大话编程(二)
2013年1月15日 12:45:13
上次说道数据类型和控制语句.
我们在数学几何中学过,点,线,面
多个点组成线,多条线组成面,多个面组成体
在(一)中的说的那个抽象出0,1的电路,在编程中可以看作是"点线面"中的'点',名字叫bit(比特)
8个这样的'点'并排放在一起就成了一条线段了,多条'同样长度'的线段组合在一起就成了面:
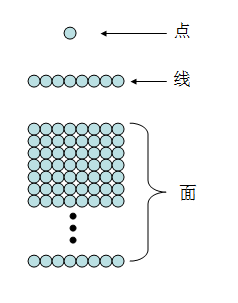
其中,这个长度为8bit的线段,又叫一个'字节'(Byte),这就是书上说的一种常见的基本数据类型'char'(字符型)的结构了
(以下没明确说明都是指c语言)
下边根据'点线面'的知识讲讲数据类型:
编程语言中有一种基本数据类型叫字符型(char),它的本质就是8个这样的'点'组成的结构(嗯,如果你愿意,只要是由两个这样的'点'以上组成的结构都可以叫做数据结构)
好规律来了:
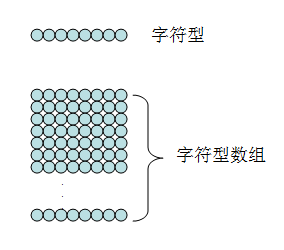

好,字符型-字符数组;整形-整形数组;浮点型-浮点型数组;每当你遇到一种基本数据类型(线),把它重复几次就叫做什么什么数组了(面)
55AA55AA55AA55AA55AA55AA55AA55AA55AA55AA55AA55AA55AA55AA55AA55AA55AA55AA55AA55AA
2013年7月9日 10:27:29
数据类型的本质就是告诉编译器:你在知道标识符在内存中的首地址的情况下,一次取多长就能够把该变量取完
所以一种数据类型必须要保存该类型的长度,不论它是基本数据类型(int,char...)还是复杂数据类型(Sting,class...)
另外,讲讲编码:
这8个点每个点有0和1两种状态,那么会有2^8=256种排列组合,可以表示256种字符
先看看ascii码(美国国际交换码):它是用来描述英文字符(a-z),阿拉伯数字(0-9),以及一些其它美国人用到字符的,数目是127个
对美国人来说,这8bit已经足够了,因为计算机是美国人发明的嘛,
但是随着发展,要想在计算机显示器上显示其它国家的文字怎么办呢?
比如说汉字,常用的就几千个了,8个bit的排列组合数根本不够,那么中国人要自己编码,当然个数就超过8了,但仍然是8的倍数,16或24或32等等
如国标系列GBK,GB2312等等(区别在于排列组合对应汉字的个数不同,有的只有简体中文,有的还包括了繁体中文,藏文等等)
那其它国家呢,也要用计算机显示自己的文字,这就乱套了,出现了乱码(他们都兼容美国人的编码,一般没发现英文和数字出现乱码的),
因为一个国家的编码可以保证自己的每一个排列组合只对应一个文字,但不同国家之间的编码,同一种排列组合的bit串,可能对应两种不同的语言中的不同的文字,在同一台计算机上显示时就乱码了
这时,就出来了一种以utf开头的编码方式,它提供一种编码规则,任何国家只要按这种规则编的码(排列组合),就不会和其它国家的编码冲突
我们常用的就是utf-8这种规则