ASN.1探索 - 3 编码规则与传输语法(1 - BER)
转自: http://wmfbravo.blog.163.com/
感谢: wmfbravo
3 编码规则和传输语法
本章主要介绍BER和PER两种编码规则及其衍生规则。
3.1 BER
3.1.1 基本规则
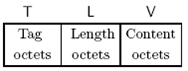
BER(Basic Encoding Rules)是ASN.1中最早定义的编码规则,在讨论详细编码规则时,我们是基于正确的抽象描述上。BER传输语法的格式一直是TLV三元组<Type, Length, Value>也可以认为是<Tag, Length, Value>,见Figure 3-1。TLV每个域都是一系列八位组,对于组合结构,其中V还可以是TLV三元组,见Figure 3-2。BER传输语法是基于八位组(为了避免不同系统上的混淆,没有采用Byte为单位)的,自定界的编码,因为其中L明确界定了八位组的长度。BER是大端编码的,其八位组的高位比特在左手边,见Figure 3-3。


BER编码中的Tag(通常是一个八位组),指明了值的类型,其中一个比特表征是基本类型还是组合类型。Tag有如下两种形式:
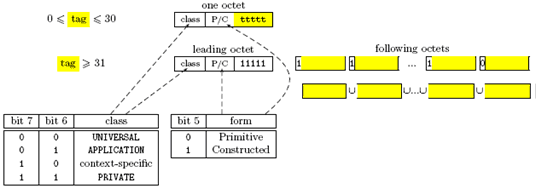
Figure 3-4 Tag的两种形式
当Tag不大于30时,Tag只在一个八位组中编码;当Tag大于30时,则Tag在多个八位组中编码。在多个八位组中编码时,第一个八位组后五位全部为1,其余的八位组最高位为1表示后续还有,为0表示Tag结束。Tag的值需要将上图中黄色部分拼接后才能得到。
BER编码中Length表示Value部分所占八位组的个数,有两大类:定长方式(Definite Form)和不定长方式(Indefinite Form);在确定方式中,按照Length所占的八位组个数又分为短、长两种形式。具体如下:
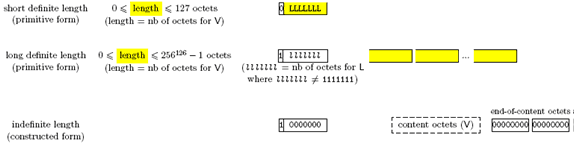
Figure 3-5 Length的三种形式
采用定长方式,当长度不大于127个八位组时,Length只在一个八位组中编码;当长度大于127时,在多个八位组中编码,此时第一个八位组低七位表示的是Length所占的长度,后续八位组表示Value的长度。
采用不定长方式时,Length所在八位组固定编码为0x80,但在Value编码结束后以两个0x00结尾。这种方式使得可以在编码没有完全结束的情况下,可以先发送部分消息给对方。
BER编码规则的Object Identifier注册为{joint-iso-itu-t(2) asn1(1) base-encoding(1)},其Object Description为“"Basic Encoding of a single ASN.1 type”。
3.1.2 各类型的编码
本小节中以UNIVERSAL Tag和短型Value为例,讨论各种类型的BER编码,重点关注Value部分。在举例中,n10表示数字n是十进制数。
I. BOOLEAN
只能以primitive方式编码。
FALSE的编码为:
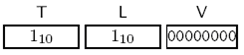
Figure 3-6 BOOLEAN: FALSE的编码
TRUE的编码(任何不是全0都可以)为:

或者:

Figure 3-7 BOOLEAN: TRUE的编码
II. NULL
只能以primitive方式编码,且只有一个值:

Figure 3-8 NULL的编码
III. INTEGER
只能以primitive方式编码。
我们分编、解码两个过程,正数、负数两种情况来讨论。
1) 编码过程:

Figure 3-9 INTEGER编码过程
l 对于正数,如果最高比特位为0则直接编码;如果为1,则在最高比特位之前增加一个全0的八位组。
l 对于负数,先取绝对值,再取反,最后加1。
2) 解码过程:
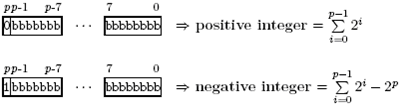
Figure 3-10 INTEGER解码过程
基于前面所述的规则,整数-27,066的编码为:

Figure 3-11 整数-27,066的编码
IV. ENUMERATED
ENUMERATED的值按照前面整数值的规则编码。
V. REAL
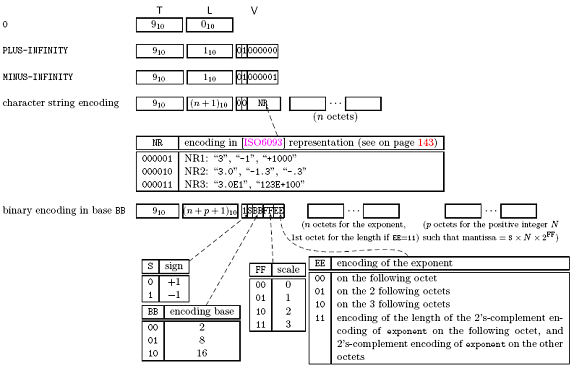
Figure 3-12 REAL类型编码
VI. BIT STRING
可以primitive方式编码或者constructed方式编码。
采用primitive方式,对'1011011101011'B的编码规则如下:

Figure 3-13 BIT STRING: '1011011101011'B的primitive form编码
注意在'1011011101011'B前增加了一个八位组,取值为0到7,表征这个值最后补位的个数。由发送方决定补位采用0还是1。
如果BIT STRING的值为空,则编码时,长度为1,补充的八位组为全0。
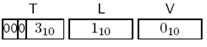
Figure 3-14 BIT STRING值为空的编码
constructed方式是在发送时,有部分编码还不能确定时采用的,前一个值的编码如下:
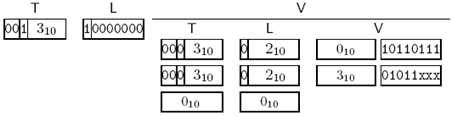
Figure 3-15 BIT STRING: '1011011101011'B的constructed form编码
注意Length部分采用的是不定长编码。
VII. OCTET STRING
与BIT STRING类似,但是不需要增加表征补充位个数的八位组。
VIII. OBJECT IDENTIFIER
只能以primitive方式编码。
编码时,第一个八位组采用公式:first_arc * 40+second_arc。
Table 3-1 OBJECT IDENGTIFIER第一个八位组解码

对{iso member-body f(250) type-org(1) ft(16) asn1-book(9)}的编码为:
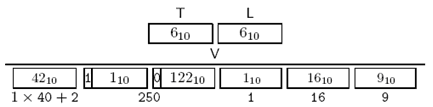
Figure 3-16 OBJECT IDENTIFIER编码示例
注意对250的编码方式。
IX. RELATIVE-OID
与OBJECT IDENTIFIER类似,但是不需要对注册树前两段进行特殊处理。对{f(250) type-org(1) ft(16) asn1-book(9)}的编码为:
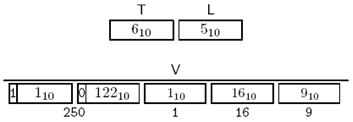
Figure 3-17 RELATIVE-OID编码示例
X. 字符串和日期
和OCTET STRING编码类似,只是Tag不同。
XI. SEQUENCE
肯定时constructed形式的。
在编码SEQUENCE时,其每个成员都要以TLV三元组方式编码,而且顺序要与SEQUENCE定义的一致。对于标记为DEFAULT的成员,即使发送方应用层给出了值,也是有发送者决定是否对该成员进行编码。
对如下定义:
v SEQUENCE { age INTEGER, single BOOLEAN } ::=
{ age 24, single TRUE }
的编码为:
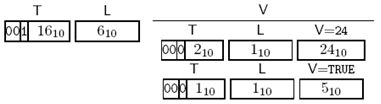
Figure 3-18 SEQUENCE编码示例
如果SEQUENCE定义中包括扩展符,则省略;如果有扩展的成员则编码。
XII. SET
与SEQUENCE类似,但是成员顺序有发送者决定。
XIII. SEQUENCE OF
SEQUENCE OF的Tag与SEQUENCE相同,编码规则也相同。
对定义为:
triplet SEQUENCE OF INTEGER ::= {2, 6, 5}
的编码为:
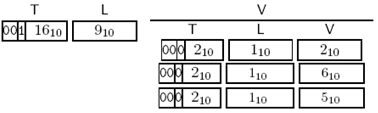
Figure 3-19 SEQUENCE OF编码示例
XIV. SET OF
与SEQUENCE OF类似。
XV. CHOICE
严格说CHOICE类型在编码中并不存在,只是在描述中体现一种关系。编码时,是按照具体被选择的成员编码规则编码的。
对定义为:
famous CHOICE { name VisibleString, nobody NULL } ::= name:"Perec"
的编码为:
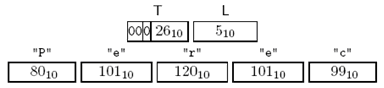
Figure 3-20 CHOICE编码示例
如果CHOICE类型显式(EXPLICIT)指定了Tag,那么该Tag应当以constructed方式编码,具体在XVI. 中讨论。
如果CHOICE类型包含有扩展符则忽略;如果有扩展成员则编码。
XVI. Tagged Value
如果一个类型的Tag是隐式(IMPLICIT)的(或者在模块定义中声明了IMPLICIT TAGS或者AUTOMATIC TAGS),则只有出现在关键字IMPLICIT左侧的Tag才会被编码。
如定义:
v [1] IMPLICIT INTEGER ::= -38
的编码为:

Figure 3-21 IMPLICIT TAG编码示例
如果一个类型的Tag是显式(EXPLICIT)的(或者在模块定义中声明了EXPLICIT TAGS),则要以constructed方式编码三元组系列。
如定义:
v [APPLICATION 0] EXPLICIT INTEGER ::= 38
的编码为:

Figure 3-22 EXPLICIT TAG编码示例
注意第一个Tag是APPLICTION、constructed方式,Length是后续八位组的长度。
XVII. 子类型约束
因为子类型约束是在BER编码规则之后被引入ASN.1的,所以在编码规则中不能体现约束。
XVIII. EXTERNAL
该类型不推荐使用,略。
XIX. INSTANCE OF
定义为:
v INSTANCE OF TYPE-IDENTIFIER ::=
{
type-id {iso member-body f(250) type-org(1) ft(16) asn1-book(9)
chapter18(5) integer-type(0)},
value INTEGER:5
}
的编码应当和如下一个SEQUENCE类型的值相同:
{ direct-reference {iso member-body f(250) type-org(1) ft(16) asn1-book(9)
chapter18(5) integer-type(0)},
encoding single-ASN1-type:INTEGER:5 }
编码为:
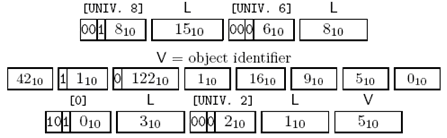
Figure 3-23 INSTANCE OF的编码示例
XX. EMBEDDED PDV
EMBEDDED PDV的编码和其等效的SEQUENCE结构编码类似。其嵌入部分的编码,应该是遵循identification成员指定的规则。
XXI. CHARACTER STRING
CHARACTER STRING的编码和其等效的SEQUENCE结构编码类似。其嵌入字符串部分的编码,应该是遵循identification成员指定的规则。
XXII. Information Objects and Object Sets
信息对象和对象集合永远都不编码。如前所述,传递他们所包含信息的途径是在值定义或者类型定义中引用他们。这样的结果,不是在编码中出现了这些信息,而是ASN.1编译器在生成编解码器时,会按照这些信息生成相应的约束表。
XXIII. Value Set
值集合的编码按照对应类型的编码规则进行。
3.1.3 BER编码规则的属性
l BER编码规则是机器无关的:通讯应用可以很容易支持大端和这种编码格式;而且能支持各种不同的整数长度。
l BER的传输语法是十分冗长的:T和L很多情况下都是可以省略的,但是这种冗余信息一些情况下也有显著的优势,它能很好的保藏抽象语法结构,BER传输语法能容易升级而且向上兼容。如每个类型都可以用CHOICE来代替:
T ::= IA5String -- old version
可以更新为:
T ::= CHOICE {
iA5String IA5String,
universalString UniversalString } -- new version
当旧的解码器收到universalString时,它可以明确知道收到的不是iA5String,而且知道具体长度,可以很容易忽略这个信元。
在此基础上,可以看出,BER规则中SEQUENCE、SET都是缺省可扩展的。另外,对ENUMERATED,BER也没有对边界进行限定,因此也是可扩展的。
当整个抽象语法都是显式(EXPLICIT)Tag时,解码器能在不了解具体抽象语法的情况下解码,能以更为用户友好的方式展示结果。如对BOOLEAN类型显示为“TRUE”或者“FALSE”而不是码字。
置于长度,如果系统性的使用长度,可以根据使用情况更为有效传递,而不用严格传输诸如SIZE(200)。
当然,BER的优势在某些方面也成了不足之处,这也导致了其它编码规则的产生。
3.1.4 一个完整的例子
这里,以一个HTTP的片段作为示例:
MyHTTP DEFINITIONS AUTOMATIC TAGS ::=
BEGIN
GetRequest ::= SEQUENCE
{
header-only BOOLEAN,
lock BOOLEAN,
accept-types AcceptTypes,
url Url,
...
}
AcceptTypes ::= SET
{
standards BIT STRING {html(0), plain-text(1), gif(2),
jpeg(3)} (SIZE (4)) OPTIONAL,
others SEQUENCE OF VisibleString (SIZE (4))
OPTIONAL
}
Url ::= VisibleString (FROM ("a".."z"|"A".."Z"|"0".."9"|"./-_~%#"))
v GetRequest ::=
{
header-only TRUE,
lock FALSE,
accept-types { standards {html,plain-text} },
url "www.asn1.com"
}
END
值v对应的BER编码结果为:
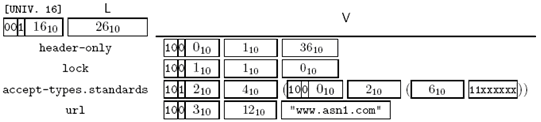
Figure 3-24 BER编码示例