Lucene.Net 简介
Lucene 简介
Lucene 能够为文本类型的数据建立索引,所以你只要能把你要索引的数据格式转化的文本的,Lucene 就能对你的文档进行索引和搜索。比如你要对一些 HTML 文档,PDF 文档进行索引的话你就首先需要把 HTML 文档和 PDF 文档转化成文本格式的,然后将转化后的内容交给 Lucene 进行索引,然后把创建好的索引文件保存到磁盘或者内存中,最后根据用户输入的查询条件在索引文件上进行查询。
图 1 表示了搜索应用程序和 Lucene 之间的关系,也反映了利用 Lucene 构建搜索应用程序的流程: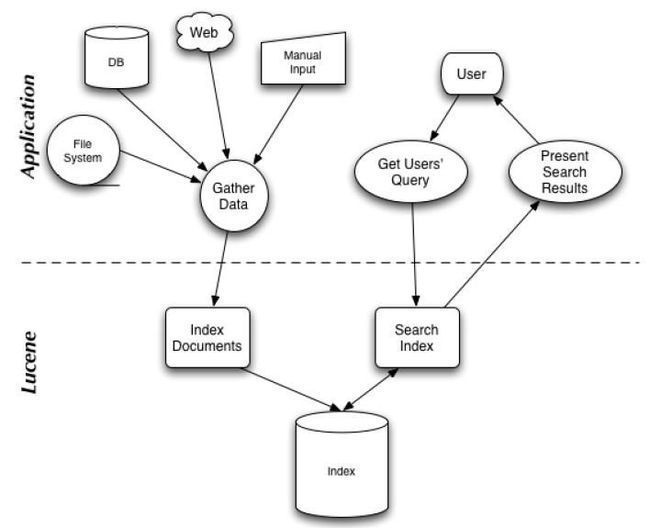
索引和搜索
索引是现代搜索引擎的核心,建立索引的过程就是把源数据处理成非常方便查询的索引文件的过程。
为什么索引这么重要呢?试想你现在要在大量的文档中搜索含有某个关键词的文档,那么如果不建立索引的话你就需要把这些文档顺序的读入内存,然后检查这个文章中是不是含有要查找的关键词,这样的话就会耗费非常多的时间,想想搜索引擎可是在毫秒级的时间内查找出要搜索的结果的。这就是由于建立了索引的原因,你可以把索引想象成这样一种数据结构,他能够使你快速的随机访问存储在索引中的关键词,进而找到该关键词所关联的文档。
Lucene 采用的是一种称为反向索引(inverted index)的机制。反向索引就是说我们维护了一个词/短语表,对于这个表中的每个词/短语,都有一个链表描述了有哪些文档包含了这个词/短语。这样在用户输入查询条件的时候,就能非常快的得到搜索结果。
由于 Lucene 提供了简单易用的 API,所以即使读者刚开始对全文本进行索引的机制并不太了解,也可以非常容易的使用 Lucene 对你的文档实现索引。
对文档建立好索引后,就可以在这些索引上面进行搜索了。搜索引擎首先会对搜索的关键词进行解析,然后再在建立好的索引上面进行查找,最终返回和用户输入的关键词相关联的文档。
Lucene 命名空间分析
命名空间: Lucene.Net.Documents
这个命名空间提供了一些为封装要索引的文档所需要的类,比如 Document, Field。
这样,每一个文档最终被封装成了一个 Document 对象。
命名空间: Lucene.Net.Analysis
这个命名空间主要功能是对文档进行分词,因为文档在建立索引之前必须要进行分词,所以这个包的作用可以看成是为建立索引做准备工作。
命名空间: Lucene.Net.Index
这个命名空间提供了一些类来协助创建索引以及对创建好的索引进行更新。这里面有两个基础的类:IndexWriter 和 IndexReader,其中 IndexWriter 是用来创建索引并添加文档到索引中的,IndexReader 是用来删除索引中的文档的。
命名空间: Lucene.Net.Search
这个命名空间提供了对在建立好的索引上进行搜索所需要的类。比如 IndexSearcher 和 Hits, IndexSearcher 定义了在指定的索引上进行搜索的方法,Hits 用来保存搜索得到的结果。