Spark 源码分析(一) SparkRpc中序列化与反序列化Serializer的抽象类解读 (正在更新中~)别人能写出来的,你也能行!多学习别人的思路,形成自己的思路,高薪工作奔你而来!
后一篇链接在这
接上一章请先看解读 序列化抽象类 第一部分(这是一个链接)
目录
接上一章请先看解读 序列化抽象类 第一部分
2.Java序列化实现类 JavaSerializer
(1) JavaSerializationStream类
代码实际例子1:序列化
(2) JavaDeserializationStream
代码实际例子2:反序列化
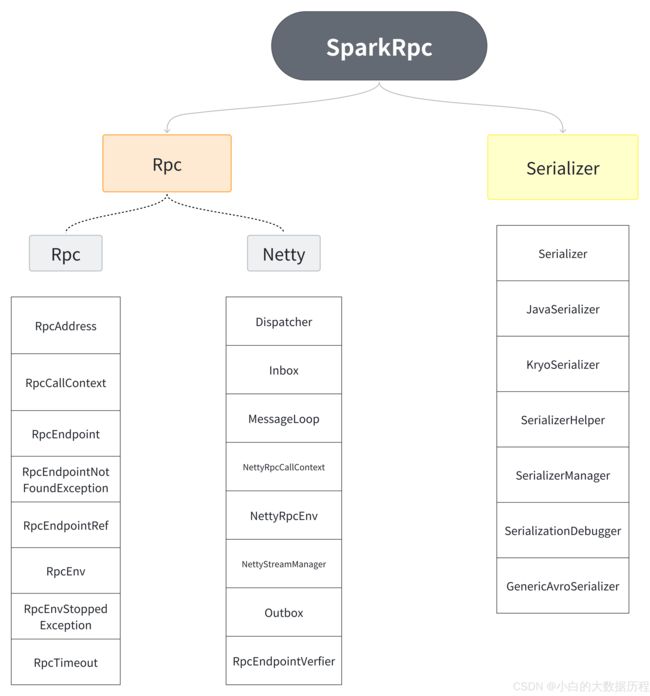
Spark源码下类图
在学习过程中,抓住主要问题,请思考问题为什么Kryo序列化更加快速?
2.Java序列化实现类 JavaSerializer
(1) JavaSerializationStream类 定义了一个java序列化流继承了SerializationStream抽象类
private[spark] class JavaSerializationStream(
out: OutputStream,
counterReset: Int,
extraDebugInfo: Boolean)
extends SerializationStream {
private val objOut = new ObjectOutputStream(out)
private var counter = 0
/**
Calling reset to avoid memory leak:
http://stackoverflow.com/questions/1281549/memory-leak-traps-in-the-java-standard-api
But only call it every 100th time to avoid bloated serialization streams (when
the stream 'resets' object class descriptions have to be re-written)
*/
def writeObject[T: ClassTag](t: T): SerializationStream = {
try {
objOut.writeObject(t)
} catch {
case e: NotSerializableException if extraDebugInfo =>
throw SerializationDebugger.improveException(t, e)
}
counter += 1
if (counterReset > 0 && counter >= counterReset) {
objOut.reset()
counter = 0
}
this
}
def flush(): Unit = { objOut.flush() }
def close(): Unit = { objOut.close() }
}构造函数参数
1、out: OutputStream
OutputStream 是一个抽象类,提供了将字节写入输出流的方法,比如flush()
2、counterReset: Int
一个计数器用于判断是否reset()清除流的缓存信息
3、extraDebugInfo: Boolean
extraDebugInfo 变量用于控制是否启用额外的调试信息。如果为 true,则在序列化过程中的某些操作会输出额外的调试信息(例如,日志记录、输出详细的序列化步骤等)。如果为 false,则序列化过程将不会输出这些调试信息,从而提高效率。
成员变量
private val objOut = new ObjectOutputStream(out)创建输出流
private var counter = 0 计数器
方法实现
1、 writeObject[T: ClassTag](t: T): SerializationStream
这个方法实现了抽象父类的方法签名,但是不知道为什么没加override,建议自己在写代码时,加上override,增强可读性。
具体实现逻辑是:
首先将传入的类对象,通过成员变量objOut(ObjectOutputStream类)的writeObject()方法,将对象写入到构造参数out(OutputStream类)通过objOut 创建的流中
然后抓取异常并处理
最后判断加载的类数量是否超过counterReset,超过了就reset()清除缓存
处理完后,返回本对象,链式调用方式的处理很巧妙
代码实际例子1:序列化
简单给个例子供大家理解
例子中自己加了一个方法getSerializedData()用于获取序列化数据
package org.apache.spark.psy
//记得包名要伪装一下,不然不让用
import org.apache.spark.serializer.SerializationStream
import java.io.{ByteArrayOutputStream, NotSerializableException, ObjectOutputStream}
import scala.reflect.ClassTag
// 简单的 Person 类
class Person(val name: String, val age: Int) extends Serializable
// JavaSerializationStream 类
class JavaSerializationStream(
out: ByteArrayOutputStream,
counterReset: Int,
extraDebugInfo: Boolean
)extends SerializationStream {
private val objOut = new ObjectOutputStream(out)
private var counter = 0
def writeObject[T: ClassTag](t: T): JavaSerializationStream = {
try {
objOut.writeObject(t) // 序列化对象 t
} catch {
case e: NotSerializableException if extraDebugInfo =>
throw new Exception("Serialization exception", e)
}
counter += 1
if (counterReset > 0 && counter >= counterReset) {
objOut.reset() // 清除缓存
counter = 0
}
this // 返回当前的流对象以支持链式调用
}
// 获取序列化数据的方法
def getSerializedData: Array[Byte] = {
objOut.flush() // 确保所有数据都被写入
out.toByteArray // 获取序列化后的字节数组
}
def flush(): Unit = { objOut.flush() }
def close(): Unit = { objOut.close() }
}
// 示例使用
object SerializationExample extends App {
// 创建一个对象
val person = new Person("Alice", 30)
// 使用 ByteArrayOutputStream 存储序列化数据
val byteArrayOutputStream = new ByteArrayOutputStream()
// 创建 JavaSerializationStream 实例
val serializationStream = new JavaSerializationStream(byteArrayOutputStream, counterReset = 100, extraDebugInfo = true)
// 将对象序列化 这就是链式调用的好处,不需要重新定义以获取值,而是直接修改了原对象
serializationStream.writeObject(person)
// 获取序列化的字节数据
val serializedData = serializationStream.getSerializedData
// 打印字节数组(序列化数据)
println(s"Serialized Data: ${serializedData.mkString(", ")}")
}输出
Serialized Data: -84, -19, 0, 5, 115, 114, 0, 27, 111, 114, 103, 46, 97, 112, 97, 99, 104, 101, 46, 115, 112, 97, 114, 107, 46, 112, 115, 121, 46, 80, 101, 114, 115, 111, 110, 34, 60, 47, 85, 17, -32, -29, 110, 2, 0, 2, 73, 0, 3, 97, 103, 101, 76, 0, 4, 110, 97, 109, 101, 116, 0, 18, 76, 106, 97, 118, 97, 47, 108, 97, 110, 103, 47, 83, 116, 114, 105, 110, 103, 59, 120, 112, 0, 0, 0, 30, 116, 0, 5, 65, 108, 105, 99, 101
2、flush方法 用于将数据输出
3、close方法 用于关闭流
(2) JavaDeserializationStream 定义了一个java反序列化流继承了DeserializationStream抽象类,同时定义了一个伴生对象
JavaDeserializationStream 主要包含一个 primitiveMappings 静态常量映射。primitiveMappings 是一个 Map,它将字符串类型的基本数据类型名称(如 "int"、"boolean")映射到对应的 Java 基本类型类(如 classOf[Int]、classOf[Boolean])。
private[spark] class JavaDeserializationStream(in: InputStream, loader: ClassLoader)
extends DeserializationStream {
private val objIn = new ObjectInputStream(in) {
override def resolveClass(desc: ObjectStreamClass): Class[_] =
try {
// scalastyle:off classforname
Class.forName(desc.getName, false, loader)
// scalastyle:on classforname
} catch {
case e: ClassNotFoundException =>
JavaDeserializationStream.primitiveMappings.getOrElse(desc.getName, throw e)
}
override def resolveProxyClass(ifaces: Array[String]): Class[_] = {
// scalastyle:off classforname
val resolved = ifaces.map(iface => Class.forName(iface, false, loader))
// scalastyle:on classforname
java.lang.reflect.Proxy.getProxyClass(loader, resolved: _*)
}
}
def readObject[T: ClassTag](): T = objIn.readObject().asInstanceOf[T]
def close(): Unit = { objIn.close() }
}
private object JavaDeserializationStream {
val primitiveMappings = Map[String, Class[_]](
"boolean" -> classOf[Boolean],
"byte" -> classOf[Byte],
"char" -> classOf[Char],
"short" -> classOf[Short],
"int" -> classOf[Int],
"long" -> classOf[Long],
"float" -> classOf[Float],
"double" -> classOf[Double],
"void" -> classOf[Unit])
}基本类似于JavaSerializationStream类,不同的点在于如同在前面讲到的,在序列化和反序列化过程中要获取好类加载器,防止产生版本冲突或类冲突等问题。
1、构造函数参数
in: InputStream 一个输入流
loader: ClassLoader 类加载器
2、def resolveClass(desc: ObjectStreamClass): Class[_]
用于确定类加载器类型,防止版本问题
3、def resolveProxyClass(ifaces: Array[String]): Class[_]
负责处理复杂数据类型的类加载器
val resolved = ifaces.map(iface => Class.forName(iface, false, loader))这是处理逻辑,通过map函数式编程确定每一个类的类加载器
java.lang.reflect.Proxy.getProxyClass(loader, resolved: _*)然后通过动态代理类,将数组 resolved 解包为多个单独的参数传递给 getProxyClass 方法
简单说就是为了确定复杂数据类型中的每一个类的类型
4、def readObject[T: ClassTag](): T = objIn.readObject().asInstanceOf[T]
读取序列化流,经过反序列化,然后返回该类型
5、close()
关闭流
代码实际例子2:反序列化
最后一样的,给兄弟们一个例子,有条件的建议自己敲一敲代码熟悉熟悉思路,熟悉熟悉流程。
接上一个序列化Person对象,这一次将序列化的结果反序列化为对象Person
package org.apache.spark.psy
//记得包名要伪装一下,不然不让用
import org.apache.spark.serializer.{DeserializationStream, SerializationStream}
import java.io.{ByteArrayInputStream, ByteArrayOutputStream, InputStream, NotSerializableException, ObjectInputStream, ObjectOutputStream, ObjectStreamClass}
import scala.reflect.ClassTag
// 简单的 Person 类
class Person(val name: String, val age: Int) extends Serializable
// JavaSerializationStream 类
class JavaSerializationStream(
out: ByteArrayOutputStream,
counterReset: Int,
extraDebugInfo: Boolean
)extends SerializationStream {
private val objOut = new ObjectOutputStream(out)
private var counter = 0
override def writeObject[T: ClassTag](t: T): JavaSerializationStream = {
try {
objOut.writeObject(t) // 序列化对象 t
} catch {
case e: NotSerializableException if extraDebugInfo =>
throw new Exception("Serialization exception", e)
}
counter += 1
if (counterReset > 0 && counter >= counterReset) {
objOut.reset() // 清除缓存
counter = 0
}
this // 返回当前的流对象以支持链式调用
}
// 获取序列化数据的方法
def getSerializedData: Array[Byte] = {
objOut.flush() // 确保所有数据都被写入
out.toByteArray // 获取序列化后的字节数组
}
def flush(): Unit = { objOut.flush() }
def close(): Unit = { objOut.close() }
}
class JavaDeserializationStream(in: InputStream, loader: ClassLoader)
extends DeserializationStream {
private val objIn = new ObjectInputStream(in) {
override def resolveClass(desc: ObjectStreamClass): Class[_] =
try {
// scalastyle:off classforname
Class.forName(desc.getName, false, loader)
// scalastyle:on classforname
} catch {
case e: ClassNotFoundException =>
JavaDeserializationStream.primitiveMappings.getOrElse(desc.getName, throw e)
}
override def resolveProxyClass(ifaces: Array[String]): Class[_] = {
// scalastyle:off classforname
val resolved = ifaces.map(iface => Class.forName(iface, false, loader))
// scalastyle:on classforname
java.lang.reflect.Proxy.getProxyClass(loader, resolved: _*)
}
}
def readObject[T: ClassTag](): T = objIn.readObject().asInstanceOf[T]
def close(): Unit = { objIn.close() }
}
private object JavaDeserializationStream {
val primitiveMappings = Map[String, Class[_]](
"boolean" -> classOf[Boolean],
"byte" -> classOf[Byte],
"char" -> classOf[Char],
"short" -> classOf[Short],
"int" -> classOf[Int],
"long" -> classOf[Long],
"float" -> classOf[Float],
"double" -> classOf[Double],
"void" -> classOf[Unit])
}
// 示例使用
object SerializationExample extends App {
// 创建一个对象
val person = new Person("Alice", 30)
// 使用 ByteArrayOutputStream 存储序列化数据
val byteArrayOutputStream = new ByteArrayOutputStream()
// 创建 JavaSerializationStream 实例
val serializationStream = new JavaSerializationStream(byteArrayOutputStream, counterReset = 100, extraDebugInfo = true)
// 将对象序列化
serializationStream.writeObject(person)
// 获取序列化的字节数据
val serializedData = serializationStream.getSerializedData
// 打印字节数组(序列化数据)
println(s"Serialized Data: ${serializedData.mkString(", ")}")
//反序列化过程,希望同学们自己能多敲敲代码,把注释补全
val byteArrayInputStream = new ByteArrayInputStream(serializedData)
val deserializationStream = new JavaDeserializationStream(byteArrayInputStream,getClass.getClassLoader)
val deserializedPerson = deserializationStream.readObject[Person]()
println(s"Deserialized Person: Name = ${deserializedPerson.name}, Age = ${deserializedPerson.age}")
}
此处的重点在反序列化过程,希望同学们把注释补全,理解每一个代码的意义,然后就是多敲代码了。
结果
Deserialized Person: Name = Alice, Age = 30
多敲代码!!!!多敲代码!!!!多敲代码!!!!!
今天就暂时更新这么多,希望同学们能多多支持,源码解读不易,点点赞,点点关注,谢谢!