Python轻量级ORM框架——peewee
这里写目录标题
-
- Python中常用的ORM框架
- peewee使用经验
-
- 从数据库中导出模型
- 查询
-
- 统计类查询
- 优化子查询
- 参考文章
Python中常用的ORM框架
- SQLALchemy:重量级框架,适合企业级开发,容易与任意Web框架集成,学习成本更高
- Django ORM:Django框架中内嵌的ORM模块,易学易用,只适合Django项目使用
- peewee:轻量级框架,适合个人开发,容易与任意Web框架集成,API类似Django风格,易学易用
peewee使用经验
基本的安装和使用参考官方文档
从数据库中导出模型
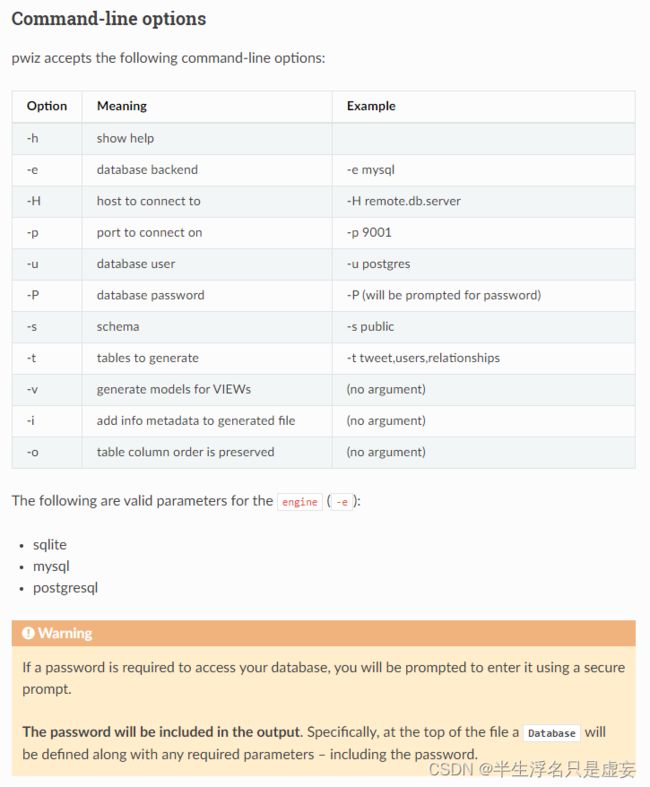
pwiz, a model generator
通过pip安装peewee会自动安装pwiz模块,使用pwiz模块导出模型(windows下注意带上第一个&符号):
& "E:\Program Files\Anaconda3\envs\project\python.exe" -m pwiz -e mysql -H 127.0.0.1 -p 3366 -u username -P -v database
查询
统计类查询
实现以下SQL:
select count(1) count, min(id) min, max(id) max from model where col is null;
对应的peewee查询:
query = Model.select(fn.count(1).alias('count'), fn.min(Model.id).alias('min'), fn.max(Model.id).alias('max')).where(Model.col.is_null()) # 这里只是定义查询,并不会执行SQL
返回Row对象:
result = query.get() # 如果查询结果集只有一条记录,可以使用get()直接读取,默认返回Row对象
# result = query.namedtuples().get()
print(result.count, result,min, result.max) # 通过对象属性直接访问查询结果
返回Tuple对象:
count, min, max = query.tuples().get()
print(count, min, max)
返回Dict对象:
result = query.dicts().get()
print(result['count'], result['min'], result['max'])
优化子查询
联表查询数据量较大时,可以使用子查询来优化查询性能,例如以下SQL:
select distinct p.id from
(select id, uid from table_a where (id between 100 and 1000) and (query_id is null) order by id limit(100)) p
left join table_b b on p.uid = b.uid
where b.type = 1 and b.distance = 0;
对应的peewee子查询:
p = (TableA.select(TableA.id.alias('id'), TableA.uid.alias('uid')).where((TableA.id.between(startId, endId)) & (TableA.query_id.is_null())).order_by(TableA.id).limit(100).alias('p'))
常规写法及其对应SQL:
p.select(TableA.id).distinct().left_outer_join(TableB, on=(TableA.uid == TableB.uid)).where((TableB.type == 1) & (WatchPoi.distance == 0))
SELECT DISTINCT `t1`.`id` FROM `table_a` AS `t1`
LEFT OUTER JOIN `table_b` AS `t2` ON (`t1`.`uid` = `t2`.`uid`)
WHERE (((`t1`.`id` BETWEEN 100 AND 1000) AND (`t1`.`query_id` IS NULL)) AND (`t2`.`type` = 1))
ORDER BY `t1`.`id` LIMIT 100
可以看到无法满足性能优化的要求,修改后的写法及其对应SQL:
p.select_from(p.c.id).distinct().left_outer_join(TableB, on=(p.c.uid == TableB.uid)).where((TableB.type == 1) & (WatchPoi.distance == 0))
或者
def resObject(id):
res = Res()
res.id = id
return res
Select(from_list=[p], columns=[p.c.id], distinct=True).left_outer_join(TableB, on=(p.c.uid == TableB.poi_id)).where((TableB.type == 0) & (TableB.distance == 0)).bind(database).objects(resObject)
两种方式生成的SQL都是一样的:
SELECT DISTINCT `p`.`id` FROM
(SELECT `t1`.`id` AS `id`, `t1`.`uid` AS `uid` FROM `poi` AS `t1`
WHERE ((`t1`.`id` BETWEEN 100 AND 1000) AND (`t1`.`query_id` IS NULL))
ORDER BY `t1`.`id` LIMIT 100) AS `p`
LEFT OUTER JOIN `table_b` AS `t2` ON (`p`.`uid` = `t2`.`poi_id`)
WHERE ((`t2`.`type` = 0) AND (`t2`.`distance` = 0.0))
可以看到和我们想要的SQL是一样的。
相关API使用可以参考SelectQuery、BaseQuery、Select
参考文章
Python 常用的ORM框架简介
peewee的使用