MySQL gh-ost DDL 变更工具
文章目录
-
- 1. MDL 锁介绍
- 2. 变更工具
- 3. gh-ost 原理解析
- 4. 安装部署
- 5. 操作演示
-
- 5.1. 重点参数介绍
- 5.2. 执行变更
- 5.3. 动态控制
- 6. 风险提示
1. MDL 锁介绍
MySQL 的锁可以分为四类:MDL 锁、表锁、行锁、GAP 锁,其中除了 MDL 锁是在 Server 层加的之外,其它三种都是在 InnoDB 层加的。
下面主要介绍一下:MDL 元数据锁,主要作用就是维护 DDL 过程中数据的安全性 & 正确性。
当对一个表进行 DML 时,需要加 MDL 读锁,当需要对一张表结构进行变更时,需要加 MDL 写锁。读锁之间不互斥,即可以多个线程对一张表进行并发增删改。读写锁与写锁,之间是互斥的,用来保证变更表结构操作的安全性。因此,如果有两个线程要同时给一个表加字段,其中一个要等另一个执行完才能开始执行。
读操作与写操作,都需要加 MDL 读锁,而 DDL 需要加 MDL 写锁,两者互斥的,那么 Online DDL 如何保障并发 DML 呢,这里就要介绍 Online DDL 加锁过程:
- 首先,在开始进行 DDL 时,需要拿到对应表的
MDL 写锁,然后进行一系列的准备工作; - 然后
MDL 写锁降级为MDL 读锁,开始真正的 DDL; - 最后再次将
MDL 读锁升级为MDL 写锁,完成 DDL 操作,释放 MDL 锁;
其中第二阶段占用了 DDL 整个过程的大量时间,在这段时间 DDL 才是真正的 online。
那么问题来了,如果有一个大查询持有 MDL 读锁,那么我们此时进行一个 DDL 操作后,因为查询持有读锁,DDL 需要加写锁,所以变更必须等待查询结束才能进行,此时再进行一个查询就会被卡住,请看案例
| Session 1 | Session 2 | Session 3 | Session 4 |
|---|---|---|---|
| begin;select * from sbtest1 limit 5; | |||
| select * from sbtest1 limit 5; | |||
| alter table sbtest1 drop column fantasy ,ALGORITHM=INPLACE, LOCK=NONE; ❌ | |||
| select * from sbtest1 limit 5; ❌ |
Session 1 开启一个事物,执行一条查询,此时 Session 1 持有 MDL 读锁;
Session 2 也执行一条查询,执行一条查询,正常执行;
Session 3 执行一条 DDL 语句,因为需要 MDL 写锁,被 Session 1 读锁;
Session 4 执行一条查询,因为需要读锁,但是因为 Session 3 也处于等待状态,后面的增删改查都处于等待状态。也就是说这张表完全不可用了。
即使变更支持 online 也非常怕长事务,所以生产环境大表变更前,我们可以去查会话和 innodb_trx 表,确认没有长事务,避免变更被 MDL 读锁堵塞。
看了上面的案例,我们理想状态下 DDL 变更是什么样的呢?
- DDL 请求锁时可以带上超时时间,即使拿不到锁也不会影响后面的业务语句;
- 对数据库的性能影响最小,大表变更非常令人头疼;
- 不会给从库带来太大延迟,大表变更后从库往往延迟十几分钟,读写分离的话会影响业务查询;
2. 变更工具
MySQL 变更比较常用的工具有大名鼎鼎的 PT 生态 **percona pt-online-schema-change **和 Facebook OSC 但是它们都是基于触发器来实现的,简单来讲就是通过数据库的触发器把作用在源表的操作在一个事务内同步到修改后的表中,这在业务高峰期时会极大的加重主库的负载。
gh-ost 是由 Github 开发的一款开源 **online DDL **工具,使用订阅和过滤 binlog 的方式代替原来的触发器来做的增量数据同步,这样可以降低主库负载,异步的执行。
使用 gh-ost 的优点:
- 不会给主库带来太大负载;
- 不会导致从库有太大延迟,大表变更经常会导致从库延迟很长时间;
- 支持阿里云 RDS,为云上变更提供了参数 –aliyun-rds;
- 通过 binlog 实现增量数据的获取,基本做到了原子性的切换;
- 可暂停,动态控制限流,切换时间可设定;
限制:
- 使用 DTS 做数据同步,可能会导致同步失败,仅影响同步对象;
- 不能对外键关系及触发器的表进行 online DDL;
- 若有同名但是字母大小写不同的表则无法进行修改;
- 表必须有主键或者唯一索引;
3. gh-ost 原理解析
官方图解 (https://github.com/github/gh-ost)
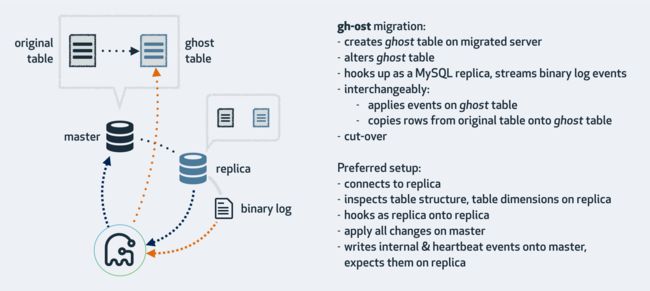
主要执行过程:
- 检查是否有外键触发器及主键信息;
- 检查是否主库或从库,是否开启 log_slave_updates 以及 binlog 信息;
- 检查 gho 和 ghc 结尾的临时表是否存在;
- 创建 ghc 结尾的表,存数据迁移的信息,以及 binlog 信息等;
- 初始化 stream 的连接,添加 binlog 的监听;
- 根据 alter 语句创建 gho 结尾的幽灵表;
- 开启迁移数据,按照主键把源表数据写入到 gho 结尾的表上,以及 binlog apply;
- 进入 cut-over 阶段,锁住主库的源表,等待 binlog 应用完毕,然后替换 gh-ost 表为源表;
- 清理 ghc 表,删除 socket 文件。
cut-over 即表 rename 阶段,gh-ost 利用了 MySQL 的一个特性,原子性的 rename 请求,在所有被 blocked 的请求中,rename 优先级永远是最高的。gh-ost 基于此设计了该方案:一个连接对原表加锁,另启一个连接尝试 rename 操作,此时会被阻塞住,当释放 lock 的时候,rename 会首先被执行,其他被阻塞的请求会继续应用到新表。
4. 安装部署
下载地址 gh-ost GA 版本存档 二进制包,开箱即用。

5. 操作演示
5.1. 重点参数介绍
下面介绍 gh-ost 中重点参数:
-execute:如果不添加该参数,仅进行环境检查测试,不实际执行;-assume-rbr:如果用户没有 Super 权限的话,需要加上这个参数,这样 gh-ost 会认为 Binlog 本身就是 row 模式,不会再去修改;-max-load:可以添加一些 MySQL 状态变量阈值,例如:--max-load=Threads_running=20则表示 MySQL 线程数大于 20 则进入限流模式,使用逗号分隔指定多个状态变量;-critical-load:可以添加一些 MySQL 状态变量阈值,如果超过阈值则暂停工作,等待一段时间后重试,由-critical-load-interval-milli来设置等待多少毫秒;-chunk-size:在每次迭代中处理的行数量(允许范围:100-100000),默认值为1000;-dml-batch-size:在单个事务中应用 DML 事件的批量大小(范围1-100),默认值为10;-cut-over-lock-timeout-seconds:gh-ost 在 cut-over 阶段最大锁等待时间,当锁超时时,gh-ost 的 cut-over 将重试;-discard-foreign-keys:有风险,加上该参数,表如果与外键约束,幽灵表迁移后不会保留,如果是故意想清理外键时,比较有用;-exact-rowcount:如果指定该参数,则使用 select count() 来统计表行数,不添加则是使用 explain 来预估行数,会影响进度统计,大表 count() 还是有风险的,建议不使用;-heartbeat-interval-millis:多久写入一条日志信息,默认 100 毫秒;-ok-to-drop-table:切换完成后,是否删除源表?drop 大表是一个非常消耗 IO 的操作,默认切换后不删除源表,如果需要切换完成立即删除源表需要指定该参数;-timestamp-old-table:在旧表名中使用时间戳。这会使旧表名称具有唯一且无冲突的交叉迁移;-postpone-cut-over-flag-file:创建 flag 文件,表迁移完成后,进入等待 cut-over 阶段,直到该文件被删除,通过该参数用户可以自定义切换时间;-panic-flag-file:当该文件被创建,则立即停止 gh-ost 工作,直接停止,不会进行环境清理;-throttle-additional-flag-file:当该文件被创建,则暂停 gh-ost 工作;-aliyun-rds:阿里云 RDS 使用需要添加该参数,可以绕开非法字符校验,正常使用。
上面就是常用的参数,用户可以控制切换时间,锁超时时间,以及迁移阶段对源库的负载。除此之外 gh-ost 还有三种操作模式:
- 连接到从库,在主库做迁移;
- 直接在主库上面操作;
- 在从库上修改和测试;
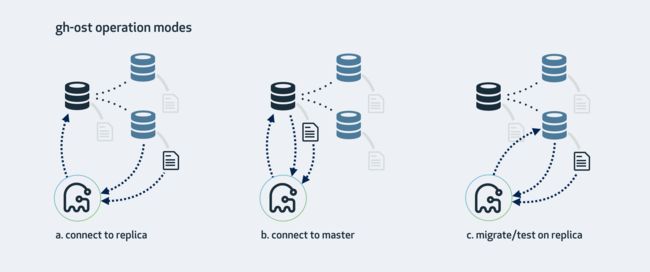
大部分变更我们使用 connect to master 模式,其它两种模式感兴趣详细可以参数官方文档,在此不详细介绍:https://github.com/github/gh-ost/blob/master/doc/cheatsheet.md
5.2. 执行变更
/myinstall/gh-ost \
--max-load=Threads_running=30 \
--critical-load=Threads_running=50 \
--critical-load-interval-millis=5000 \
--chunk-size=1000 \
--dml-batch-size=10 \
--user="cooh" \
--password="112233" \
--host='127.0.0.1' \
--port=3306 \
--database="sbtest" \
--table="sbtest1" \
--alter="engine=innodb" \
--verbose \
--assume-rbr \
--cut-over=default \
--cut-over-lock-timeout-seconds=1 \
--allow-on-master \
--concurrent-rowcount \
--default-retries=30 \
--heartbeat-interval-millis=2000 \
--panic-flag-file=/myinstall/ddl_room/ghost.panic.flag \
--postpone-cut-over-flag-file=/myinstall/ddl_room/ghost.postpone.flag \
--serve-socket-file=/myinstall/ddl_room/ghost.sock \
--throttle-additional-flag-file=/myinstall/ddl_room/ghost.pause.flag \
--timestamp-old-table \
--execute 2>&1 | tee /myinstall/ddl_room/ddl_sbtest1.log &
# 参数解释和设置技巧
# 这两个参数可以先使用 show status like 'Threads_running';
# 了解平时数据库线程数,再进行设置。
--max-load=Threads_running=30
--critical-load=Threads_running=50
# 下面两个参数影响着迁移阶段的速度,如果开启后观察数据库压力较大,可以动态调整
--chunk-size=1000
--dml-batch-size=10
# 各种操作在 panick 前重试次数,默认 60 次
--default-retries
# 切换完成后,给源表添加时间戳,如果不要求切换完立即删除源表,建议使用该参数
--timestamp-old-table
# 切换完后,立即删除源表,如果表比较大会影响 IO 可根据实际情况设定
--ok-to-drop-table
# 设置暂停、退出 flag 的文件位置,建议为 gh-ost 创建一个单独文件夹存放 flag 文件
--panic-flag-file
--throttle-additional-flag-file
--serve-socket-file
# 如果想自定义切换时间,可以使用该参数,常被嵌入自动化 DDL 平台
--postpone-cut-over-flag-file
# 步骤失败后,重试次数,例如切换获取锁,尝试多少次,如果一直没有则终止任务
--default-retries
执行 DDL:
操作过程中会自动创建两个中间状态表 _gho 幽灵表也就是目标表,_ghc 是记录 gh-ost 执行状态的表:
cooh@mysql 16:36: [sbtest]>show tables;
+------------------+
| Tables_in_sbtest |
+------------------+
| _sbtest1_ghc |
| _sbtest1_gho |
| sbtest1 |
+------------------+
3 rows in set (0.00 sec)
可以通过查询 _ghc 表来查询变更进度和状态:
cooh@mysql 16:40: [sbtest]>select * from _sbtest1_ghc order by id desc limit 1\G
*************************** 1. row ***************************
id: 344
last_update: 2022-04-06 16:40:12
hint: copy iteration 100 at 1649234412
value: Copy: 99999/99999 100.0%; Applied: 0; Backlog: 0/1000; Time: 4m0s(total), 2s(copy); streamer: mysql-bin.000005:344430440; Lag: 0.99s, HeartbeatLag: 1.00s, State: postponing cut-over; ETA: due
1 row in set (0.00 sec)
Copy: 99999/99999 100.0%; 需要迁移 99999 行,目前已迁移 99999 行,进度 100.0%
Applied: 0,指在二进制日志中处理的 event 数量。在上面的例子中,迁移表没有流量,因此没有被处理日志 event。
Backlog: 0/1000,表示我们在读取二进制日志方面表现良好,在二进制日志队列中没有任何积压(Backlog)事件。
Backlog: 7/1000,当复制行时,在二进制日志中积压了一些事件,并且需要应用。
Backlog: 1000/1000,表示我们的 1000 个事件的缓冲区已满(程序写死的 1000 个事件缓冲区,低版本是 100 个)此时就注意 binlog 写入量非常大,gh-ost 处理不过来 event 了,可能需要暂停 binlog 读取,需要优先应用缓冲区的事件。
State: 目前 gh-ost 的状态
streamer: mysql-bin.000005:344430440; 表示当前已经应用到 binlog 文件位置
此时状态为:postponing cut-over 即等待切换,因为我们使用
--postpone-cut-over-flag-file=/myinstall/ddl_room/ghost.postpone.flag 参数,由用户来控制切换时间,如果我们不删除 ghost.postpone.flag 就会一直处理等待状态,我们删除后:
Copy: 99999/99999 100.0%; Applied: 0; Backlog: 0/1000; Time: 8m38s(total), 2s(copy); streamer: mysql-bin.000005:344547927; Lag: 0.99s, HeartbeatLag: 0.04s, State: migrating; ETA: due
2022-04-06 16:44:50 INFO Setting RENAME timeout as 1 seconds
2022-04-06 16:44:50 INFO Session renaming tables is 200
2022-04-06 16:44:50 INFO Issuing and expecting this to block: rename /* gh-ost */ table `sbtest`.`sbtest1` to `sbtest`.`_sbtest1_20220406163612_del`, `sbtest`.`_sbtest1_gho` to `sbtest`.`sbtest1`
2022-04-06 16:44:50 INFO Found atomic RENAME to be blocking, as expected. Double checking the lock is still in place (though I don't strictly have to)
2022-04-06 16:44:50 INFO Checking session lock: gh-ost.194.lock
2022-04-06 16:44:50 INFO Connection holding lock on original table still exists
2022-04-06 16:44:50 INFO Will now proceed to drop magic table and unlock tables
2022-04-06 16:44:50 INFO Dropping magic cut-over table
2022-04-06 16:44:50 INFO Releasing lock from `sbtest`.`sbtest1`, `sbtest`.`_sbtest1_20220406163612_del`
2022-04-06 16:44:50 INFO Tables unlocked
2022-04-06 16:44:50 INFO Tables renamed
2022-04-06 16:44:50 INFO Lock & rename duration: 1.006946435s. During this time, queries on `sbtest1` were blocked
[2022/04/06 16:44:50] [info] binlogsyncer.go:164 syncer is closing...
2022-04-06 16:44:51 INFO Closed streamer connection. err=<nil>
2022-04-06 16:44:51 INFO Dropping table `sbtest`.`_sbtest1_ghc`
[2022/04/06 16:44:51] [error] binlogsyncer.go:631 connection was bad
[2022/04/06 16:44:51] [error] binlogstreamer.go:77 close sync with err: Sync was closed
[2022/04/06 16:44:51] [info] binlogsyncer.go:179 syncer is closed
2022-04-06 16:44:51 INFO Table dropped
2022-04-06 16:44:51 INFO Am not dropping old table because I want this operation to be as live as possible. If you insist I should do it, please add `--ok-to-drop-table` next time. But I prefer you do not. To drop the old table, issue:
2022-04-06 16:44:51 INFO -- drop table `sbtest`.`_sbtest1_20220406163612_del`
2022-04-06 16:44:51 INFO Done migrating `sbtest`.`sbtest1`
2022-04-06 16:44:51 INFO Removing socket file: /myinstall/ddl_room/ghost.sock
2022-04-06 16:44:51 INFO Tearing down inspector
2022-04-06 16:44:51 INFO Tearing down applier
2022-04-06 16:44:51 INFO Tearing down streamer
2022-04-06 16:44:51 INFO Tearing down throttler
# Done
表示 gh-ost 已执行完成,ghc 表已清理,源表名改为:_sbtest1_20220406163612_del
cooh@mysql 16:46: [sbtest]>show tables;
+-----------------------------+
| Tables_in_sbtest |
+-----------------------------+
| _sbtest1_20220406163612_del |
| sbtest1 |
+-----------------------------+
2 rows in set (0.00 sec)
5.3. 动态控制
用户可以通过操作特定的文件对正在执行的 gh-ost 进行动态控制,请看下面案例:
-
停止 gh-ost:
指定 --panic-flag-file=/myinstall/ddl_room/ghost.panic.flag 参数,我们通过创建 ghost.panic.flag 来终止 gh-ost。
touch /myinstall/ddl_room/ghost.panic.flag
会输出下面日志:
2022-04-06 16:56:14 FATAL Found panic-file /myinstall/ddl_room/ghost.panic.flag. Aborting without cleanup -
暂停/开始:
指定 --throttle-additional-flag-file=/myinstall/ddl_room/ghost.pause.flag 参数,我们可以通过创建删除 ghost.pause.flag 文件来控制。
-
开启限流:
echo throttle | socat - /myinstall/ddl_room/ghost.sock -
关闭限流:
echo no-throttle | socat - /myinstall/ddl_room/ghost.sock -
动态修改参数:
echo chunk-size=1024 | socat - /myinstall/ddl_room/ghost.sock echo max-lag-millis=100 | socat - /myinstall/ddl_room/ghost.sock echo max-load=Thread_running=23 | socat - /myinstall/ddl_room/ghost.sock
6. 风险提示
-
gh-ost 执行 cut-over 阶段,会短暂堵塞变更表的读写操作,可以选择业务低峰期进行切换操作,减少对业务影响。
-
大表变更前需要注意 存储空间是否充裕,可以通过 SQL 查询元数据。
SELECT TABLE_NAME, round(SUM(data_length + index_length) / 1024 / 1024, 2) AS TOTAL_MB, round(SUM(data_length) / 1024 / 1024, 2) AS DATA_MB, round(SUM(index_length) / 1024 / 1024, 2) AS INDEX_MB FROM INFORMATION_SCHEMA.tables WHERE TABLE_SCHEMA = 'sbtest' and TABLE_NAME = 'sbtest1' GROUP BY TABLE_NAME; -- 输出结果: +------------+----------+---------+----------+ | TABLE_NAME | TOTAL_MB | DATA_MB | INDEX_MB | +------------+----------+---------+----------+ | sbtest1 | 24.06 | 21.55 | 2.52 | +------------+----------+---------+----------+ -
大表变更周期长,如果一直获取不到锁,可能会变更失败,若变更失败不会影响现有的业务,但表结构变更需要重新开始,因此建议线上表仅保留线上热点活跃数据,历史数据及时归档,将表保持在一种健康状态。
-
添加唯一索引时,会造成索引字段重复数据丢失,如果使用 MySQL 原生 DDL 添加唯一索引,如果有重复值会报错
[23000][1062] Duplicate entry因为 gh-ost 在数据迁移阶段使用的是insert ignore所以不会报错,但是索引字段的重复条目会丢失,这点需要确认风险。