InnoDB内部结构
在mysql数据库中,InnoDB存储引擎是最为常用和强大的存储引擎之一。了解InnoDB的内存结构对于优化数据库的性能,提高系统的稳定性和扩展性至关重要。本文将深入探讨InnoDB的内存结构。
1.Buffer Pool
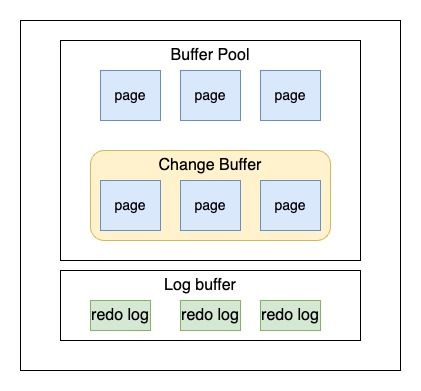
Buffer Pool: 缓冲池,其作用是用来缓存表数据和索引数据,可以看作是数据库的高速缓存,可以减少磁盘的I/O操作,提高数据库的访问性能。
Buffer Pool 由缓存数据页(Page)和 控制块组成,控制块中存储着对应缓存页所属的表空间,数据页的编号,以及对应缓存页在Buffer Pool中的地址等信息。
Buffer Pool的默认大小是128M,可以通过参数innodb_buffer_pool_size进行配置,一般来说,将buffer pool的大小设置为内存的50% - 80% 是一个比较合理的范围,具体的设置的大小,还是需要根据机器的情况和系统的资源来进行调整。
当进行查询数据的时候,innodb引擎会将磁盘中的数据页,进行缓存到Buffer Pool中。
2.page管理机制
page页可以根据状态分为三类
1.free page: 空闲页,未被使用的page
2.clean page: 被使用的page 数据没有被修改过
3.dirty page :脏页 被使用过,被修改过,并且与磁盘的数据产生了不一致
针对上面的这三种类型,Innodb通过三种链表来进行维护和管理
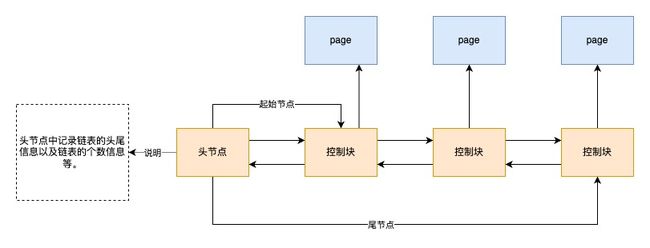
2.1free list
用于管理 free page,free list是一个链表,用于跟踪Buffer Pool中哪些页面是空闲的,即当前没有被用于缓存数据。当InnoDB需要一个新的页面来缓存数据时,它会从free list中取出一个页面。InnoDB会维护多个free list,通常是为了支持并发操作和提高性能。每个free list可能对应一个特定的内存区域或使用情况。
随着时间的推移,free list的大小会发生变化。当从磁盘读取一个新页面并将其放入Buffer Pool时,一个页面会从free list中移除。当从Buffer Pool中淘汰一个页面(例如,由于LRU(最近最少使用)策略)时,该页面会被添加到free list中。
从磁盘中进行加载页的流程:
1. 从free list 链表中进行获取一个空闲的控制块
2.把该缓存页对应的控制块信息填上
3. 把该缓存页对应的free链表的节点从链表中进行移除(因该缓存页已经被使用)
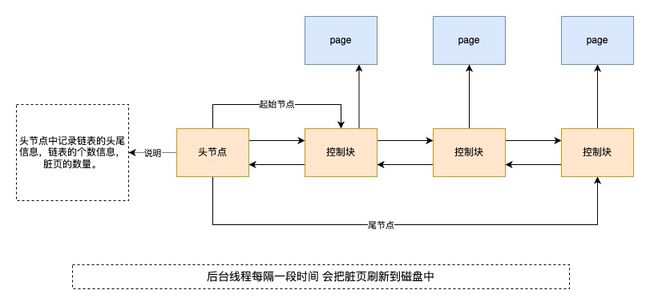
2.2 flush list
flush list是一个链表,用于管理dirty page,链表按照修改时间进行排序,InnoDB引擎为了提高处理效率,在每次进行修改缓存页,并不会立刻把修改的刷新到磁盘上,而是在未来的某个时间点进行刷新操作,所以用flush list链表存储脏页,凡是被修改过的缓存页对应的控制块都会作为节点添加到flush list链表中。
flush list链表与 free list 链表的结构相似。
2.3 LRU list
用于管理clean page 和dirty page,按照按照页面的访问时间进行排序,最近被访问的页面位于列表的前端,而最久未被访问的页面位于列表的尾端。
2.3.1 普通的LRU算法
普通的LRU算法:最近最少使用,即末尾淘汰法,新的数据从头部加入,释放空间的时候,从末尾淘汰。
1.当访问某个数据页时,如果不在Buffer Pool,就需要将该数据页加载到Buffer Pool中,并将该缓冲页对应的控制块作为节点添加到LRU链表的头部。
2.当访问某个数据页时,如果在Buffer Pool,则直接把该页对应的控制块移动到LRU链表的头部。
3.当需要进行释放空间的时,从最未尾进行淘汰。
普通LRU算法的优缺点
优点:
所有的最近使用的数据都会在表头,可以最大程度上保证热数据能被最快访问到。
缺点:
1. 如果发生全表扫描的时候,会把表中的所有的页加载到buffer pool中,就会将真正的热数据淘汰掉
2.mysql 存在预读机制(线性读:从磁盘加载数据到Buffer Pool中的时候,顺序访问某个区(一个区64个页)的页,超过了56个,会把整个区的数据进行加载到Buffer Pool;随机读: Buffer Pool的存储一个区的13个页,就将这个区的页数据 异步存储到buffer poll中。),很多预读的页也会放到LRU链表的头部,这样也会导致真正的热数据淘汰
2.3.2 改进后的LRU算法
改进后的LRU算法:链表分为两个区域,一个为冷数据区,一个为热数据区。加入数据的时候不再是从头部进行插入,而是从midPoint(中间位)插入,这个midPoint就是冷数据区的头部,如果这个数据很快会被访问的话,就会从冷数据区向热数据区进行移动,如果数据没有被访问,就会逐步向冷数据区尾部移动,等待淘汰。
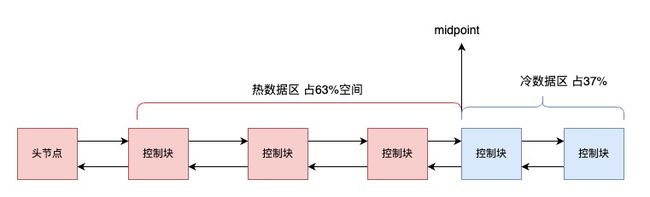
冷数据区的数据什么时候才会转移到热数据区呢
当一个数据页被加载到内存1000ms后,如果再次被访问,就会将其加入到热数据区的头部,这个时间可以通过参数innodb_old_blocks_time进行设置,默认值是1000,单位是ms.
对于热数据区,当他被访问的时候不是立刻就将其放到热数据区头部,而是会做一个判断其是否处于链表的前1/3,如果是,那就不会移动,如果处于后2/3的区域才会将其移动,因为每一次一定都会消耗CPU资源.
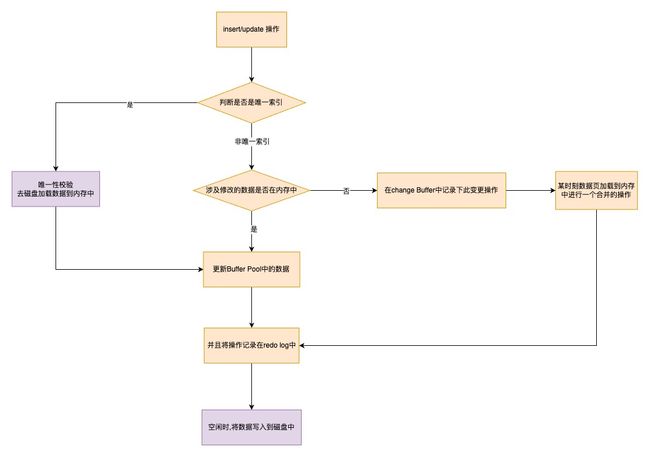
3.change Buffer
InnoDB的Change Buffer是MySQL中InnoDB存储引擎为了提高非唯一索引(通常指二级索引或辅助索引)操作性能而引入的一种机制。Change Buffer的大小可以通过参数innodb_change_buffer_max_size来动态设置,该参数表示Change Buffer最多可以占用Buffer Pool的百分比,默认占25%。
Change Buffer的工作原理:
1. 当InnoDB需要更新一个非唯一索引的数据页,但这个数据页并不在Buffer Pool中时,InnoDB不会直接从磁盘加载这个数据页到Buffer Pool中,而是将这些更改操作(如插入、更新或删除)缓存在Change Buffer中。这样做的目的是减少对磁盘的I/O操作,从而提高数据库的整体性能。
2.当这些被缓存的更改操作对应的数据页被其他读操作加载到Buffer Pool中时,这些更改操作会被合并到对应的数据页上。
3.当系统关闭、后台线程定期合并或Buffer Pool空间不足时,Change Buffer中的更改操作也会被合并到对应的数据页上。
Change Buffer为何只适用于非唯一索引:如果在索引设置唯一性,在进行修改时,InnoDB必须要做唯一性校验,因此必须查询磁盘,做一次IO操作。会直接将记录查询到BufferPool中,然后在缓冲池修改,不会在ChangeBuffer操作。
4.log buffer
log Buffer:日志缓冲区,也称为Redo Log Buffer,主要用于缓存redo log的写入操作。redo log是InnoDB用于保证事务持久性的物理日志,它记录了事务对数据库的更新操作。log Buffer的主要作用是缓存redo log的写入操作,从而减少对磁盘的直接I/O操作,提高数据库的性能。当事务发生时,相关的redo log记录首先被写入到log Buffer中,随后再按照一定的策略刷新到磁盘上的redo log文件中。
logBuffer的刷新策略:log Buffer中的内容并不是实时刷新到磁盘上的redo log文件中的,而是采用了一定的刷新策略。这种策略由相关的系统参数控制,如innodb_flush_log_at_trx_commit和innodb_flush_log_at_timeout等。当log Buffer已满或者达到一定的时间间隔时,其中的redo log记录会被刷新到磁盘上。