MySQL B+Tree索引概念
索引作用是为了提高数据检索效率,通过二分查找法快速定位数据范围,但是dml操作数据时,又需要对索引进行维护,索引查询虽好,维护性能堪忧.
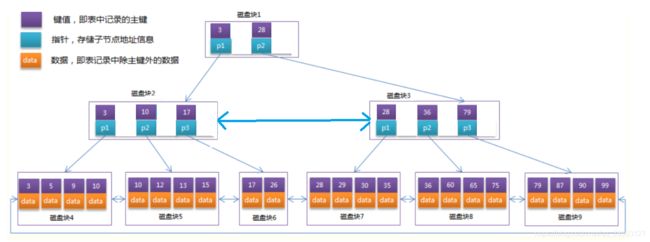
下图是B树索引与B+Tree索引存储原理图(本人画太慢了,扣的网图):
B-Tree索引:

B+Tree索引:(网上原图不是太准确,所以我调整了一下)
对上图的概念解释:
树节点的概念:
根节点:最顶层的节点,有且只有一个节点 (对应图中磁盘块1)
叶子节点:最底层的节点 (对应图中磁盘块4~9)
内节点:除根节点与叶子节点的节点都是内节点 (对应图中磁盘块2和3)
页:
页是mysql与磁盘交互的基本单位,默认大小16K,用户数据与索引数据是存放到页中的(这个说法对MyISAM不准确,后面会说),图中标记的磁盘块就是页,也就是有9个页,页4(磁盘块4)中存储了4条用户数据行,页6(磁盘块6)存储了2条用户数据行.每一层的页与页之间是双向的,注意是每一层的页(节点).叶子节点中的数据行并不一定按照图中的顺序存储的,比如磁盘块4中的存储的顺序可能是5 10 9 3只是内部通过一些属性形成链表,这样链表的顺序就是图中3->5->9->10的顺序.
B-Tree与B+Tree区别:
上面两张图中可以看出,B-Tree索引所有的节点中都存放了data,也就是我们插入表中的数据行,而B+Tree索引只有叶子节点才存放真实数据,非叶子节点存放的是索引数据(页指针与主键值).关于B-Tree其他的不说了,重点在于Mysql中使用的B+Tree.
图中树只有三层,实际有几层?
这个不一定,跟每行数据的大小以及总的数据量条目数有关系,通常情况下就是3层,但是数据量很小的时候有两层(没有内节点),数据量很大的时候会有超过3层(但是一般不会出现,有那么大数据量就会用大数据nosql数据库存储了),所有我们一般把B+Tree当成3层就可以了.
聚簇索引
上图中的B-Tree与B+Tree图是聚簇索引,聚簇索引与二级索引的区别在于聚簇索引的叶子节点存储的是真实数据,二级索引的叶子节点存储的是指向真实数据的指针.
B+Tree索引
因为要完全准确的描述索引需要大量篇幅讲底层从行到页的存储,而那一部分内容不影响我们理解mysql中的索引,所以感兴趣的话可以看我的另外两篇博文:
MySQL InnoDB引擎数据存储行格式
Mysql页的基本概念
以下篇幅不特别指出的话,就是以主键的聚簇索引展开说明的,二级索引会有特殊说明.
检索数据
每一层的节点,都是按照主键排好序的,根节点内的有序,内节点与根节点根据页链表所有的主键有序.
比如我们要根据图中主键检索15的数据,首先定位到根节点(这个跟节点地址是不会变动的,后面说),然后1<15<28,因为1跟28存储的分别是页2页3中的最小值,所以我们可以定位到15的数据在页2中,在页2中定位15在页5中,到页中查找到15的data.
上面的过程是我们可以理解成的过程,实际过程了解一下即可:首先页中(无论是什么节点)数据是分组的,每个组对应一个slot,slot里面存储的是编号与组内最大的主键值.下面画的是叶子节点,这个页中有1~20 二十条数据(页大小16k所以根据每一数据行的大小可以存储2到多条数据,最少存储2条是硬性规定),我们把1到20条数据分成五组(实际分组规则三言两语说不清楚,大部分组内是4-8条数据)

检索数据是通过slot进行二分查找法,图中五个slot,如果要检索主键15的数据,先通过二分查找法(二分查找法不知道的话就百度吧)5个slot先校验slot2中的主键,是12,比15小找右边,再根据二分查找法校验slot3中的主键值,为16比15大,slot中存储的最大的主键值,所以定位15在slot3中,然后遍历slot3中的数据获取到主键为15的数据即可.每个叶子节点中取最小的主键值,加上这个页的指针,就组成了内节点的一条数据,如果有20个叶子节点页,那么内节点页中就有20条数据,依次对根节点->内节点->叶子节点中的slot通过二分查找法,最终定位到叶子节点的真实数据.
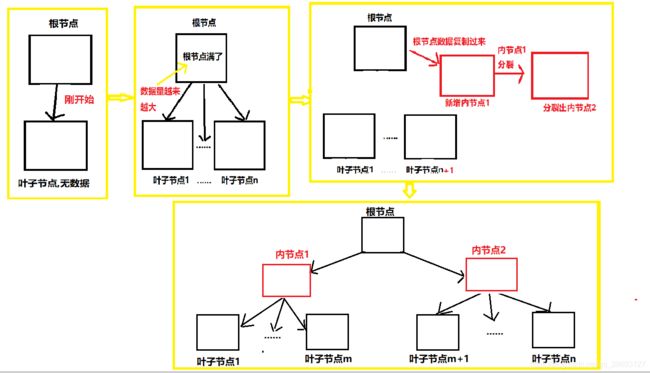
生成B+Tree索引
刚开始表中没有数据,就会创建聚簇索引根节点,根节点中也没有数据,随着数据的插入,根节点慢慢就会填充数据(主键值与页指针),随着数据量越来越大,这时根节点存放不下就需要页分裂,由一个页变成两个页,但是根节点地址是不变的,并且根节点只能有一个,所以首先根节点(页1)中的数据复制到新的页(页2)中,新的页再分裂出一个页(页3),这两个页就变成了内节点,原来的根节点就会删除原有的数据,分别存储页2与页3的的最小主键值与页2与页3的指针.如下图所示
聚簇索引与二级索引
对于InnoDB而言,表无论是否手动指定主键,都会维护一个主键,如果没有指定主键,那么会找唯一非null索引作为主键,如果连唯一非null索引都没有,那么InnoDB会自己维护一个主键row_id.主键是唯一非null的,所以可以进行完全排序.根据主键生成的索引是聚簇索引,其他索引都是二级索引(唯一索引,普通索引,复合索引),也叫辅助索引,辅助索引与聚簇索引相比,也是B+Tree树形结构,只是存储的数据不一样而已.
聚簇索引的叶子节点存储的是真实数据,二级索引叶子节点存储的是二级索引列值+主键值,聚簇索引非叶子节点存储的是主键值与页的指针,而二级索引非叶子节点存储的是二级索引列的值和页的指针以及主键值,因为二级索引可能会重复,索引重复时可以根据主键值进行排序,可能会有疑问,为什么二级索引的叶子节点不存储真实数据或者存储真实数据所在的页号呢,不存储真实数据是空间考虑,有多少个索引就要维护多少份真实数据,显然空间浪费严重;不存储真实数据页号是因为数据的页号可能会变(页分裂或者页合并),变了就要额外地去维护二级索引.
MyISAM无论是主键还是二级索引都是二级索引,他们的叶子节点存储的都是指向数据的行号,因为MyISAM的真实数据是按照插入顺序写入到一个文件中的,叶子节点存储的行号就是指向真实数据所在行的指针,所以MyISAM的使用二级索引检索时速度要比InnoDB快(InnoDB的二级索引查询的是主键值,还要回表到主键索引中查找真实数据)