《windows核心编程系列》二谈谈ANSI和Unicode字符集 .
http://blog.csdn.net/ithzhang/article/details/7916732转载请注明出处!!
第二章:字符和字符串处理
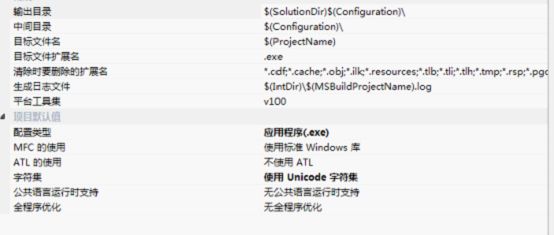
使用vc编程时项目--》属性--》常规栏下我们可以设置项目字符集合,它可以是ANSI(多字节)字符集,也可以是unicode字符集。一般情况下说Unicode都是指UTF-16。也就是说每个字符编码为两个字节。65535个字符可以表示世界上大部分的语言。为了软件使国际化大家再编程时应该使用unicode字符集。由于原来学过c语言,不习惯使用Unicode,为了省事而直接在配置属性里调为多字节字符集,这是个不好的习惯。C语言的字符串,以及对这些字符串操作的函数都是不安全的。很容易导致缓冲区溢出错误,有时这会导致很严重的后果。所以极力建议大家要使用Unicode字符串,对它们进行的操作要使用接下来将要介绍的安全字符串函数。除此之外这对于提高性能也有帮助,因为现在大部分的windowsAPI都是直接对Unicode字符串进行操作,你所传入的多字节字符串会先转换为Unicode后再拿来使用。直接使用Unicode省略了转换的步骤,当然具有更高的性能。
C语言定义字符时使用的char类型,表示一个8位ANSI字符。
在vc中,microsoft定义了一个内置的数据类型wchar_t,它表示一个16位的Unicode字符。它是通过下面的语句定义的:
typedef unsigned short wchar_t;
很明显它占16位。定义Unicode字符与ANSI类似。如:
wchar_t a=L'a';
wchar_t array[100]=L"Hello world!!!";
对于array数组,它的每个字符都占16位且是以16位的\0结尾。
字符和字符串前的L是一个宏。它通知编译器应该将其编译为Unicode字符串。当编译器将此字符串放入程序的数据段时,会使用UTF-16来编码每个字符。
刚开始接触windows开发的同学会对windows提供的各种内置类型不知所措。其实这是windows为了显示出自己的与众不同将原来大家熟悉的c语言的内置类型起个别名罢了。如
typedef char CHAR;
typedef wchar_t WCHAR;
typedef CHAR *PCHAR;
typedef CHAR *PSTR;
typedef COSNT CHAR *PCSTR;
typedef WCHAR *PWCHAR;
typedef WCHAR *PWSTR;
typedef COSNT WCHAR *PCWSTR;
其实使用哪种数据类型并不重要,关键是能保持一致性。不要混合使用。如果是windows程序员最好能与windows保持一致。这可以增强代码的可读性。
为什么编译器能根据我们的设置自动为我们选择字符集呢。原来在本章开始时当我们选择使用Unicode字符集时,编译器会为我们在源文件中定义Unicode。形如#define Unicode。如果选择使用多字节字符集时会将定义Unicode的语句注释掉。为什么仅仅使用一句话就可以有这么大改变呢。请接着往下看:
#define UNICODE
typedef WCHAR TCHAR,*PTCHAR , PTSTR;
typedef COSNT WCHAR *PCTSTR;
#define _TEXT(quote) L##quote
#else
typedef CHAR TCHAR ,*PTCHAR,PTSTR;
typedef CONST CHAR *PCTSTR;
#define _TEXT(quote) quote
#endif
#define TEXT(quote) _TEXT(quote)
原来编译器使用预编译宏来进行判断,如果定义了UNICODE,就会将WCHAR定义为TCHAR,在_TEXT,在TEXT的参数前加上L。否则将TCHAR定义为CHAR,TEXT,_TEXT的参数前没有添加任何东西。明白了这些我们就应该清楚如何写出兼容性强的代码,也就是说让我们的代码在Unicode或是多字节字符集下都可以成功运行。或许你应经看出来了,使用TCHAR和TEXT。如:
TCHAR c=TEXT('a');
TCHAR array[100]=TEXT("Hello world!");
编译器会根据我们的设置,编译成不同的代码。在Unicode环境下,由于定义了UNICODE上述宏经过展开后会生成以下代码:
WCHAR c=L'a';
WCHAR array=L"Hello world!";
而在ANSI字符集下会生成这样的代码:
CHAR c='a';
CHAR array="Hello world!";
能看懂上述宏定义很重要,因为在vc中我们使用的DEBUG和RELEASE模式就是使用上述方法轻松转换的。当我们选择DEBUG模式时编译器会在源代码中定义_DEBUG。RELEASE模式时会定义NDEBUG。预编译指令会对上述定义进行判断,根据定义的不同生成不同的代码。对上述宏不懂得同学可以找下介绍宏的资料来看,宏参数、宏展开什么的。
正如前面介绍的,现在的windows版本内部处理字符串都是使用Unicode字符集,调用windows函数时如果传入的是一个ANSI字符串,函数首先会执行转换操作,将ANSI字符串转换为Unicode字符串。
如果一个windows函数参数列表中存在字符串,它通常有两个版本。一个接受Unicode字符串另一个接受ANSI字符串。比如大家比较熟悉的MessageBox,它就有两个版本,一个是MessageBoxA,处理ANSI字符串另一个是MessageBoxW用以处理Unicode字符串。既然MessageBox有两个版本为什么平时我们使用时只需要使用MessageBox就行了。这个还是跟宏定义有关。在windows提供的头文件中有这样一句话:
#ifdef UNICODE
#define MessageBox MessageBoxW
#else
#define MessageBox MessageBoxA
#endif
有了上面的介绍是不是这句话很容易的就看出来了。对了,MessageBox并不是真正的函数,它仅仅是一个宏罢了。根据是否定义UNICODE决定在源文件中使用哪个函数。很多函数都存在这样的情况。这也是很多新手在逆向工程函数拦截时使用如MessageBox却一无所获的原因。
当我们使用ANSI字符集时,UNICODE不会被定义,真正使用的是MessageBoxA函数,该函数首先执行将ANSI字符串转换为Unicode,然后再调用MessageBoxW函数。W版本返回的字符串也要先转换成ANSI字符串才被能被使用。与直接使用W版本相比这当然性能更低。
Windows的这种做法很好的兼容了Unicode和ANSI。可以考虑在我们自己的程序中使用这种方法。比如导出dll时,可以考虑导出两个函数一个ASNI版本,一个Unicode版本。ANSI版本仅执行字符串转换操作之后调用Unicode版本的函数。
以上介绍的都是windows系统处理Unicode和ANSI字符集的方法。作为一门语言C语言也提供了自己处理它们的机制。C运行库也提供了不同的函数处理不同的字符集,但是与windows不同的是c运行库的ANSI版本的函数不会在内部调用Unicode版本的函数。
如strlen用于处理ANSI字符集,返回字符串长度,与之对应的Unicode版本为wcslen。(wide character set)。
C语言提供的对字符串进行修改的函数存在安全隐患,容易造成缓冲区溢出。轻则结果错误,重则系统崩溃。因为它们对目标缓冲区进行操作时没有收到指定缓冲区的最大长度的参数,函数并不知道自己会破坏内存。Microsoft提供了一些新的安全的函数来取代C运行库不安全的字符串处理函数。虽然我们已经习惯使用strcpy,printf,strcat等这些函数,但是我们还是去要忘记它们,转而使用windows提供的这些的新的更安全的函数。所有要使用安全的函数程序必须包含StrSafe.h头文件。现有的每一个函数,如strcpy,_tcscpy都有一个对应的安全新版本函数,strcpy_s,_tcscpy_s。前面的名称相同但最后添加了一个_s,代表更安全。如老版本的函数的区别是它们需要目标缓冲区的大小。注意不是字符串所占的字节数,而是字符数,无论是ANSI字符还是Unicode字符集都可以使用宏_countof来得到字符数(使用sizeof不行哦,它返回字节数)。如果目标缓冲区不足以容纳结果数据,函数就会设置局部于线程的C运行时变量errno。然后返回一个errno_t值来指出成功或失败。关于安全函数仅仅介绍这么多,一者《windows核心编程》中关于此介绍的很简单且晦涩难懂。二者平时我们在开发时很少能够用到,只要知道每个对应的c字符串操作函数都对应着一个安全函数,用时再查也不迟。
现在再也不能将字符认为仅仅占一个字节了,因为存在Unicode的字符。要表示字节可以使用BYTE。建议平时使用通用的数据类型如TCHAR,PTSTR定义变量。同时将字符或字符串用TEXT或_T包括起来。
涉及到ANSI和Unicode字符集的转换可以使用以下两个函数:
MultiByteToWideChar和WideCharToMultiByte。
判断字符串是Unicode还是ANSI字符集可以使用函数IsTextUnicode。