MySQL | 最左匹配原则
最左匹配原则
最左匹配原则就是指在联合索引中,如果你的 SQL 语句中用到了联合索引中的最左边的索引,那么这条 SQL 语句就可以利用这个联合索引去进行匹配。例如某表现有索引(a,b,c),现在你有如下语句:
select * from t where a=1 and b=1 and c =1; #这样可以利用到定义的索引(a,b,c),用上a,b,c
select * from t where a=1 and b=1; #这样可以利用到定义的索引(a,b,c),用上a,b
select * from t where b=1 and a=1; #这样可以利用到定义的索引(a,b,c),用上a,b(mysql有查询优化器)
select * from t where a=1; #这样也可以利用到定义的索引(a,b,c),用上a
select * from t where b=1 and c=1; #这样不可以利用到定义的索引(a,b,c)
select * from t where a=1 and c=1; #这样可以利用到定义的索引(a,b,c),但只用上a索引,b,c索引用不到也就是说通过最左匹配原则你可以定义一个联合索引,但是使得多中查询条件都可以用到该索引。
值得注意的是,当遇到范围查询(>、<、between、like)就会停止匹配。也就是:
select * from t where a=1 and b>1 and c =1; #这样a,b可以用到(a,b,c),c索引用不到
这条语句只有 a,b 会用到索引,c 都不能用到索引。这个原因可以从联合索引的结构来解释。
但是如果是建立(a,c,b)联合索引,则a,b,c都可以使用索引,因为优化器会自动改写为最优查询语句
select * from t where a=1 and b >1 and c=1; #如果是建立(a,c,b)联合索引,则a,b,c都可以使用索引
#优化器改写为
select * from t where a=1 and c=1 and b >1;这也是最左前缀原理的一部分,索引index1:(a,b,c),只会走a、a,b、a,b,c 三种类型的查询,其实这里说的有一点问题,a,c也走,但是只走a字段索引,不会走c字段。
另外还有一个特殊情况说明下,select * from table where a = '1' and b > ‘2’ and c='3' 这种类型的也只会有 a与b 走索引,c不会走。
像select * from table where a = '1' and b > ‘2’ and c='3' 这种类型的sql语句,在a、b走完索引后,c肯定是无序了,所以c就没法走索引,数据库会觉得还不如全表扫描c字段来的快。
以index (a,b,c)为例建立这样的索引相当于建立了索引a、ab、abc三个索引。一个索引顶三个索引当然是好事,毕竟每多一个索引,都会增加写操作的开销和磁盘空间的开销。
最左匹配原则的原理
最左匹配原则都是针对联合索引来说的,所以我们可以从联合索引的原理来了解最左匹配原则。
我们都知道索引的底层是一颗 B+ 树,那么联合索引当然还是一颗 B+ 树,只不过联合索引的健值数量不是一个,而是多个。构建一颗 B+ 树只能根据一个值来构建,因此数据库依据联合索引最左的字段来构建 B+ 树。
例子:假如创建一个(a,b,c)的联合索引,那么它的索引树是这样的:
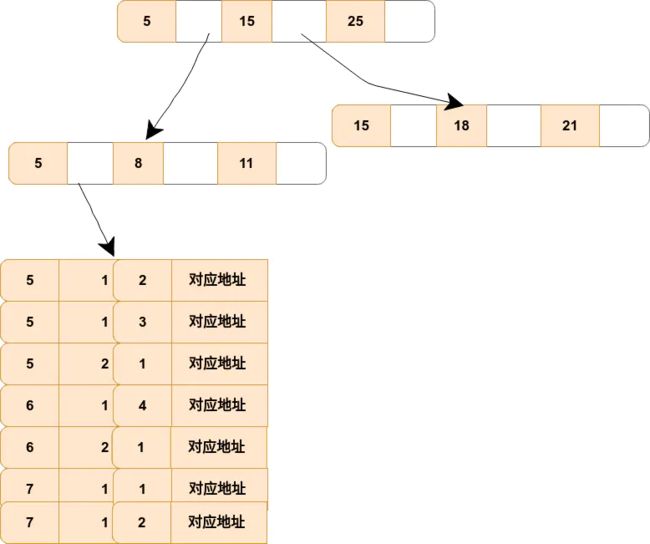
该图就是一个形如(a,b,c)联合索引的 b+ 树,其中的非叶子节点存储的是第一个关键字的索引 a,而叶子节点存储的是三个关键字的数据。这里可以看出 a 是有序的,而 b,c 都是无序的。但是当在 a 相同的时候,b 是有序的,b 相同的时候,c 又是有序的。
通过对联合索引的结构的了解,那么就可以很好的了解为什么最左匹配原则中如果遇到范围查询就会停止了。以 select * from t where a=5 and b>0 and c =1; #这样a,b可以用到(a,b,c),c不可以 为例子,当查询到 b 的值以后(这是一个范围值),c 是无序的。所以就不能根据联合索引来确定到低该取哪一行。
总结
- 在 InnoDB 中联合索引只有先确定了前一个(左侧的值)后,才能确定下一个值。如果有范围查询的话,那么联合索引中使用范围查询的字段后的索引在该条 SQL 中都不会起作用。
- 值得注意的是,
in和=都可以乱序,比如有索引(a,b,c),语句select * from t where c =1 and a=1 and b=1,这样的语句也可以用到最左匹配,因为 MySQL 中有一个优化器,他会分析 SQL 语句,将其优化成索引可以匹配的形式,即select * from t where a =1 and b=1 and c=1
为什么要使用联合索引
1、减少开销。建一个联合索引(col1,col2,col3),实际相当于建了(col1),(col1,col2),(col1,col2,col3)三个索引。每多一个索引,都会增加写操作的开销和磁盘空间的开销。对于大量数据的表,使用联合索引会大大的减少开销!
2、覆盖索引。对联合索引(col1,col2,col3),如果有如下的sql: select col1,col2,col3 from test where col1=1 and col2=2。那么MySQL可以直接通过遍历索引取得数据,而无需回表,这减少了很多的随机io操作。减少io操作,特别的随机io其实是dba主要的优化策略。所以,在真正的实际应用中,覆盖索引是主要的提升性能的优化手段之一。
3、效率高。索引列越多,通过索引筛选出的数据越少。有1000W条数据的表,有如下sql:select from table where col1=1 and col2=2 and col3=3,假设假设每个条件可以筛选出10%的数据,如果只有单值索引,那么通过该索引能筛选出1000W10%=100w条数据,然后再回表从100w条数据中找到符合col2=2 and col3= 3的数据,然后再排序,再分页;如果是联合索引,通过索引筛选出1000w10% 10% *10%=1w,效率提升可想而知!
使用索引优化查询问题:
1、创建单列索引还是多列索引?
如果查询语句中的where、order by、group 涉及多个字段,一般需要创建多列索引,比如:
select * from user where nick_name = 'ligoudan' and job = 'dog';
2、多列索引的顺序如何选择?
一般情况下,把选择性高德字段放在前面,比如:
查询sql:
select * from user where age = '20' and name = 'zh' order by nick_name;
这时候如果建索引的话,首字段应该是age,因为age定位到的数据更少,选择性更高。
但是务必注意一点,满足了某个查询场景就可能导致另外一个查询场景更慢。
3、避免使用范围查询
很多情况下,范围查询都可能导致无法使用索引。
4、尽量避免查询不需要的数据
explain select * from user where job like '%ligoudan%';
explain select job from user where job like '%ligoudan%';
同样的查询,不同的返回值,第二个就可以使用覆盖索引,第一个只能全表遍历了。
覆盖索引优化like
5、查询的数据类型要正确
explain select * from user where create_date >= now();
explain select * from user where create_date >= '2020-05-01 00:00:00';
第一条语句就可以使用create_date的索引,第二个就不可以。