2024春招面试题:Java并发相关知识_threadlocal经典的应 场景就是连接管理
// 程序运行时,有主线程和垃圾回收线程也在运行。如果超过2个线程在运行,那就说明上面的20个线程还有没执行完的,就需要等待
while (Thread.activeCount()>2){
Thread.currentThread().getThreadGroup().activeCount();
Thread.yield();// 交出CPU 执行权
}
System.out.println("number值加了20000次,此时number的实际值是:" + myData.number);
}
}
2. 禁止指令重排序优化。
int a = 0;
bool flag = false;
public void write() {
a = 2; //1
flag = true; //2
}
public void multiply() {
if (flag) { //3
int ret = a * a;//4
}
}
write方法里的1和2做了重排序,线程1先对flag赋值为true,随后执行到线程2,ret直接计算出结果,
再到线程1,这时候a才赋值为2,很明显迟了一步。
但是用 flag 使用 volatile修饰之后就变得不一样了
使用volatile关键字修饰后,底层执行时会禁止指令重新排序,按照顺序指令
## 5.为什么用线程池?解释下线程池参数?
1、降低资源消耗;提高线程利用率,降低创建和销毁线程的消耗。
2、提高响应速度;任务来了,直接有线程可用可执行,而不是先创建线程,再执行。
3、提高线程的可管理性;线程是稀缺资源,使用线程池可以统一分配调优监控。
/*
corePoolSize 代表核心线程数,也就是正常情况下创建工作的线程数,这些线程创建后并不会
消除,而是一种常驻线程
maxinumPoolSize 代表的是最大线程数,它与核心线程数相对应,表示最大允许被创建的线程
数,比如当前任务较多,将核心线程数都用完了,还无法满足需求时,此时就会创建新的线程,但
是线程池内线程总数不会超过最大线程数
keepAliveTime 、 unit 表示超出核心线程数之外的线程的空闲存活时间,也就是核心线程不会
消除,但是超出核心线程数的部分线程如果空闲一定的时间则会被消除,我们可以通过keepAliveTime 、
unit 表示超出核心线程数之外的线程的空闲存活时间,
也就是核心线程不会 setKeepAliveTime 来设置空闲时间
workQueue 用来存放待执行的任务,假设我们现在核心线程都已被使用,还有任务进来则全部放
入队列,直到整个队列被放满但任务还再持续进入则会开始创建新的线程
ThreadFactory 实际上是一个线程工厂,用来生产线程执行任务。我们可以选择使用默认的创建
工厂,产生的线程都在同一个组内,拥有相同的优先级,且都不是守护线程。当然我们也可以选择
自定义线程工厂,一般我们会根据业务来制定不同的线程工厂
Handler 任务拒绝策略,有两种情况,第一种是当我们调用 shutdown 等方法关闭线程池后,这
时候即使线程池内部还有没执行完的任务正在执行,但是由于线程池已经关闭,我们再继续想线程
池提交任务就会遭到拒绝。另一种情况就是当达到最大线程数,线程池已经没有能力继续处理新提
交的任务时,这是也就拒绝
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
java 中常见的几种线程池
// 创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,
//若无可回收,则新建线程。
Executors.newCachedThreadPool();//
//创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
Executors.newFixedThreadPool(10);
//创建一个定长线程池,支持定时及周期性任务执行。
Executors.newScheduledThreadPool(10);// 核心线程数10
//创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,
//保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
Executors.newSingleThreadExecutor();
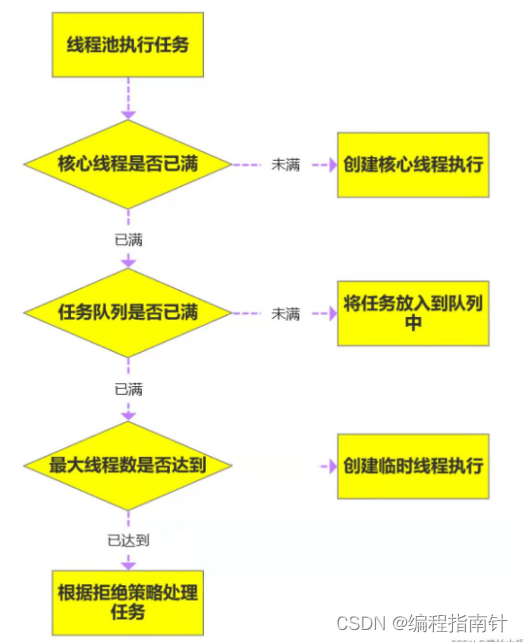
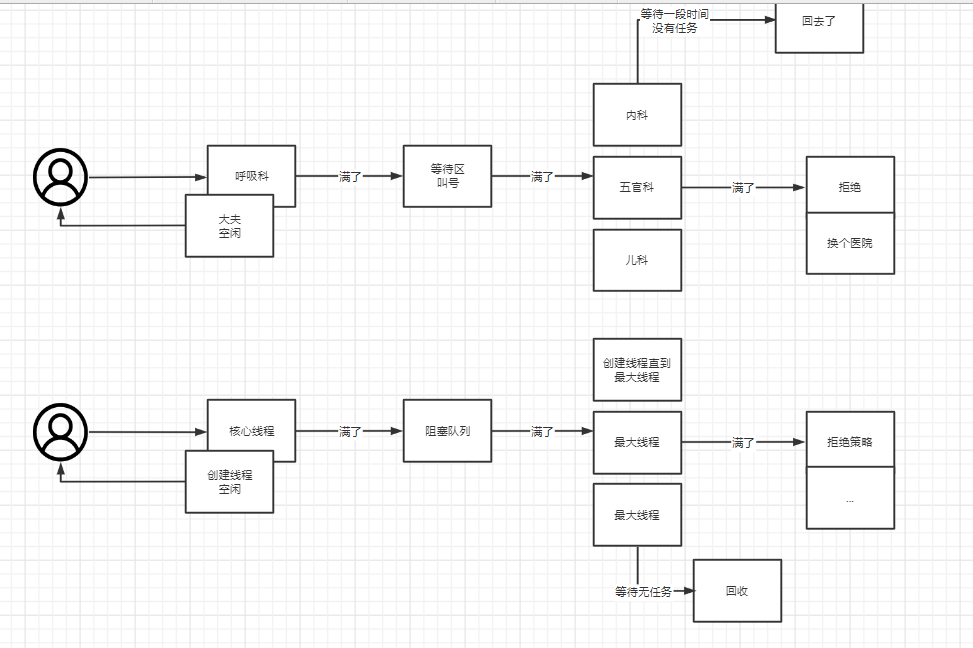
//看源码,解释一下这三个创建线程池方法的作用
Executors.newFixedThreadPool(1);
Executors.newCachedThreadPool();
Executors.newSingleThreadExecutor();
##
## 6.项目中线程池的使用?
1. tomcat 自带线程池
2. CompletableFuture 创建线程时指定线程池,防止创建线程过多
CompletableFuture task1 = CompletableFuture.supplyAsync(()->{
result.setCluesNum(reportMpper.getCluesNum(beginCreateTime, endCreateTime, username));
return null;
},指定线程池);
案例:[CompletableFuture异步和线程池讲解 - 不懒人 - 博客园](https://bbs.csdn.net/topics/618545628)
## 7 synchronized
### synchronized 锁释放时机
● 当前线程的同步方法、代码块执行结束的时候释放
1) 正常结束
2) 异常结束出现未处理的error或者exception导致异常结束的时候释放
● 程序执行了 同步对象 wait 方法 ,当前线程暂停,释放锁
## 8. Sychronized和ReentrantLock的区别
1. sychronized是⼀个关键字,ReentrantLock是⼀个类
2. sychronized的底层是JVM层⾯的锁(底层由C++ 编写实现),ReentrantLock是API层⾯的锁 (java 内部的一个类对象)
3. sychronized会⾃动的加锁与释放锁,ReentrantLock需要程序员⼿动加锁与释放锁
4. sychronized是⾮公平锁,ReentrantLock可以选择公平锁或⾮公平锁
注: 假设多个线程都要获取锁对象,满足先等待的线程先获得锁则是公平锁,否则是非公平锁
1. sychronized锁的是对象,锁信息保存在对象头中,ReentrantLock通过代码中int类型的state标识
来标识锁的状态
1. sychronized底层有⼀个锁升级的过程(访问对象线程数由少到多,竞争由不激烈到激烈,底层会通过一种锁升级机制 无锁->偏向锁->轻量级锁->重量级锁,保证性能) ,会使用自旋 线程频繁等待唤醒会浪费性能,特别是锁的获取也许只需要很短的时间 ,不限于等待,直接执行简单代码while(true)执行完抢锁 来优化性能
代码演示
可重入演示
public static void main(String[] args) {
// 可重入锁演示
save();
}
public synchronized static void save() {
System.out.println(“save”);
update();
}
public synchronized static void update() {
System.out.println(“update”);
}
ReentrantLock 使用演示
public class TestDemo {
public static void main(String[] args)throws Exception {
ReentrantLock lock = new ReentrantLock();
// 线程1
new Thread(()->{
lock.lock(); // 加锁
add();
lock.unlock();// 解锁
}).start();
// 线程2
new Thread(()->{
lock.lock(); // 加锁
add();
lock.unlock();// 解锁
}).start();
Thread.sleep(3000);
System.out.println(i);
}
static int i =0;
public static void add() {
i++;
}
}
公平/非公平锁演示
package com.huike;
import java.util.concurrent.locks.ReentrantLock;
public class TestDemo {
public static void main(String[] args)throws Exception {
ReentrantLock lock = new ReentrantLock(false);
// 线程1
new Thread(()->{
lock.lock(); // 加锁
add();
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
lock.unlock();// 解锁
},“t1”).start();
// 线程2
new Thread(()->{
lock.lock(); // 加锁
add();
lock.unlock();// 解锁
},"t2").start();
new Thread(()->{
lock.lock(); // 加锁
add();
lock.unlock();// 解锁
},"t3").start();
for (int j = 0; j < 100000; j++) {
new Thread(()->{
lock.lock(); // 加锁
add();
lock.unlock();// 解锁
}).start();
}
Thread.sleep(30000);
System.out.println(i);
}
static int i =0;
public static void add() {
i++;
System.out.println(Thread.currentThread().getName()+"获得了锁");
}
}
##
## 10. 悲观锁 vs 乐观锁
**要求**
* 掌握悲观锁和乐观锁的区别
**对比悲观锁与乐观锁**
* 悲观锁的代表是 synchronized 和 Lock 锁
* + 其核心思想是【线程只有占有了锁,才能去操作共享变量,每次只有一个线程占锁成功,获取锁失败的线程,都得停下来等待】
+ 线程从运行到阻塞、再从阻塞到唤醒,涉及线程上下文切换,如果频繁发生,影响性能
+ 实际上,线程在获取 synchronized 和 Lock 锁时,如果锁已被占用,都会做几次重试操作,减少阻塞的机会
* 乐观锁的代表是 AtomicInteger AtomicStampReference,使用 cas 来保证原子性
* + 其核心思想是【无需加锁,每次只有一个线程能成功修改共享变量,其它失败的线程不需要停止,不断重试直至成功】
+ 由于线程一直运行,不需要阻塞,因此不涉及线程上下文切换
+ 它需要多核 cpu 支持,且线程数不应超过 cpu 核数
## 12. ConcurrentHashMap的原理
### 12.1 JDK1.7
* 数据结构:Segment(大数组) + HashEntry(小数组) + 链表,每个 Segment 对应一把锁,如果多个线程访问不同的 Segment,则不会冲突
* 并发度:Segment 数组大小即并发度,决定了同一时刻最多能有多少个线程并发访问。Segment 数组不能扩容,意味着并发度在 ConcurrentHashMap 创建时就固定了(默认16,可以指定)
* 扩容:每个小数组的扩容相对独立,小数组在超过扩容因子时会触发扩容,每次扩容翻倍
* 其他Segment首次创建小数组时,会以Segment[0] 为原型为依据,数组长度,扩容因子都会以原型为准
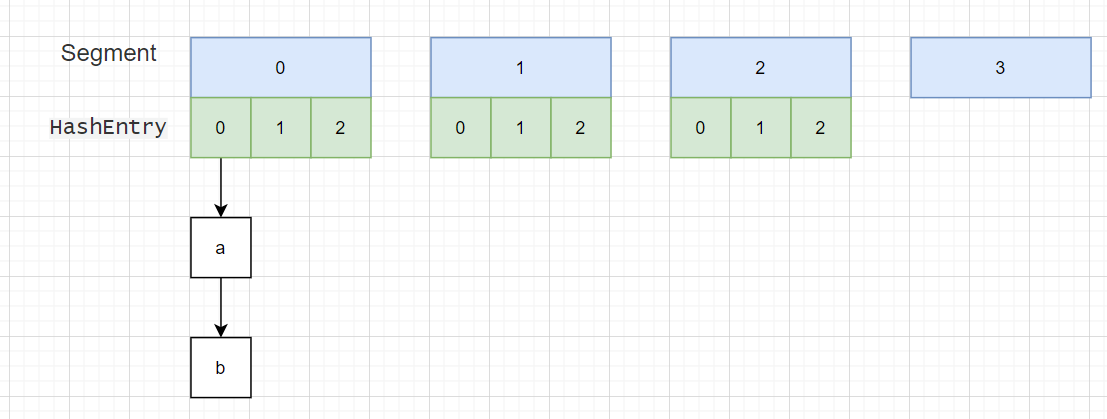
### 12.2 JDK1.8
* 数据结构:Node 数组 + 链表或红黑树,数组的每个头节点作为锁,如果多个线程访问的头节点不同,则不会冲突
* 并发度:Node 数组有多大,并发度就有多大,与 1.7 不同,Node 数组可以扩容
* 扩容条件:Node 数组满 3/4 时就会扩容(0.75 扩容因子)
* 扩容时并发 get
* + 根据是否为 ForwardingNode 来决定是在新数组查找还是在旧数组查找,不会阻塞
* 扩容时并发 put
* + 如果 put 的线程与扩容线程操作的链表是同一个,put 线程会阻塞
+
## 13. Hashtable 和 ConcurrentHashMap 有什么区别?其底层实现是什
## 么?
* Hashtable 与 ConcurrentHashMap 都是线程安全的 Map 集合
* Hashtable 并发度低,整个 Hashtable 对应一把锁,同一时刻,只能有一个线程操作它
* ConcurrentHashMap 并发度高,整个 ConcurrentHashMap 对应多把锁,只要线程访问的是不同锁,那么不会冲突
## 14. ThreadLocal
**作用**
* ThreadLocal 可以实现【资源对象】的线程隔离,让每个线程各用各的【资源对象】,避免争用引发的线程安全问题
* ThreadLocal 同时实现了线程内的资源共享
**原理**
1. ThreadLocal是Java中所提供的线程本地存储机制,可以利⽤该机制将数据缓存在某个线程内部,
该线程可以在任意时刻、任意⽅法中获取缓存的数据
2. ThreadLocal底层是通过ThreadLocalMap来实现的,每个Thread对象(注意不是ThreadLocal对
象)中都存在⼀个ThreadLocalMap,Map的key为ThreadLocal对象,Map的value为需要缓存的
值
3. 如果在线程池中使⽤ThreadLocal会造成内存泄漏,因为当ThreadLocal对象使⽤完之后,应该要
把设置的key,value,也就是Entry对象进⾏回收,但线程池中的线程不会回收,,⽽一般我们使用ThreadLocal时都是使用static 修饰,导致线程对象是通过 强引⽤指向ThreadLocalMap,ThreadLocalMap也是通过强引⽤指向Entry对象,线程不被回收,
Entry对象也就不会被回收,从⽽出现内存泄漏,解决办法是,在使⽤了ThreadLocal对象之后,⼿
动调⽤ThreadLocal的remove⽅法,⼿动清除Entry对象
4. ThreadLocal经典的应⽤场景就是连接管理(⼀个线程持有⼀个连接,该连接对象可以在不同的⽅
法之间进⾏传递,线程之间不共享同⼀个连接)
1. 项目中的使用: 项目中使用拦截器拦截请求后获取用户信息后放入ThreadLocal,然后在controller或service 获取用户信息
public class UserHolder {
// 这里使用static 修饰,会导致存储在 ThreadLocal 对象不会被回收,需要每次用完都 remove
private static final ThreadLocal tl = new ThreadLocal<>();
public static void setUser(Long userId) {
tl.set(userId);
}
public static Long getUser() {
return tl.get();
}
public static void removeUser(){
tl.remove();
}
}
----------------我们曾经写的拦截器中是有remove 的-----------------------------------------------------
public class UserInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 前置逻辑校验
UserHolder.setUser(xxxx);
// 放行
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
// 因为Tomcat 有线程池,多个线程会公用同一个 变量,为防止内存泄漏,使用完毕后 需要清理
UserHolder.removeUser();
}
}
ThreadLocalMap 的一些特点
* key 的 hash 值统一分配
* 初始容量 16,扩容因子 2/3,扩容容量翻倍
* key 索引冲突后用开放寻址法解决冲突
**弱引用 key**
ThreadLocalMap 中的 key 被设计为弱引用,原因如下
* Thread 可能需要长时间运行(如线程池中的线程),如果 key 不再使用,需要在内存不足(GC)时释放其占用的内存

**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
h 值统一分配
* 初始容量 16,扩容因子 2/3,扩容容量翻倍
* key 索引冲突后用开放寻址法解决冲突
**弱引用 key**
ThreadLocalMap 中的 key 被设计为弱引用,原因如下
* Thread 可能需要长时间运行(如线程池中的线程),如果 key 不再使用,需要在内存不足(GC)时释放其占用的内存
[外链图片转存中...(img-PqyKy09H-1714694709097)]
[外链图片转存中...(img-2G3iwuDW-1714694709097)]
[外链图片转存中...(img-EkA9yjr3-1714694709098)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**