加载pkl文件,Python报错AttributeError: Can‘t get attribute ‘DeepFM‘ on <module ‘__main__‘ from...>
背景
模型同学发过来的pkl格式的模型,在系统中加载的时候,报错 AttributeError: module '__main__' has no attribute 'LabelEncoderExt',尝试了很多种方式,最后终于解决了这个问题,记录一下,以后遇到类似的可以做参考。
项目代码及结构
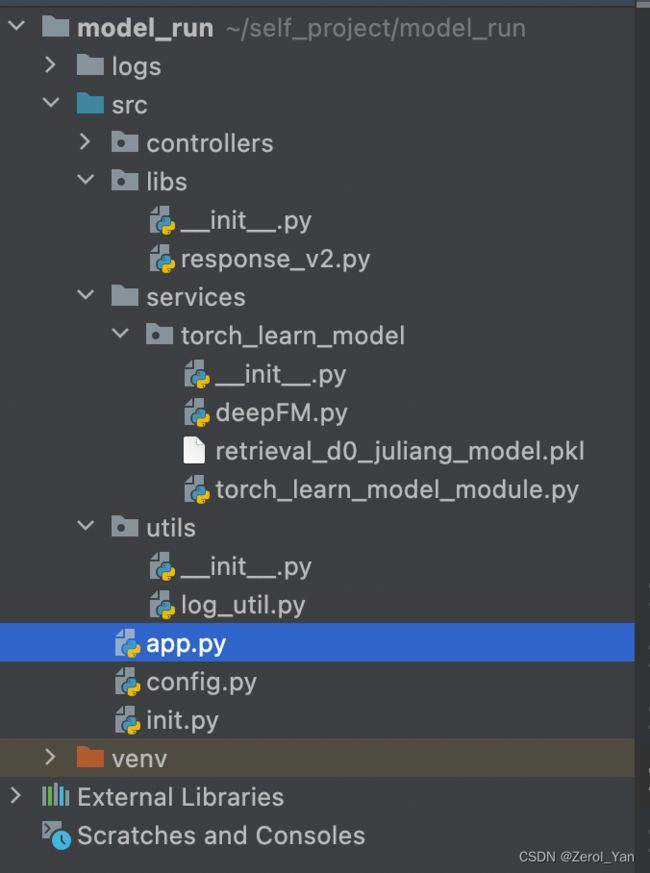
app.py
from init import app
import json
from flask import request
@app.route('/model_run/general_model/torch_learn_model', methods=['POST'])
def yzl_pkl_test_model():
from services.torch_learn_model.torch_learn_model_module import predict
from libs.response_v2 import ResponseV2
args = json.loads(request.get_data())
result = predict(args)
data = {"result": result}
return ResponseV2.success(data)
def start_app():
return app
if __name__ == '__main__':
start_app().run('0.0.0.0', debug=False, port=8080)
torch_learn_model_module.py
import numpy as np
import pandas as pd
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from utils.log_util import Logger
from sklearn.preprocessing import LabelEncoder
class LabelEncoderExt(object):
def __init__(self):
self.label_encoder = LabelEncoder()
def fit(self, data_list):
self.label_encoder = self.label_encoder.fit(list(data_list) + ['Unknown'])
self.classes_ = self.label_encoder.classes_
return self
def transform(self, data_list):
new_data_list = list(data_list)
for unique_item in np.unique(data_list):
if unique_item not in self.label_encoder.classes_:
new_data_list = ['Unknown' if x == unique_item else x for x in new_data_list]
return self.label_encoder.transform(new_data_list)
def predict(args):
dir_path = os.path.abspath(os.path.dirname(__file__))
Logger.info("开始加载PKL文件:jdzad_retrieval_d0_juliang_model,{}".format(
os.path.join(dir_path, 'retrieval_d0_juliang_model.pkl')))
model = torch.load(os.path.join(dir_path, 'retrieval_d0_juliang_model.pkl'))
Logger.info("PKL文件 retrieval_d0_juliang_model 加载结束,开始执行 model.eval")
model.eval()
return args
deepFM.py
import torch
import torch.nn as nn
from utils.log_util import Logger
class DeepFM(nn.Module):
def __init__(self, cate_fea_nuniqs, nume_fea_size=0, emb_size=128,
hid_dims=[256, 64], num_classes=1, dropout=[0.1, 0.1]):
pass
def forward(self, X_sparse, X_dense=None):
pass在该模型示例中,torch_learn_model_module 是入模之前的处理模块,通常包括对入参的处理,加载 pkl 模型,对模型预测的结果处理等部分。模型中用到了 DeepFM 模型,模型训练完成后,使用 torch.save(model, 'retrieval_d0_juliang_model.pkl') 方式保存模型到文件 retrieval_d0_juliang_model.pkl 中,这种方式将整个模型对象保存到文件中,包括模型的结构、参数、权重以及其他相关信息。因此,在加载模型时可以直接得到一个完整的模型对象,无需手动创建模型结构或加载状态字典。
运行异常
项目启动后,调用该模型,程序报错 AttributeError: Can't get attribute 'DeepFM' on 通过异常提示,可以知道该问题的原因是系统的运行过程中,找不到 DeepFM 模块,那么我们可以提前把这个模块 import 进来。具体的引入位置,要放在哪里呢?我尝试过放在 torch_learn_model_module.py 文件头部,放在 app.py 文件头部,放在 start_app() 方法中,都会报同样的异常。只有放在 if __name__ == '__main__': 下才可以。 那么有同学问了,为什么创建模型的时候没有遇到这种问题,即便是在创建模型时先通过 joblib.dump 保存 PKL 文件,再通过 joblib.load 加载 PKL 文件,都是没有问题的。 那是因为模型训练时,它们在同一个脚本文件下,即属于同一个模块,PKL 文件执行保存的那段代码,是跟 在 Python 中,当一个模块被直接运行时(即作为主程序执行时),其模块名为 然而,当我在 将依赖的类放在 if __name__ == '__main__': 代码块下是一种解决方案,但随着模型数量的增加,该代码块的内容就会比较臃肿。况且真正发布到生产,基本不会使用这种方式,可以尝试如下解决方案。 保存 PKL 文件的时候,就指定正确的 module 信息,假设 训练模型时,不要把依赖的类跟模型训练代码放在同一个脚本文件中,将相关类分别创建 .py 文件,然后通过 import 方式将这些类引入进来。Traceback (most recent call last):
File "/virtualenv/model_run/lib/python3.6/site-packages/flask/app.py", line 2447, in wsgi_app
response = self.full_dispatch_request()
File "/virtualenv/model_run/lib/python3.6/site-packages/flask/app.py", line 1952, in full_dispatch_request
rv = self.handle_user_exception(e)
File "/virtualenv/model_run/lib/python3.6/site-packages/flask_cors/extension.py", line 161, in wrapped_function
return cors_after_request(app.make_response(f(*args, **kwargs)))
File "/virtualenv/model_run/lib/python3.6/site-packages/flask/app.py", line 1821, in handle_user_exception
reraise(exc_type, exc_value, tb)
File "/virtualenv/model_run/lib/python3.6/site-packages/flask/_compat.py", line 39, in reraise
raise value
File "/virtualenv/model_run/lib/python3.6/site-packages/flask/app.py", line 1950, in full_dispatch_request
rv = self.dispatch_request()
File "/virtualenv/model_run/lib/python3.6/site-packages/flask/app.py", line 1936, in dispatch_request
return self.view_functions[rule.endpoint](**req.view_args)
File "/self_project/model_run/src/app.py", line 10, in yzl_pkl_test_model
result = predict(args)
File "/self_project/model_run/src/services/torch_learn_model/torch_learn_model_module.py", line 36, in predict
model = torch.load(os.path.join(dir_path, 'retrieval_d0_juliang_model.pkl'))
File "/virtualenv/model_run/lib/python3.6/site-packages/torch/serialization.py", line 367, in load
return _load(f, map_location, pickle_module)
File "/virtualenv/model_run/lib/python3.6/site-packages/torch/serialization.py", line 538, in _load
result = unpickler.load()
AttributeError: Can't get attribute 'DeepFM' on 问题解决
if __name__ == '__main__':
from services.torch_learn_model.deepFM import DeepFM
start_app().run('0.0.0.0', debug=False, port=8080)
原因
DeepFM 类在同一个脚本中。但当我们把 PKL 文件放在一个单独的预测应用程序中,这个程序在加载模型时,因为模型构建和模型加载在两个不同的项目中,它们的 '__main__'是不同的,因此应用程序并不知道如何解释整个模型构建的流程。'__main__'。因此,当我在 if __name__ == '__main__' 内引入 DeepFM 类时,Python 会将当前模块视为主程序进行执行,而模块名为 '__main__',因此可以正确加载 DeepFM 类。start_app 方法中引入 DeepFM 类时,Python 可能会将当前模块视为一个子模块而不是主程序,因此模块名不再是 '__main__'。这可能会导致在加载模型文件时出现问题,因为模块名不再是 '__main__',而是由 Flask 运行时所确定的模块名。这会导致在加载模型文件时出现 Can't get attribute 'DeepFM' 的错误。可选择的解决方案
方案一
DeepFM 类在应用程序中会被保存到 deepFM.py 文件中,可以在保存之前添加如下代码:DeepFM.__module__ = "deepFM" 方案二