Python下载中国数据库大会(DTCC2024)PPT全集
程序下载
网盘下载
背景
==
前几天中国数据库大会风风火火的在京举行了,期间干货满满,收获良多。在学大佬们的ppt时,发现只能一篇一篇预览,对于求知欲强烈的小编来说简直太难受了,于是便写了个程序,一键获取所有ppt。
2020年12月21日~12月23日,由 IT168 旗下 ITPUB 企业社区平台主办的第十一届中国数据库技术大会(DTCC2020),将在北京隆重召开。大会以“架构革新 高效可控”为主题,设置2大主会场,20+技术专场,将邀请超百位行业专家,重点围绕数据架构、AI与大数据、传统企业数据库实践和国产开源数据库等内容展开分享和探讨,为广大数据领域从业人士提供一场年度盛会和交流平台。
历经十年的积累与沉淀,如今的DTCC已然成为国内数据库领域的技术风向标,见证了整个行业的发展与演变。作为顶级的数据领域技术盛会,DTCC2020将继续秉承一贯的干货分享和实践指导原则,期待大家的热情参与!
中国数据库大会链接:http://dtcc.it168.com/

软件环境:python 3
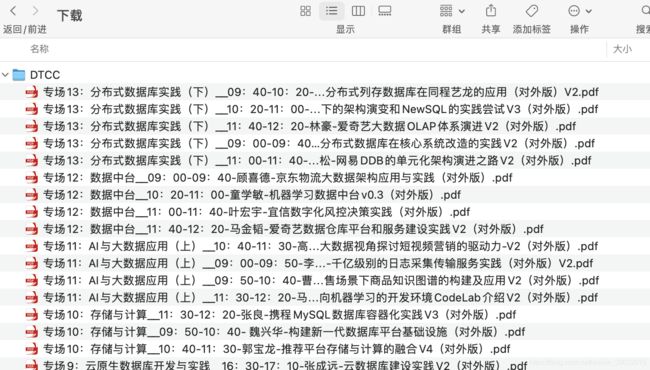
效果展示
========
话不多说,上代码
encoding: utf-8
from bs4 import BeautifulSoup
import requests
from urllib.request import urlopen
import re
import json
def visit(url):
headers = {
“User-Agent”: “Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)”,
“accept”: “application/json, text/javascript, /; q=0.01”,
“accept-encoding”: “gzip, deflate, br”,
“accept-language”: “zh-CN,zh;q=0.9”,
“content-type”: “application/x-www-form-urlencoded; charset=UTF-8”,
“cookie”: “”, – 填自己的
“referer”: “”,
“sec-fetch-dest”: “document”,
“sec-fetch-mode”: “navigate”,
“sec-fetch-site”: “same-origin”,
}
res = requests.get(url,headers=headers)
bsObj = BeautifulSoup(res.text, “html.parser”)
return bsObj
def visit_homepage(url):
bsObj = visit(url)
content = bsObj.find(‘div’, class_=“content”)
content_list = content.select(“p”)
category = []
for i in range(4,len(content_list)):
try:
urls = content_list[i].a[‘href’]
name = content_list[i].get_text(“|”).split(“|”)[0].replace(’ ‘,’‘).replace(’\xa0’,‘’)
category.append([name,urls])
except:
pass
print(category)
return category
def download_pdf(conf,path):
category_name = conf[0]
category_url = conf[1]
bsObj = visit(category_url)
res = re.search(r’(.)token:(.?),',str(bsObj) ,re.M|re.I)
token = res.group(2).replace(‘"’,‘’).replace(’ ‘,’')
arts = re.findall(r’(.)li data-docinfo=(.?)}',str(bsObj) ,re.M|re.I)
for art in arts:
art_str = “{”+str(art).split(‘{’)[1].replace(“')”,“}”)
art_dic = json.loads(art_str)
id = art_dic[‘id’]