(Dynamic Programming,简称DP)是一种广泛应用于数学、计算机科学和经济学等领域的方法论。其核心思想是通过将复杂问题分解为相对简单的子问题,并存储子问题的解以避免冗余计算,从而显著提高计算效率。
动态规划作为运筹学的一个分支,专注于解决决策过程的最优化问题。20世纪50年代初,美国数学家贝尔曼(R. Bellman)等人在研究多阶段决策过程的优化问题时,提出了著名的最优化原理,并基于此创立了动态规划。动态规划的应用范围极为广泛,包括工程技术、经济、工业生产、军事以及自动化控制等多个领域。在背包问题、生产经营问题、资金管理问题、资源分配问题、最短路径问题和复杂系统可靠性问题等实际问题中,动态规划均展现出了显著的效果。
二、算法思想
动态规划常常适用于具有重叠子问题和最优子结构性质的问题。其基本思想是将待求解的问题分解为若干个相关联的子问题,先求解子问题,然后利用这些子问题的解来构造原问题的解。
对于重复出现的子问题,只在第一次遇到的时候对他进行求解,并把答案保存起来,让以后再次遇到时直接引用答案,不必重新求解。
通俗来讲,动态规划算法是解决一类具有重叠子问题和最优子结构性质的问题的有效方法。其基本原理是将大问题分解为小问题,通过保存中间结果来避免重复计算,从而提高算法的效率。动态规划方法所耗时往往远少于朴素解法。
动态规划的基本过程包括定义子问题,解决子问题,合并子问题的解来求解原问题。动态规划通常采用自底向上的方式进行,通过迭代计算子问题并存储子问题的解,逐步求解更大规模的问题,直到求解出原问题。
动态规划主要包括两个要素:最优子结构和重叠子问题。
三、算法步骤
动态规划算法的基本步骤通常包括:划分阶段、定义状态、建立状态转移方程以及确定边界条件等。
划分阶段:按照时间或空间特征,将问题划分为若干个阶段,每个阶段对应一个决策过程。这些阶段需要满足无后效性,即某个阶段的状态一旦确定,则此后过程的演变不再受此前各种状态及决策的影响。这是动态规划方法应用的前提,也是保证算法有效性的基础。
定义状态:对每个阶段定义状态变量,状态变量应该能够表示出该阶段所有可能的信息,且能从中推导出下一阶段的状态。在定义状态时,要考虑到问题的具体特征,使得状态变量能够简洁明了地反映问题的本质。
状态转移方程:根据问题的性质,建立从一个阶段到下一个阶段的递推关系式,即状态转移方程。状态转移方程是动态规划算法的核心部分,它描述了问题在不同阶段之间的转移关系。在建立状态转移方程时,需要仔细分析问题的特征,找到正确的状态转移方式。同时,要注意避免重复计算,提高算法的效率。
边界条件:确定状态转移方程中的起始状态,即问题的初始条件。边界条件是动态规划算法的重要组成部分,它决定了算法的起点和范围。在确定边界条件时,要根据问题的具体要求进行设定,确保算法的正确性和有效性。
求解最优解:利用状态转移方程和边界条件,从初始状态开始逐步求解问题,最终得到问题的最优解。在求解过程中,要注意保存中间结果,以便后续使用。同时,要注意算法的时间复杂度和空间复杂度,确保算法在实际应用中的可行性。
优化与改进:在得到基本解决方案后,可以对算法进行优化和改进。例如,可以采用更高效的数据结构来存储中间结果,或者采用更合理的状态转移方式来减少计算量。此外,还可以结合其他算法和技术来进一步提高算法的性能和适用范围。
算法实现与测试:将优化后的算法用具体的编程语言实现,并进行测试以验证其正确性和有效性。在实现过程中,要注意代码的可读性和可维护性,以便后续修改和扩展。同时,要进行充分的测试以确保算法在各种情况下的正确性。
四、应用场景
动态规划是求多阶段决策过程最优化的一种数学方法,它将问题的整体按时间或空间的特征分成若干个前后衔接的时空阶段,把多个阶段决策问题表示为前后有关的一系列单阶段决策问题,然后逐个求解,从而求出整个问题的最有决策序列。以下是动态规划的十大经典问题:
1.最长公共子序列
2.背包问题
3.矩阵链路乘法
4.编辑距离
5.硬币找零问题
6.最大子段和
7.最长递增子序列
8.0-1背包问题
9.划分问题
10.合并排序问题
这些问题都具有一定的难度和代表性,可以帮助我们更好地理解和掌握动态规划的算法思想。下面已最长公共子序列为例详解
最长公共子序列:
基本概念:
DP算法解决的一个典型问题:最长公共子序列(Longest Common Subsequence,简称LCS)。LCS问题是一种经典的算法问题,在许多应用领域都有广泛的应用。它的基本思想是寻找两个字符串中都存在的最长子序列,这个最长子序列可以不是连续的,但是要保证其相对顺序一样。(注意,这里是子序列,而不是子串,子序列可以不连续,而子串是连续的)。
最长公共子序列是指两个序列中最长的子序列,且两个子序列在原序列中的顺序都是一致的,但不一定连续。最长公共子序列就是在两个序列中,找出能够匹配的最长子序列。具有如下特征:
长度:最长公共子序列的长度最大为两个序列的最小长度,如果两个序列完全相同,则它们的最长公共子序列即为它们本身。
顺序:最长公共子序列中的子序列在原序列中的顺序一致。
相同元素:最长公共子序列中的子序列所包含的元素必须在两个原序列中都存在。
不连续性:最长公共子序列不需要在原序列中连续出现。
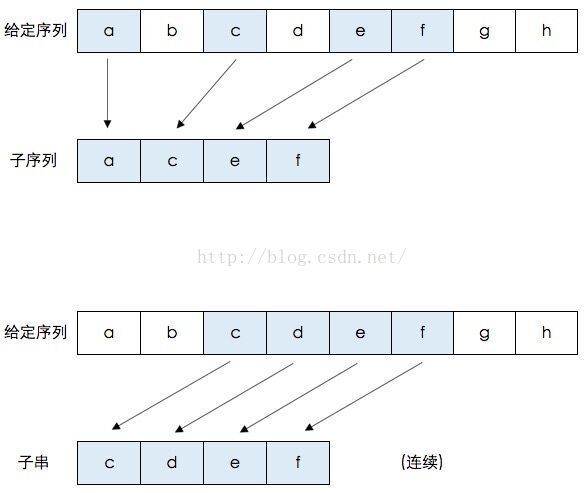
如上图,给定的字符序列: {a,b,c,d,e,f,g,h},它的子序列示例: {a,c,e,f} 即元素b,d,g,h被去掉后,保持原有的元素序列所得到的结果就是子序列。同理,{a,h},{c,d,e}等都是它的子序列。
它的字串示例:{c,d,e,f} 即连续元素c,d,e,f组成的串是给定序列的字串。同理,{a,b,c,d},{g,h}等都是它的字串。
这个问题说明白后,最长公共子序列(以下都简称LCS)就很好理解了。
给定序列s1={1,3,4,5,6,7,7,8},s2={3,5,7,4,8,6,7,8,2},s1和s2的相同子序列,且该子序列的长度最长,即是LCS。s1和s2的其中一个最长公共子序列是 {3,4,6,7,8}。
动态规划:
求解LCS问题,不能使用暴力搜索方法。一个长度为n的序列拥有 2的n次方个子序列,它的时间复杂度是指数阶,太恐怖了。解决LCS问题,需要借助动态规划的思想。
动态规划算法通常用于求解具有某种最优性质的问题。在这类问题中,可能会有许多可行解。每一个解都对应于一个值,我们希望找到具有最优值的解。动态规划算法与分治法类似,其基本思想也是将待求解问题分解成若干个子问题,先求解子问题,然后从这些子问题的解得到原问题的解。与分治法不同的是,适合于用动态规划求解的问题,经分解得到子问题往往不是互相独立的。若用分治法来解这类问题,则分解得到的子问题数目太多,有些子问题被重复计算了很多次。如果我们能够保存已解决的子问题的答案,而在需要时再找出已求得的答案,这样就可以避免大量的重复计算,节省时间。我们可以用一个表来记录所有已解的子问题的答案。不管该子问题以后是否被用到,只要它被计算过,就将其结果填入表中。这就是动态规划法的基本思路。
特征分析:
设A=“a0,a1,…,am”,B=“b0,b1,…,bn”,且Z=“z0,z1,…,zk”为它们的最长公共子序列。不难证明有以下性质:
如果am=bn,则zk=am=bn,且“z0,z1,…,z(k-1)”是“a0,a1,…,a(m-1)”和“b0,b1,…,b(n-1)”的一个最长公共子序列;
如果am!=bn,则若zk!=am,蕴涵“z0,z1,…,zk”是“a0,a1,…,a(m-1)”和“b0,b1,…,bn”的一个最长公共子序列;
如果am!=bn,则若zk!=bn,蕴涵“z0,z1,…,zk”是“a0,a1,…,am”和“b0,b1,…,b(n-1)”的一个最长公共子序列。
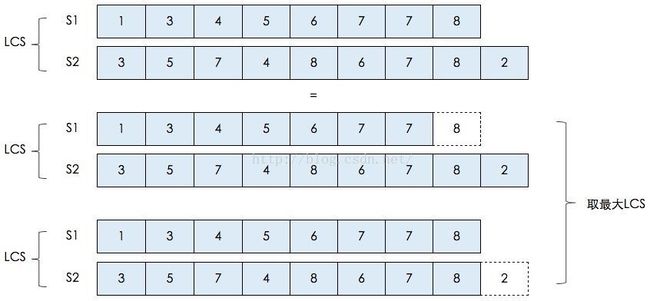
以之前举的例子(S1={1,3,4,5,6,7,7,8}和S2={3,5,7,4,8,6,7,8,2}),并结合上图来说:
假如S1的最后一个元素 与 S2的最后一个元素相等,那么S1和S2的LCS就等于 {S1减去最后一个元素} 与 {S2减去最后一个元素} 的 LCS 再加上 S1和S2相等的最后一个元素。
假如S1的最后一个元素 与 S2的最后一个元素不等(本例子就是属于这种情况),那么S1和S2的LCS就等于 : {S1减去最后一个元素} 与 S2 的LCS, {S2减去最后一个元素} 与 S1 的LCS 中的最大的那个序列。
递归公式:
根据LCS的特征,我们可以发现,假设我需要求 a1 … am 和 b1 … b(n-1)的LCS 和 a1 … a(m-1) 和 b1 … bn的LCS,一定会递归地并且重复地把如a1… a(m-1) 与 b1 … b(n-1) 的 LCS 计算几次。所以我们需要一个数据结构来记录中间结果,避免重复计算。
假设我们用c[i,j]表示Xi 和 Yj 的LCS的长度(直接保存最长公共子序列的中间结果不现实,需要先借助LCS的长度)。其中X = {x1 … xm},Y ={y1…yn},Xi = {x1 … xi},Yj={y1… yj}。可得递归公式如下:
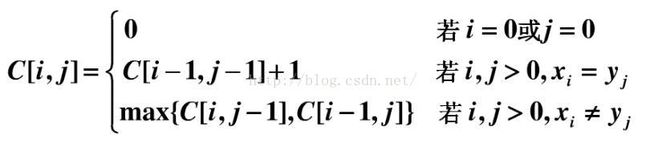
计算LSC的长度:
以表格的形式表示整个过程如下:(这里以 以s1={1,3,4,5,6,7,7,8},s2={3,5,7,4,8,6,7,8,2}为例)
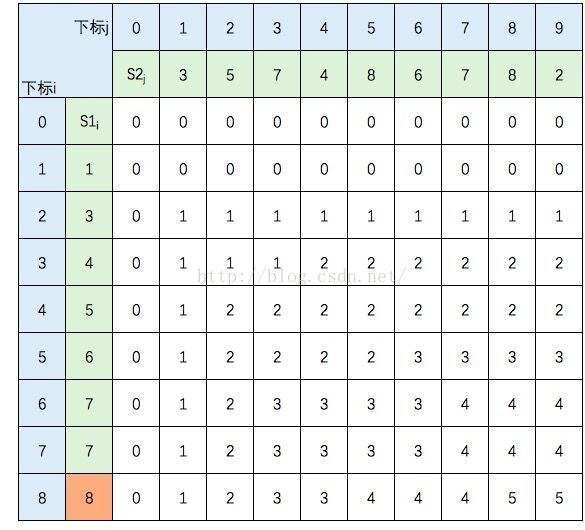
填表的过程就相当于解题的过程(第0行、第0列初始值都为0),我们以第0行为参照,先从左到右填满第1行;再以第1行为参照,从左到右填满第2行;以此类推,当表格填完后,答案就出来了(即为L[n][n])。根据性质,c[8,9] = S1 和 S2 的 LCS的长度,即为5。
代码如下:
int dp[1010][1010];
int LCS(char* s1, char* s2, int l1, int l2) {
memset(dp, 0, sizeof(dp));
for (int i = 1; i <= l1; i++) {
for (int j = 1; j <= l2; j++) {
if (s1[i] == s2[j]) {
dp[i][j] = dp[i - 1][j - 1] + 1;
}
else {
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
return dp[l1][l2];
}
五、动态规划优缺点
优点
- 对于具有重叠子问题和最优子结构性质的问题,动态规划可以显著提高求解效率,避免不必要的重复计算。通过存储和复用子问题的解,动态规划算法能够避免重复计算相同的子问题,从而大大减少计算量。
- 动态规划算法的代码通常比较简洁,易于理解和实现。一旦确定了问题的状态转移方程和边界条件,动态规划算法的代码实现往往非常直观和简洁。
缺点
- 对于没有重叠子问题和最优子结构性质的问题,动态规划算法可能并不适用,此时需要考虑其他算法。动态规划算法的有效性建立在问题的重叠子问题和最优子结构性质上,如果问题不具备这些性质,那么动态规划算法就无法发挥其优势。
- 动态规划算法的空间复杂度通常较高,需要存储所有子问题的解,以便后续使用。这可能导致算法在处理大规模问题时需要消耗大量的内存空间。在某些情况下,可能需要考虑使用滚动数组或其他优化技巧来降低空间复杂度。滚动数组是一种常用的优化方法,它只保留当前需要使用的子问题解,从而避免了存储所有子问题的解。