【C++11】lambda表达式
文章目录
- lambda表达式
-
- C++98中的一个例子
- lambda表达式语法
- lambada表达式的使用
- 捕获列表说明
- 函数对象与lambda表达式
lambda表达式
C++98中的一个例子
在C++98中,如果想要对一个数据集合中的元素进行排序,可以使用std::sort方法。举例如下:
#include如果待排序元素为自定义类型,需要用户定义排序时的比较规则:
#include随着C++语法的发展,人们开始觉得上面的写法太复杂了,每次为了实现一个algorithm算法,
都要重新去写一个类(仿函数),如果每次比较的逻辑不一样,还要去实现多个类,特别是相同类的命名,这些都给编程者带来了极大的不便。因此,在C++11语法中出现了Lambda表达式。
lambda表达式语法
lambda表达式书写格式:[capture-list] (parameters) mutable -> return-type { statement }
lambda表达式各部分说明:
[capture-list]:捕捉列表,该列表总是出现在lambda函数的开始位置,编译器根据[]来判断接下来的代码是否为lambda函数,捕捉列表能够捕捉上下文中的变量供lambda函数使用。(parameters):参数列表。与普通函数的参数列表一致,如果不需要参数传递,则可以连同()一起省略。mutable:mutable可以取消其常量性,变成易变性。使用该修饰符时,参数列表不可省略(即使参数为空),默认情况下,对于以值传递方式引入的外部变量,不允许在 Lambda 表达式内部修改它们的值(可以理解为这部分变量都是 const 常量)。而如果想修改它们,就必须使用 mutable 关键字。对于以值传递方式引入的外部变量,Lambda 表达式修改的是拷贝的那一份,并不会修改真正的外部变量。。->returntype:返回值类型。用追踪返回类型形式声明函数的返回值类型,没有返回值时此部分可省略。返回值类型明确情况下,也可以省略,由编译器对返回类型进行推导。{statement}:函数体。在该函数体内,除了可以使用其参数外,还可以使用所有捕获到的变量。
注意:
在lambda函数定义中,参数列表和返回值类型都是可省略的部分,而捕捉列表和函数体可以为空。因此C++11中最简单的lambda函数为[]{},不过该lambda函数不能做任何事情。
#include解释了一堆学术语言,多说无益,我们通过实操来理解。
lambada表达式的使用
例1:下面的代码用lambda表达式实现了加法运算:
//初识lambda表达式
#include例2:下面的代码用lambda表达式实现了简单的交换函数:
#include那么如何应用捕捉列表呢?捕捉列表的作用是能够捕捉上下文的变量供lambda表达式使用。这样实现可以吗?
#include解析:swap2用的是传值捕捉,它捕捉了上文的x和y变量,供swap2这个lambda对象使用,由于lambda函数总是一个const函数,变量具有常性,我们无法进行数据的交换,所以我们用上了mutable修饰,这样变量就有了易变性,可以实现交换,但是运行结果告诉我们这样写并没有成功实现交换,那是因为swap2是一个传值捕捉,就类似传值函数一样,出了函数作用域,形参就销毁了,所以实际并没有实现交换。
正确写法如下:需要利用传引用捕捉。
#include例3:自定义类型,解决我们一开始的仿函数问题。
#include捕获列表说明
捕捉列表描述了上下文中的数据可以被lambda使用,以及使用的方式传值还是传引用。
- [var]:表示值传递方式捕捉变量var——传值捕捉
- [=]:表示值传递方式捕获所有父作用域中的变量(包括this)——全部传值捕捉
- [&var]:表示引用传递捕捉变量var——传引用捕捉
- [&]:表示引用传递捕捉所有父作用域中的变量(包括this)——全部传引用捕捉
- [this]:表示值传递方式捕捉当前的this指针——传值捕捉this指针
注意:
-
父作用域指包含lambda函数的语句块
-
语法上捕捉列表可由多个捕捉项组成,并以逗号分割
比如:[=, &a, &b]:表示传引用捕捉变量a和b,传值捕捉其它所有变量;[&,a,this]:表示传值捕捉变量a和this指针,传引用捕捉其它变量。 -
捕捉列表不允许变量重复传递,否则就会导致编译错误。
比如:[=, a]:=等号已经传值捕捉了所有变量,再传值捕捉a会导致重复问题。 -
在块作用域以外的lambda函数捕捉列表必须为空。
-
在块作用域中的lambda函数仅能捕捉父作用域中的局部变量,捕捉任何非此作用域或者非局部变量都会导致编译报错。
-
lambda表达式之间不能相互赋值,即使看起来类型相同。那么有什么方法可以使lambda表达式相互赋值呢?方法如下:再拷贝构造一个lambda对象。
#include函数对象与lambda表达式
函数对象,又称为仿函数,即可以像函数一样使用的对象,lambda表达式的底层,其实就是编译器根据Lambda表达式的捕获列表、参数列表、返回类型以及函数体等信息,生成一个匿名类,通常包含一个或多个构造函数,用于初始化捕获的外部变量。构造函数的参数与捕获列表中的变量相对应,并重载了operator()成员函数,用于实现Lambda表达式的功能。当Lambda表达式被调用时,实际上是调用了这个匿名类的operator()成员函数。
#include从使用方式上来看,函数对象与lambda表达式完全一样。
函数对象将rate作为其成员变量,在定义对象时给出初始值即可,lambda表达式通过捕获列表可
以直接将该变量捕获到。
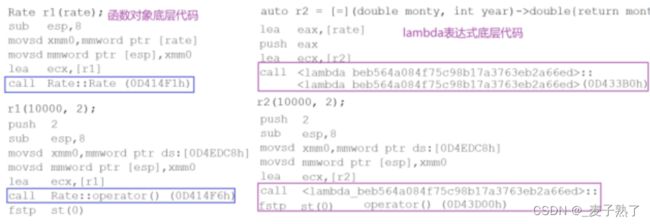
编译器在编译时,将Lambda表达式替换为创建匿名类实例的代码,并通过该实例调用operator()成员函数。这个匿名类实例通常是一个临时对象,只在Lambda表达式被调用的地方存在。