Linux网络设备驱动架構學習(三)
Linux网络设备驱动架構學習(三)
接下來會從以下幾個方面介紹網絡設備驅動的編寫流程:
1、網絡設備的註冊與註銷
2、網絡設備的初始化
3、網絡設備的打開與釋放
4、網絡數據發送流程
5、網絡數據接收流程
6、網絡連接狀態
7、網絡參數設置和統計數據
瞭解了這幾部份內容,網絡設備驅動的編寫方法也就基本明白了
網絡數據發送流程
Linux 网络子系统在发送数据包时,会调用驱动程序提供的 hard_start_transmit()函数,该函数用于启动数据包的发送。在设备初始化的时候,这个函数指针需被初始化指向设备的 xxx_tx()函数。
网络设备驱动完成数据包发送的流程如下。
(1)网络设备驱动程序从上层协议传递过来的 sk_buff 参数获得数据包的有效数据和长度,将有效数据放入临时缓冲区。
(2)对于以太网,如果有效数据的长度小于以太网冲突检测所要求数据帧的最小长度 ETH_ZLEN,则给临时缓冲区的末尾填充 0。
(3)设置硬件的寄存器,驱使网络设备进行数据发送操作。
完成以上 3 个步骤的网络设备驱动程序的数据包发送函数的模板如代码清单所示。
1 int xxx_tx(struct sk_buff *skb, struct net_device *dev)
2 {
3 int len;
4 char *data, shortpkt[ETH_ZLEN];
5 /* 获得有效数据指针和长度 */
6 data = skb->data;
7 len = skb->len;
8 if (len < ETH_ZLEN)
9 {
10 /* 如果帧长小于以太网帧最小长度,补 0 */
11 memset(shortpkt, 0, ETH_ZLEN);
12 memcpy(shortpkt, skb->data, skb->len);
13 len = ETH_ZLEN;
14 data = shortpkt;
15 }
16
17 dev->trans_start = jiffies; /* 记录发送时间戳 */
18
19 /* 设置硬件寄存器让硬件把数据包发送出去 */
20 xxx_hw_tx(data, len, dev);
21 ...
22 }
当数据传输超时时,意味着当前的发送操作失败,此时,数据包发送超时处理函数 xxx_tx_ timeout()将被调用。这个函数需要调用 Linux 内核提供的 netif_wake_queue()函数重新启动设备发送队列,如代码清单所示。
1 void xxx_tx_timeout(struct net_device *dev)
2 {
3 ...
4 netif_wake_queue(dev); /* 重新启动设备发送队列 */
5 }
網絡數據接收流程
网络设备接收数据的主要方法是由中断引发设备的中断处理函数,中断处理函数判断中断类型,如果为接收中断,则读取接收到的数据,分配 sk_buffer 数据结构和数据缓冲区,将接收到的数据复制到数据缓冲区,并调用 netif_rx()函数将 sk_buffer 传递给上层协议。代码清单所示为完成这一过程的函数模板。
1 static void xxx_interrupt(int irq, void *dev_id, struct pt_regs *regs)
2 {
3 ...
4 switch (status &ISQ_EVENT_MASK)
5 {
6 case ISQ_RECEIVER_EVENT:
7 /* 获取数据包 */
8 xxx_rx(dev);
9 break;
10 /* 其他类型的中断 */
11 }
12 }
13 static void xxx_rx(struct xxx_device *dev)
14 {
15 ...
16 length = get_rev_len (...);
17 /* 分配新的套接字缓冲区 */
18 skb = dev_alloc_skb(length + 2);
19
20 skb_reserve(skb, 2); /* 对齐 */
21 skb->dev = dev;
22
23 /* 读取硬件上接收到的数据 */
24 insw(ioaddr + RX_FRAME_PORT, skb_put(skb, length), length >> 1);
25 if (length &1)
26 skb->data[length - 1] = inw(ioaddr + RX_FRAME_PORT);
27
28 /* 获取上层协议类型 */
29 skb->protocol = eth_type_trans(skb, dev);
30
31 /* 把数据包交给上层 */
32 netif_rx(skb);
33
34 /* 记录接收时间戳 */
35 dev->last_rx = jiffies;
36 ...
37 }
从上述代码的第 4~7 行可以看出,当设备的中断处理程序判断中断类型为数据包接收中断时,它调用第 13~37 定义的 xxx_rx()函数完成更深入的数据包接收工作。 xxx_rx()函数代码中的第 16 行从硬件读取到接收数据包有效数据的长度,第 17~20 行分配 sk_buff 和数据缓冲区,第 23~26 行读取硬件上接收到的数据并放入数据缓冲区,第 28~29 行解析接收数据包上层协议的类型,最后,第 31~32 行代码将数据包上交给上层协议。
如果是 NAPI 兼容的设备驱动,则可以通过 poll 方式接收数据包。这种情况下,我们需要为该设备驱动提供 xxx_poll()函数,如代码清单所示。
1 static int xxx_poll(struct net_device *dev, int *budget)
2 {
3 int npackets = 0, quota = min(dev->quota, *budget);
4 struct sk_buff *skb;
5 struct xxx_priv *priv = netdev_priv(dev);
6 struct xxx_packet *pkt;
7
8 while (npackets < quota && priv->rx_queue)
9 {
10 /*从队列中取出数据包*/
11 pkt = xxx_dequeue_buf(dev);
12
13 /*接下来的处理,和中断触发的数据包接收一致*/
14 skb = dev_alloc_skb(pkt->datalen + 2);
15 if (!skb)
16 {
17 ...
18 continue;
19 }
20 skb_reserve(skb, 2);
21 memcpy(skb_put(skb, pkt->datalen), pkt->data, pkt->datalen);
22 skb->dev = dev;
23 skb->protocol = eth_type_trans(skb, dev);
24 /*调用 netif_receive_skb 而不是 net_rx 将数据包交给上层协议*/
25 netif_receive_skb(skb);
26
27 /*更改统计数据 */
28 priv->stats.rx_packets++;
29 priv->stats.rx_bytes += pkt->datalen;
30 xxx_release_buffer(pkt);
31 }
32 /* 处理完所有数据包*/
33 *budget -= npackets;
34 dev->quota -= npackets;
35
36 if (!priv->rx_queue)
37 {
38 netif_rx_complete(dev);
39 xxx_enable_rx_int ( … ); /* 再次使能网络设备的接收中断 */
40 return 0;
41 }
42
43 return 1;
44 }
上述代码第 3 行中的 dev->quota 是当前 CPU 能够从所有接口中接收数据包的最大数目,budget 是在初始化阶段分配给接口的 weight 值,poll 函数必须接收两者之间的最小值,表示轮询函数本次要处理的数据包个数。第 8 行的 while()循环读取设备的接收缓冲区,读取数据包并提交给上层。这个过程和中断触发的数据包接收过程一致,但是最后使用 netif_receive_skb()函数而非 netif_rx()函数将数据包提交给上层。这里体
现出了中断处理机制和轮询机制之间的差别。
当网络设备接收缓冲区中的数据包都被读取完后(即 priv->rx_queue 为 NULL),一个轮询过程结束,第 38 行代码调用 netif_rx_complete()把当前指定的设备从 poll 队列中清除,第 39 行代码再次启动网络设备的接收中断。 虽然 NAPI 兼容的设备驱动以 poll 方式接收数据包,但是仍然需要首次数据包接收中断来触发 poll 过程。与数据包的中断接收方式不同的是,以轮询方式接收数据包时,当第一次中断发生后,中断处理程序要禁止设备的数据包接收中断,如代码清单所示。
1 static void xxx_poll_interrupt(int irq, void *dev_id, struct pt_regs *regs)
2 {
3 switch (status &ISQ_EVENT_MASK)
4 {
5 case ISQ_RECEIVER_EVENT:
6 … /* 获取数据包 */
7 xxx_disable_rx_int(...); /* 禁止接收中断 */
8 netif_rx_schedule(dev);
9 break;
10 … /* 其他类型的中断 */
11 }
12 }
上述代码第 8 行的 netif_rx_schedule()函数被轮询方式驱动的中断程序调用,将设备的 poll 方法添加到网络层的 poll 处理队列中,排队并且准备接收数据包,最终触发一个 NET_RX_SOFTIRQ 软中断,通知网络层接收数据包。下图所示为 NAPI 驱动程序各部分的调用关系。
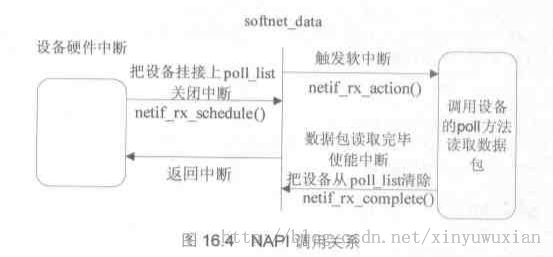
網絡連接狀態
网络适配器硬件电路可以检测出链路上是否有载波,载波反映了网络的连接是否正常。网络设备驱动可以通过 netif_carrier_on()和 netif_carrier_off()函数改变设备的连接状态 , 如果驱动檢測到连接状态发生变化,也应该以netif_carrier_on()和netif_carrier_off()函数显式地通知内核。 除了 netif_carrier_on()和 netif_carrier_off()函数以外,另一个函数 netif_carrier_ok()可用于向调用者返回链路上的载波信号是否存在。 这几个函数都接收一个 net_device 设备结构体指针为参数,原型分别为:
void netif_carrier_on(struct net_device *dev);
void netif_carrier_off(struct net_device *dev);
int netif_carrier_ok(struct net_device *dev);
网络设备驱动程序中往往设置一个定时器来对链路状态进行周期性地检查。当定时器到期之后,在定时器处理函数中读取物理设备的相关寄存器获得载波状态,从而更新设备的连接状态,如代码清单所示。
1 static void xxx_timer(unsigned long data)
2 {
3 struct net_device *dev = (struct net_device*)data;
4 u16 link;
5 …
6 if (!(dev->flags &IFF_UP))
7 {
8 goto set_timer;
9 }
10
11 /* 获得物理上的连接状态 */
12 if (link = xxx_chk_link(dev))
13 {
14 if (!(dev->flags &IFF_RUNNING))
15 {
16 netif_carrier_on(dev);
17 dev->flags |= IFF_RUNNING;
18 printk(KERN_DEBUG "%s: link up\n", dev->name);
19 }
20 }
21 else
22 {
23 if (dev->flags &IFF_RUNNING)
24 {
25 netif_carrier_off(dev);
26 dev->flags &= ~IFF_RUNNING;
27 printk(KERN_DEBUG "%s: link down\n", dev->name);
28 }
29 }
30
31 set_timer:
32 priv->timer.expires = jiffies + 1 * HZ;
33 priv->timer.data = (unsigned long)dev;
34 priv->timer.function = &xxx_timer; /* timer handler */
35 add_timer(&priv->timer);
36 }
上述代码第 12 行调用的 xxx_chk_link()函数用于读取网络适配器硬件的相关寄存器以获得链路连接状态,具体实现由硬件决定。当链路连接上时,第 16 行的netif_carrier_on()函数显式地通知内核链路正常;反之,则第 25 行的 netif_carrier_off()则同样显式地通知内核链路失去连接。 此外,从上述源代码还可以看出,定时器处理函数会不停地利用第 31~35 行代码启动新的定时器以实现周期检测的目的。那么最初启动定时器的地方在哪里呢?很显然,它最适合在设备的打开函数中完成,如代码清单所示。
1 static int xxx_open(struct net_device *dev)
2 {
3 struct xxx_priv *priv = (struct xxx_priv*)dev->priv;
4
5 ...
6 priv->timer.expires = jiffies + 3 * HZ;
7 priv->timer.data = (unsigned long)dev;
8 priv->timer.function = &xxx_timer; /* timer handler */
9 add_timer(&priv->timer);
10 ...
11 }
網絡參數設置和統計數據
在网络设备的驱动程序中还提供一些方法供系统对设备的参数进行设置或读取设备相关的信息。 当用户调用 ioctl()函数,并指定 SIOCSIFHWADDR 命令时,意味着要设置这个设备的 MAC 地址。一般来说,这个操作没有太大的意义。设置网络设备的 MAC 地址可用如代码清单所示的模板。
1 static int set_mac_address(struct net_device *dev, void *addr)
2 {
3 if (netif_running(dev))
4 return -EBUSY; /* 设备忙 */
5
6 /* 设置以太网的 MAC 地址 */
7 xxx_set_ mac(dev, addr);
8
9 return 0;
10 }
上述程序首先用 netif_running()宏判断设备是否正在运行,如果是,则意味着设备忙,此时不允许设置 MAC 地址;否则,调用 xxx_set_ mac()函数在网络适配器硬件内写入新的 MAC 地址。这要求设备在硬件上支持 MAC 地址的修改,而实际上,许多设备并不提供修改 MAC 地址的接口。
netif_running()宏的定义为:
#define netif_running(dev) (dev->flags & IFF_UP)
当用户调用 ioctl()函数时,若命令为 SIOCSIFMAP(如在控制台中运行网络配置命令 ifconfig 就会引发这一调用),系统会调用驱动程序的 set_config()函数。 系统会向 set_config()函数传递一个 ifmap 结构体,该结构体中主要包含用户欲设置的设备要使用的 I/O 地址、中断等信息。注意,并非 ifmap 结构体中给出的所有修改都是可以被接受的。实际上,大多数设备并不宜包含 set_config()函数。set_config()函数的例子如代码清单 所示。
1 int xxx_config(struct net_device *dev, struct ifmap *map)
2 {
3 if (netif_running(dev)) /* 不能设置一个正在运行状态的设备 */
4 return - EBUSY;
5
6 /* 假设不允许改变 I/O 地址 */
7 if (map->base_addr != dev->base_addr)
8 {
9 printk(KERN_WARNING "xxx: Can't change I/O address\n");
10 return - EOPNOTSUPP;
11 }
12
13 /* 假设允许改变 IRQ */
14 if (map->irq != dev->irq)
15 {
16 dev->irq = map->irq;
17 }
18
19 return 0;
20 }
上述代码中的 set_config()函数接受 IRQ 的修改,拒绝设备 I/O 地址的修改。具体的设备是否接收这些信息的修改,要视硬件的设计而定。 如 果 用 户 调 用 ioctl() 时 , 命 令 类 型 在 SIOCDEVPRIVATE 和SIOCDEVPRIVATE+15 之间,系统会调用驱动程序的 do_ioctl()函数,进行设备专用数据的设置。这个设置大多数情况下也并不需要。 驱动程序还应提供 get_stats()函数用以向用户反馈设备状态和统计信息,该函数返回的是一个 net_device_stats 结构体,如代码清单所示。
1 struct net_device_stats *xxx_stats(struct net_device *dev)
2 {
3 struct xxx_priv *priv = netdev_priv(dev);
4 return &priv->stats;
5 }
net_device_stats 结构体定义在内核的 include/linux/netdevice.h 文件中,它包含了比较完整的统计信息,如代码清单所示。
1 struct net_device_stats
2 {
3 unsigned long rx_packets; /* 收到的数据包数 */
4 unsigned long tx_packets; /* 发送的数据包数 */
5 unsigned long rx_bytes; /* 收到的字节数 */
6 unsigned long tx_bytes; /* 发送的字节数 */
7 unsigned long rx_errors; /* 收到的错误数据包数 */
8 unsigned long tx_errors; /* 发生发送错误的数据包数 */
9 ...
10 };
上述代码清单只是列出了 net_device_stats 包含的主项目统计信息,实际上,这些项目还可以进一步细分,net_device_stats 中的其他信息给出了更详细的子项目统计,详见 Linux 源代码。
net_device_stats 结构体适宜包含在设备的私有信息结构体中,而其中统计信息的修改则应该在设备驱动的与发送和接收相关的具体函数中完成,这些函数包括中断处理程序、数据包发送函数、数据包发送超时函数和数据包接收相关函数等。我们应该在这些函数中添加相应的代码,如代码清单所示。
1 /* 发送超时函数 */
2 void xxx_tx_timeout(struct net_device *dev)
3 {
4 struct xxx_priv *priv = netdev_priv(dev);
5 ...
6 priv->stats.tx_errors++; /* 发送错误包数加 1 */
7 ...
8 }
9
10 /* 中断处理函数 */
11 static void xxx_interrupt(int irq, void *dev_id, struct pt_regs *regs)
12 {
13 switch (status &ISQ_EVENT_MASK)
14 {
15 ...
16 case ISQ_TRANSMITTER_EVENT: /
17 priv->stats.tx_packets++; /* 数据包发送成功,tx_packets 信息加1 */
18 netif_wake_queue(dev); /* 通知上层协议 */
19 if ((status &(TX_OK | TX_LOST_CRS | TX_SQE_ERROR |
20 TX_LATE_COL | TX_16_COL)) != TX_OK) /*读取硬件上的出错标志*/
21 {
22 /* 根据错误的不同情况,对 net_device_stats 的不同成员加 1 */
23 if ((status &TX_OK) == 0)
24 priv->stats.tx_errors++;
25 if (status &TX_LOST_CRS)
26 priv->stats.tx_carrier_errors++;
27 if (status &TX_SQE_ERROR)
28 priv->stats.tx_heartbeat_errors++;
29 if (status &TX_LATE_COL)
30 priv->stats.tx_window_errors++;
31 if (status &TX_16_COL)
32 priv->stats.tx_aborted_errors++;
33 }
34 break;
35 case ISQ_RX_MISS_EVENT:
36 priv->stats.rx_missed_errors += (status >> 6);
37 break;
38 case ISQ_TX_COL_EVENT:
39 priv->stats.collisions += (status >> 6);
40 break;
41 }
42 }
上述代码的第 6 行意味着在发送数据包超时时,将发生发送错误的数据包数增 1。而第 13~41 行则意味着当网络设备中断产生时,中断处理程序读取硬件的相关信息以决定修改 net_device_ stats 统计信息中的哪些项目和子项目,并将相应的项目增 1。