收藏!Python常用的第三方模块,你知道几个呢?
作为一种流行的编程语言,拥有丰富的第三方模块,这些模块极大地扩展了 的功能,使得各种开发任务变得更加高效和便捷.本文将介绍几种常用的第三方模块,提供示例展示,并对它们进行分类,以帮助读者更好地理解和使用这些工具.
-
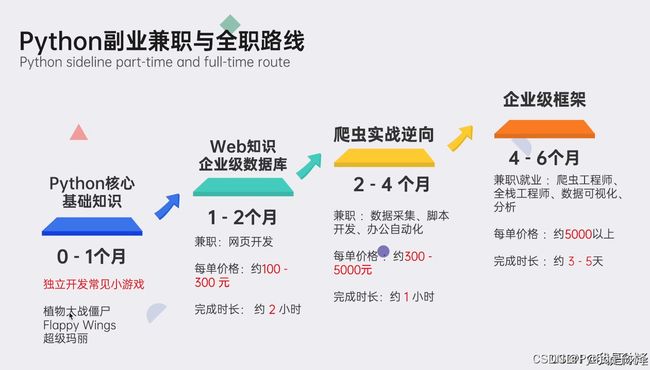
这里插播一条粉丝福利,如果你正在学习Python或者有计划学习Python,想要突破自我,对未来十分迷茫的,可以点击这里获取最新的Python学习资料和学习路线规划(免费分享,记得关注)
1. 数据处理与分析
1.1 Pandas
描述:Pandas 是一个强大的数据分析和操作库,提供了高效的数据结构和数据分析工具,特别适合用于处理表格数据.
示例:
import pandas as pd
# 创建数据框
data = {'Name': ['John', 'Anna', 'Peter'],
'Age': [28, 24, 35]}
df = pd.DataFrame(data)
# 显示数据框
print(df)
# 计算年龄的平均值
print(df['Age'].mean())
功能:
-
数据清洗和处理
-
数据统计和聚合
-
数据可视化支持
1.2 NumPy
描述:NumPy 是一个支持大规模多维数组和矩阵运算的库,提供了数学函数库来操作这些数组.
示例:
import numpy as np
# 创建一个数组
arr = np.array([1, 2, 3, 4, 5])
# 计算数组的均值
print(np.mean(arr))
# 创建一个二维数组
matrix = np.array([[1, 2], [3, 4]])
print(np.dot(matrix, matrix))
功能:
-
高效的数组操作
-
数学运算和统计分析
-
线性代数和傅里叶变换
2. 网络请求与 Web 开发
2.1 Requests
描述:Requests 是一个简单而强大的 HTTP 请求库,用于发送 HTTP 请求并处理响应.
示例:
import requests
# 发送 GET 请求
response = requests.get('https://jsonplaceholder.typicode.com/posts/1')
# 打印响应内容
print(response.json())
功能:
-
简化 HTTP 请求
-
处理请求和响应数据
-
支持会话对象
2.2 Flask
描述:Flask 是一个轻量级的 Web 框架,适用于构建 Web 应用程序和 API.
示例:
from flask import Flask, jsonify
app = Flask(__name__)
@app.route('/')
def home():
return jsonify({'message': 'Hello, Flask!'})
if __name__ == '__main__':
app.run(debug=True)
功能:
-
简单的路由和请求处理
-
支持模板渲染
-
扩展支持丰富的功能
3. 数据可视化
3.1 Matplotlib
描述:Matplotlib 是一个绘图库,用于生成各种图表和图形.
示例:
import matplotlib.pyplot as plt
# 数据
x = [1, 2, 3, 4, 5]
y = [2, 3, 5, 7, 11]
# 创建图形
plt.plot(x, y)
# 添加标题和标签
plt.title('Sample Plot')
plt.xlabel('x-axis')
plt.ylabel('y-axis')
# 显示图形
plt.show()
功能:
-
绘制线图、柱状图、散点图等
-
自定义图形样式
-
支持保存图像
3.2 Seaborn
描述:Seaborn 是基于 Matplotlib 的高级数据可视化库,提供更简洁和美观的图表.
示例:
import seaborn as sns
import matplotlib.pyplot as plt
# 创建数据
tips = sns.load_dataset('tips')
# 创建图形
sns.scatterplot(x='total_bill', y='tip', data=tips)
# 显示图形
plt.show()
功能:
-
提供更高层次的图表
-
支持统计图形
-
视觉美观的默认主题
4. 自动化与工具
4.1 Selenium
描述:Selenium 是一个用于自动化浏览器操作的工具,适合 Web 自动化测试和网页数据抓取.
示例:
from selenium import webdriver
# 启动浏览器
driver = webdriver.Chrome()
# 打开网页
driver.get('https://www.example.com')
# 获取网页标题
print(driver.title)
# 关闭浏览器
driver.quit()
功能:
-
浏览器自动化操作
-
支持多种浏览器
-
支持网页元素操作
4.2 BeautifulSoup
描述:BeautifulSoup 是一个用于解析 HTML 和 XML 文档的库,广泛用于网页抓取和数据提取.
示例:
from bs4 import BeautifulSoup
import requests
# 获取网页内容
response = requests.get('https://www.example.com')
soup = BeautifulSoup(response.text, 'html.parser')
# 提取标题
print(soup.title.string)
功能:
-
解析和遍历 HTML/XML 文档
-
提取网页数据
-
支持多种解析器
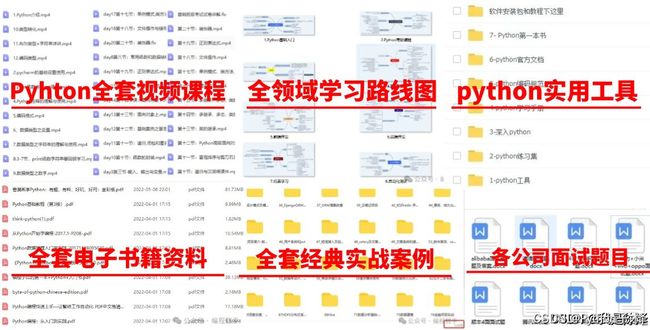
最后,我精心筹备了一份全面的Python学习大礼包,完全免费分享给每一位渴望成长、希望突破自我现状却略感迷茫的朋友。无论您是编程新手还是希望深化技能的开发者,都欢迎加入我们的学习之旅,共同交流进步!
学习大礼包包含内容:
Python全领域学习路线图:一目了然,指引您从基础到进阶,再到专业领域的每一步学习路径,明确各方向的核心知识点。
超百节Python精品视频课程:涵盖Python编程的必备基础知识、高效爬虫技术、以及深入的数据分析技能,让您技能全面升级。
实战案例集锦:精选超过100个实战项目案例,从理论到实践,让您在解决实际问题的过程中,深化理解,提升编程能力。
华为独家Python漫画教程:创新学习方式,以轻松幽默的漫画形式,让您随时随地,利用碎片时间也能高效学习Python。
互联网企业Python面试真题集:精选历年知名互联网企业面试真题,助您提前备战,面试准备更充分,职场晋升更顺利。
立即领取方式:只需【点击这里】,即刻解锁您的Python学习新篇章!让我们携手并进,在编程的海洋里探索无限可能