【Python机器学习】NLP词频背后的含义——隐性语义分析
隐性语义分析基于最古老和最常用的降维技术——奇异值分解(SVD)。SVD将一个矩阵分解成3个方阵,其中一个是对角矩阵。
SVD的一个应用是求逆矩阵。一个矩阵可以分解成3个最简单的方阵,然后对这些方阵求转置后再把它们相乘,就得到了原始矩阵的逆矩阵。它为我们提供了一个对大型复杂矩阵求逆的捷径。SVD适用于桁架结构的应力和应变分析等机械工程问题,它对电气工程中的电路分析也很有用,它甚至在数据科学中被用于基于行为的推荐引擎,其与基于内容的NLP推荐引擎一起运行。
利用SVD,LSA可以将TF-IDF词项-文档矩阵分解为3个更简单的矩阵。这3个矩阵可以相乘得到原始矩阵,得到的原始矩阵不会有任何改变。但是,经过SVD后得到的这3个更简单的矩阵揭示了原始TF-IDF矩阵的一些性质,我们可以利用这些性质来简化原始矩阵。我们可以在将这些矩阵相乘之前对它们进行截断处理(忽略一些行和列),这将减少在向量空间模型中需要处理的维数。
这些截断的矩阵相乘并不能得到和原始TF-IDF矩阵完全一样的矩阵,然而它们却给出了一个更好的矩阵,文档的新表示包含了这些文档的本质,即隐性语义。这就是SVD被用于其他领域(如压缩)的原因。它能捕捉数据集的本质,并且忽略噪声。JPEG图像大小是原始位图的十分之一,但仍然包含原始图像的所有信息。
当在自然语言处理中一这种方式使用SVD时,我们将其称为隐性语义分析(LSA)。LSA揭示了被隐藏并等待被发现的词的语义或意义。
隐性语义分析是一种数学上的技术,用于寻找任意一组NLP向量进行最佳线性变换(旋转和拉伸)的方法,这些NLP向量包括TF-IDF向量或词袋向量。对很多应用来说,最好的变换方法是将坐标轴(维度)对齐到新向量中,使其在词频上具有最大的散度或方差。然后,我们可以在新的向量空间中去掉那些对不同文档向量的方差贡献不大的维度。
这种使用SVD的方法称为截断的奇异值分解(截断的SVD)。在图像处理和图像压缩领域,叫做主成分分析(PCA)。自然语言文档上的LSA等价于TF-IDF向量上的PCA。
LSA使用SVD查找导致数据中方差最大的词的组合,我们可以旋转TF-IDF向量,使旋转后的向量的新维度(基向量)与这些最大方差方向保持一致。“基向量”是新向量空间的坐标轴,与3个六维主题向量类似。每个维度(轴)都变成了词频的组合,而不是单个词频,因此我们可以把这些维度看作是构成语料库中各个“主题”的词的加权组合。
机器不能理解词的组合所表达的含义,只能理解这些词是在一起的。当它看到像“dog”、“cat”这样的词总是一起出现时,就会把它们放到一个主题中。它并不知道这样的主题可能是关于“pets”的。这个主题可能包含很多词,包括“domesticated”这种意义完全相反的词。如果它们经常一起出现在同一篇文档中,那么LSA会给它们赋予相同主题下的高分。这取决于人们看哪些词在每个主题中有很高的权重,并给它们起名字。
但是,我们并不需要通过为主题起名字来使用它们,我们可以直接用这些主题向量进行数学运算,就像在TF-IDF向量上做的一样,还可以对这些主题向量进行加减运算并估算文档之间的相似度。这里是基于主题向量而不只是词频向量进行计算。
LSA还提供了另一条有用的信息。类似于TF-IDF的IDF部分,LSA告诉我们向量中的哪些维度对文档的语义(含义)很重要。于是,我们可以丢弃文档之间方差最小的维度(主题)。对任何机器学习算法来说,这些小方差的主题通常是干扰因素与噪声。如果每篇文档都有大致相同含量的某个主题,而该主题却不能帮我们区分这些文档,那么就可以删除这个主题。这样有助于泛化向量表示,因此当将LSA用于流水线上从没见过的新文档时,即使这篇文档来自完全不同的上下文,它也会工作的很好。
LSA降维的效果很好,这是因为它在某种意义上是最优的。它会保留尽可能多的信息。它不丢弃任何词,而只丢弃某些维度(主题)。
LSA将更多的意义压缩到更少的维度中。我们只需要保留高方差维度,即语料库以各种方式(高方差)讨论的主要主题。留下来的每个维度都称为“主题”,包含所有捕捉到的词的某种加权组合。
思想实验的实际实现
对于一个小规模的短文档语料库,只需要几个维度(主题)就可以捕捉这些文档的语义:
from nlpia.book.examples.ch04_catdog_lsa_3x6x16 import word_topic_vectors
print(word_topic_vectors.T.round(1))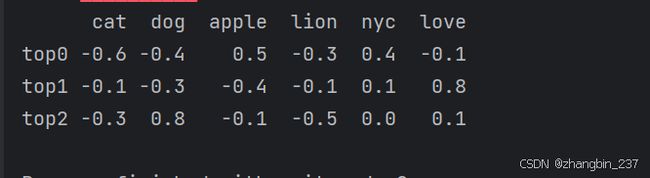
上述主题-词矩阵中的每列是词的主题向量或者每个词对应的主题向量。该向量中的每个元素就像情感分析模型中所使用的词得分。这些向量可以用来表示任何机器学习流水线中词的含义,它们有时也被成为词的语义向量。文档中的每个词的主题向量可以相加从而得到该文档的主题向量。
上述SVD创建的主题向量类似于从人想象中提取出的主题向量。这里的第一个主题标注为top0。top0向量中apple和NYC的权重更大,但是top0在这里的LSA主题排序中排名第一。LSA根据主题的重要度,即它们所代表数据集的信息量或方差大小,对主题进行排序。top0对应的维度方向和数据集中方差最大的轴保持一致。我们注意到关于城市主题的方差比较大,有些句子会使用UYC和apple,而另一些句子可能根本不会使用这些词。
LSA算法还发现,对于要捕捉这篇文档本质而言,“love”是比“animalness”更重要的主题。最后一个主题top2,似乎是关于“dog”的,也混合了一点“love”。“cat”这个词被归为城市反面主题,这是因为“cat”和“city”并不经常放在一起。
文字游戏
Awas!Awas!Tom is behind you!Run!
上面这个例子,Tom其实是一只猩猩,awas在印尼语中是当心/危险!
在上面这样的短文档且有生僻词上时,只把注意力集中在语言上下文及词本身,我们经常可以把所知道的很多词的意义或语义转移到不知道的词上。
机器从零开始,没有一种可以基于的语言。因此,它们需要的不仅仅是一个简单的例子,而是需要更多信息来理解词的意义。就像刚才的例子,机器使用LSA后可以很好的处理这一问题,即使面对的只是随机提取的、包含至少几个大家感兴趣的词的文档。
像上面这样较短的文档比像文章、书籍这样的大型文档上更适合上述过程,这是因为一个词的意思通常与包含它的句子中的词的意思紧密相关。但是,对于较长文档中相隔较远的词,情况就不一样了。
LSA是一种通过给机器一些样例来训练机器识别词和短语的意义(语义)的方法。和人类一样,机器从词的示例用法中学习语义要比从字典定义中学习更快也更容易。从示例用法中提取词的含义所需的逻辑推理,要比阅读字典中词的所有可能定义和形式然后将其编码到某个逻辑中所需的逻辑推理少。
在LSA中提取出词的含义的数学方法称为奇异值分解(SVD)。SVD来自线性代数,是LSA用来创建类似上面的词-主题矩阵中的向量的数学工具。