SQLSugar进阶使用:高级查询与性能优化
文章目录
- 前言
- 一、高级查询
-
- 1.查所有
- 2.查询总数
- 3.按条件查询
- 4.动态OR查询
- 5.查前几条
- 6.设置新表名
- 7.分页查询
- 8.排序 OrderBy
- 9.联表查询
- 10.动态表达式
- 11.原生 Sql 操作 ,Sql和存储过程
- 二、性能优化
-
- 1.二级缓存
- 2.批量操作
- 3.异步操作
- 4.分表组件,自动分表
- 5.查询
- 6.插入
- 7.删除数据
- 8.引入库
- 9.读写分离/主从
- 总结
前言
SqlSugar作为一款专为.NET平台设计的轻量级ORM(对象关系映射)框架,其进阶使用中的高级查询与性能优化涵盖了多个方面的内容。
一、高级查询
SqlSugar提供了丰富的高级查询功能,以满足复杂的业务需求,主要包括:
1.查所有
List list=db.Queryable().ToList()
//select * from Student
2.查询总数
int count=db.Queryable().Count()
//select count(1) from Student
3.按条件查询
db.Queryable().Where(it=>it.Id==1).ToList()
//select * from Student where id=1
db.Queryable().Where(it=>it.name !=null).ToList()//不是null
//select * from Student where name is not null
db.Queryable().Where(it=>it.name ==null).ToList()//是null
//select * from Student where name is null
db.Queryable().Where(it=>it.name !="").ToList()//不是空 ,不为空
//select * from Student where name <> ''
4.动态OR查询
var exp= Expressionable.Create();
exp.OrIF(条件,it=>it.Id==1);//.OrIf 是条件成立才会拼接OR
exp.Or(it =>it.Name.Contains("jack"));//拼接OR
var list=db.Queryable().Where(exp.ToExpression()).ToList();
5.查前几条
db.Queryable().Take(10).ToList()
//select top 10 * from Student
6.设置新表名
//例1:更新表名
db.Queryable().AS("Student").ToList();
//生成的SQL SELECT [ID],[NAME] FROM Student
//动态表名 表别名 指定表明
//例2:给表名添加前缀
db.Queryable().AS("dbo.School").ToList();
//生成的SQL SELECT [ID],[NAME] FROM dbo.School
7.分页查询
.ToPageList(pagenumber, pageSize)// 不返回Count
.ToPageList(pagenumber, pageSize, ref totalCount)//返回Count
.ToPageList(pagenumber, pageSize, ref totalCount,ref totalPage)//返回Count+总页数
8.排序 OrderBy
var list =db.Queryable()
.LeftJoin((st, sc) =>st.SchoolId==sc.Id)
.OrderBy((st,sc)=>st.SchoolId)//写Select前面用法,正常都这么用
.Select((st,sc)=>new Dto(){ id=it.id ,Name=it.Name})
.ToList();
9.联表查询
//联表查询
var query5 = db.Queryable()
.LeftJoin((o,cus) => o.CustomId == cus.Id)//多个条件用&&
.LeftJoin ((o,cus,oritem) => o.Id == oritem.OrderId)
.Where(o => o.Id == 1)
.Select((o,cus,oritem) => new ViewOrder {Id=o.Id,CustomName = cus.Name })
.ToList(); //ViewOrder是一个新建的类,更多Select用法看下面文档
10.动态表达式
//用例1:连写
Expression> exp = Expressionable.Create() //创建表达式
.AndIF(p > 0, it => it.Id == p)
.AndIF(name != null, it => it.Name == name && it.Sex==1)
.ToExpression();//注意 这一句 不能少
var list = db.Queryable().Where(exp).ToList();//直接用就行了不需要判段 null和加true
//用例2:分开写法
var expable= Expressionable.Create();
...逻辑
expable.And(it.xx==x);
...逻辑
expable.And(it.yy==y);
...逻辑
var exp=expable.ToExpression();//要用变量 var exp=
db.Queryable().Where(exp).ToList()//直接用就行了不需要判段 null和加true
//用例3:多表查询
var exp=Expressionable.Create()
.And((x,y,z)=>z.id==1).ToExpression();//注意 这一句 不能少
//技巧 WhereIF 有时候更方便
var list=db.Queryable()
.WhereIF(p>0,it=>it.p==p)
.WhereIF(y>0,it=>it.y==y)
.ToList()
11.原生 Sql 操作 ,Sql和存储过程
//调用Sql
db.Ado.具体方法
//调用存储过程
db.Ado.UseStoredProcedure().具体方法
方法列表:
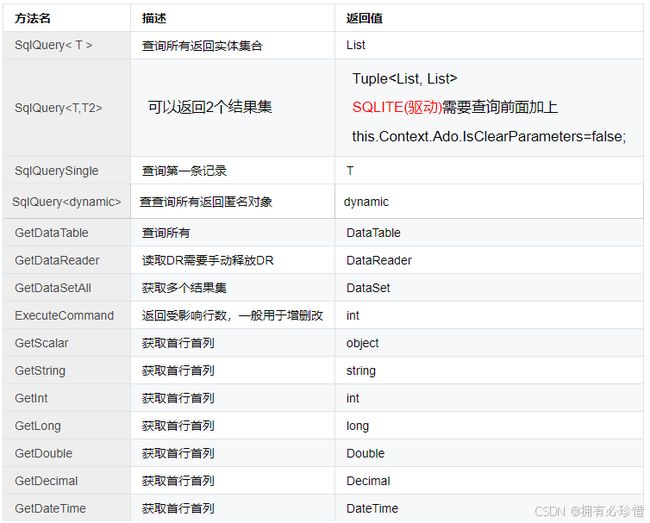
二、性能优化
为了提升数据库操作的性能,SqlSugar提供了多种优化措施。
1.二级缓存
二级缓存是将结果集进行缓存,当SQL和参数没发生变化的时候从缓存里面读取数据,减少数据库的读取操作。
- 维护方便:SqlSugar的 二级缓存 支持单表和多表的 CRUD 自动缓存更新 ,减少了复杂的缓存KEY维护操作
- 使用方便:可以直接在Queryable.WithCache直接缓存当前对象
- 外部集成:通过实现ICacheService接口,来调用外部缓存方法,想用什么实现什么
注意:Sql语句一直在变的就不适合缓存,比如 ID=?这种SQL都在变化,并且表的数量巨大这种情况就不要使用缓存了,缓存适合加
2.批量操作
批量操作海量数据操作ORM性能瓶颈在实体转换上面,并且不能使用常规的Sql去实现。
当列越多转换越慢,SqlSugar将转换性能做到极致,并且采用数据库最佳API,操作数据库达到极限性能。
1.BulkCopy
大数据插入
db.Fastest().BulkCopy(lstData);//插入
db.Fastest().PageSize(100000).BulkCopy(insertObjs);
db.Fastest().AS("order").BulkCopy(dataTable);
2.BulkUpdate
大数据更新
db.Fastest().BulkUpdate(GetList())//更新
db.Fastest().PageSize(100000).BulkUpdate(GetList())//更新
db.Fastest().BulkUpdate(GetList(),new string[] { "Id"});//无主键
db.Fastest().BulkUpdate(GetList(), new string[]{"id"},
new string[]{"name","time"})//只更新几列
//DataTable
db.Fastest().AS("Order").BulkUpdate(dataTable,new string[] {"Id"});//Id是主键
db.Fastest().AS("Order").BulkUpdate(dataTable,new string[] {"Id"},更新的列);
3. BulkMerge (5.1.4.109)
大数据 :插入或者更新
//原理
//Oracle和SqlServer使用了Merge Into+BulkCopy
//其他库底层是 db.Storageable(list).ExecuteSqlBulkCopy()
db.Fastest().BulkMerge(List);
db.Fastest().PageSize(100000).BulkMerge(List);
//DataTable 升级到:SqlSugarCore 5.1.4.147-preview15+
db.Fastest()
.AS("Order")//表名
//第一个参数datatable
//第二个参数主键
//第三个参数是不是自增 true为自增
.BulkMerge(dt, new string[] { "Id" },true);
4. BulkQuery
普通查询就行了性能超快
db.Queryable().ToList();//比Dapper略快
//分页降低内存 适合复杂的DTO转换和导出
List order = new List();
db.Queryable().ForEach(it=> { order.Add(it); /*禁止这儿操作数据库因为会循环*/} ,2000);
5. BulkDelete
直接用分页删除就行了
db.Deleteable(list).PageSize(1000).ExecuteCommand();
3.异步操作
释放主线程的占用,提高吞吐量,直接运行并不能提高速度,合适场景使用,当然全部都写异步也并没大问题,只是代码难提升了,建议合适场景使用,高并发,数据库请求时间过长等场景使用。
SqlSugar中ToList是同步方法,那么ToListAsync这种是异步方法,通过Async来区别是同步还是异步方法。
var data=await db.Queryable().FirstAsync();
var list= await db.Queryable().Where(it=>it.Id==1).ToListAsync();
//分页需要特别注意用法
RefAsync total = 0;
var list=await Db.Queryable().ToPageListAsync(1, 2, total);
4.分表组件,自动分表
自带分表支持按年、按季、按月、按周、按日进行分表(支持混合使用)。
- 可扩展架构设计,比如一个ERP用5年不卡,到了10就卡了,很多人都是备份然后清空数据
- 数据量太多 ,例如每天都有 几十上百万的数据进入库,如果不分表后面查询将会非常缓慢
- 性能瓶颈 ,数据库现有数据超过1个亿,很多情况下索引会莫名失效,性能大大下降
1.定义实体:
我们定义一个实体,主键不能用自增或者int ,设为long或者guid都可以,我例子就用自带的雪花ID实现分表。
[SplitTable(SplitType.Year)]//按年分表 (自带分表支持 年、季、月、周、日)
[SugarTable("SplitTestTable_{year}{month}{day}")]//3个变量必须要有,这么设计为了兼容开始按年,后面改成按月、按日
public class SplitTestTable
{
[SugarColumn(IsPrimaryKey =true)]
public long Id { get; set; }
public string Name { get; set; }
[SugarColumn(IsNullable = true)]//设置为可空字段 (更多用法看文档 迁移)
public DateTime UpdateTime{get;set;}
[SplitField] //分表字段 在插入的时候会根据这个字段插入哪个表,在更新删除的时候用这个字段找出相关表
public DateTime CreateTime { get; set; }
}
//按年分表格式如下
SplitTestTable_20220101
//比如现在5月按月分表格式如下
SplitTestTable_20220501
//比如现在5月11日按日分表格式如下
SplitTestTable_20220511
2.同步表和结构:
假如分了20张表,实体类发生变更,那么 20张表可以自动同步结构,与实体一致。
//不写这行代码 你也可以用插入建表,插入用法看文档下面
db.CodeFirst
.SplitTables()//标识分表
.InitTables(); //程序启动时加这一行,如果一张表没有会初始化一张
注意:插入会自动建表不需要这行代码,主要用于实体改动后同步多个表结构,或者一张表没有初始一张,禁止写到业务里面多次执行。
5.查询
1.查询: 时间过滤
通过开始时间和结束时间自动生成CreateTime的过滤并且找到对应时间的表。
//简单示例
var list=db.Queryable().SplitTable(beginDate,endDate).ToPageList(1,2);
//结合Where
var list=db.Queryable().Where(it=>it.Id>0).SplitTable(beginDate,endDate).ToPageList(1,2);
//注意:
//1、 分页有 OrderBy写 SplitTable 后面 ,uinon all后在排序
//2、 Where尽量写到 SplitTable 前面,先过滤在union all
//原理:(sql union sql2) 写SplitTable 后面生成的括号外面,写前生成的在括号里面
2. 查询: 选择最近的表
如果下面是按年分表 Take(3) 表示 只查 最近3年的分表数据。
var list=db.Queryable()
.Where(it=>it.Pk==Guid.NewGuid())
.SplitTable(tabs => tabs.Take(3))//近3张,也可以表达式选择
.ToList();
3.查询: 精准定位一张表
根据分表字段的值可以精准的定位到具体是哪一个分表,比Take(N)性能要高出很多
var name=Db.SplitHelper().GetTableName(data.CreateTime);//根据时间获取表名
//推荐:表不存在不会报错
var list=db.Queryable().SplitTable(tabs => tabs.InTableNames(name)).ToList()
//不推荐:查询不推荐用,删除和更新可以用
var list=Db.Queryable().AS(name).Where(it => it.Id==data.Id).ToList();
4.查询: 表达式定位哪几张表
Db.Queryable()
.Where(it => it.Id==data.Id)
.SplitTable(tas => tas.Where(y=>y.TableName.Contains("2019")))//表名包含2019的表
.ToList();
5.查询: 分表Join正常表
//分表使用联表查询
var list=db.Queryable() // Order是分表
.SplitTable(tabs=>tabs.Take(3)) //可以换成1-8的所有分表写法,不是只能take
.LeftJoin((o,c)=>o.CustomId==c.Id)//Custom正常表
.Select((o,c)=>new { name=o.Name,cname=c.Name }).ToPageList(1,2);
6.查询: 分表JOIN分表
var rightQuery=db.Queryable().SplitTable(tabs=>tabs.Take(3)) ;
var list=db.Queryable().SplitTable(tabs=>tabs.Take(3))
.LeftJoin(rightQuery,(o,c)=>o.CustomId==c.Id) // Join rightQuery
.Select((o,c)=>new { name=o.Name,cname=c.Name }).ToPageList(1,2);
//技巧:如果是单表分表没有表返回第一个表可以防止报错 升级到:5.1.4.127 +
SplitTable(it=>it.ContainsTableNamesIfNullDefaultFirst("table"))
7. 查询: 性能优化
条件尽可能写在SplitTable前面,因为这样会先过滤在合并
.Where(it => it.Pk == Guid.NewGuid()) //先过滤
.SplitTable(tabs => tabs.Take(3))//在分表
8.查询: 所有分表检索
//如果是主键查询哪怕100个分表都很快
var list = db.Queryable()
.Where(it => it.Pk == Guid.NewGuid()) //适合有索引列,单条或者少量数据查询
.SplitTable().ToList();//没有条件就是全部表
//老版本
var list = db.Queryable()
.Where(it => it.Pk == Guid.NewGuid()) //适合有索引列,单条或者少量数据查询
.SplitTable(tab=>tab).ToList();
6.插入
因为我们用的是Long所以采用雪花ID插入(guid也可以禁止使用自增列)
var data = new SplitTestTable()
{
CreateTime=Convert.ToDateTime("2019-12-1"),//要配置分表字段通过分表字段建表
Name="jack"
};
//雪花ID+表不存在会建表
db.Insertable(data).SplitTable().ExecuteReturnSnowflakeIdList();//插入并返回雪花ID并且自动赋值ID
//服务器时间修改、不同端口用同一个代码、多个程序插入一个表都需要用到WorkId
//保证WorkId唯一 ,程序启动时配置 SnowFlakeSingle.WorkId=从配置文件读取;
//GUID+表不存在会建表
db.Insertable(data).SplitTable().ExecuteCommand();//插入GUID 自动赋值 ID
//大数据写入+表不存在会建表
db.Fastest().SplitTable().BulkCopy(List);//自动找表大数据写入
//不会自动建表 如果表100%存在用这个性能好些
db.Fastest().AS(表名).BulkCopy(List);//固定表大数据写入
注意:.SplitTable不要漏掉了
7.删除数据
1.推荐用法:新功能 5.0.7.7 preview及以上版本
//直接根据实体集合删除 (全自动 找表插入)
db.Deleteable(deleteList).SplitTable().ExecuteCommand();//,SplitTable不能少
2.最近3张表都执行一遍删除
db.Deleteable().In(id).SplitTable(tas=>tas.Take(3)).ExecuteCommand();
3.精准删除
相对于上面的操作性能更高,可以精准找到具体表
var tableName=Db.SplitHelper().GetTableName(data.CreateTime);//根据时间获取表名
db.Deleteable().AS(tableName).Where(deldata).ExecuteCommand();
//DELETE FROM [SplitTestTable_20210101] WHERE [Id] IN (1454676863531089920)
4.范围删除
var tables = db.SplitHelper().GetTables().Take(3);//近3张分表
foreach (var item in tables)
{
//删除1点到6点时间内数据
db.Deleteable() .AS(item.TableName)//使用当前分表名
.Where(it => it.Time.Hour < 1&&it.Time.Hour<6)
.ExecuteCommand();
}
8.引入库
推荐用法: 新功能 5.0.7.7 preview及以上版本
//直接根据实体集合更新 (全自动 找表更新)
db.Updateable(updateList).SplitTable().ExecuteCommand();//.SplitTable()不能少
//BulkCopy分表更新
db.Fastest().SplitTable().BulkUpdate(List);
//部分数据库需配置 具体用法看文档:
//范围更新
var tables = db.SplitHelper().GetTables().Take(3);//近3张分表
foreach (var item in tables)
{
//更新1点到6点时间内数据
db.Updateable() .AS(item.TableName)//使用分表名
.SetColumns(it=>new OrderSpliteTest(){ Static=1 })
.Where(it => it.Time.Hour < 1&&it.Time.Hour<6)
.ExecuteCommand();
}
更多用法:
//更新近3张表
db.Updateable(deldata).SplitTable(tas=>tas.Take(3)).ExecuteCommand();
//精准找单个表
var tableName=Db.SplitHelper().GetTableName(data.CreateTime);//根据时间获取表名
db.Updateable(deldata).AS(tableName).ExecuteCommand();//实体
db.Updateable().AS(tableName).SetColumns(..).Where(...).ExecuteCommand();//表达式
//通过表达式过滤出要更新的表
db.Updateable(deldata).SplitTable(tas => tas.Where(y=>y.TableName.Contains("_2019"))).ExecuteCommand();
9.读写分离/主从
1.配置从表
-
如果存在事务所有操作都走主库,不存在事务 修改、写入、删除走主库,查询操作走从库
-
HitRate 越大走这个从库的概率越大
假设A从库 HitRate设置为5,假设B从库 HitRate设置为10,A的概率为33.3% B的概率为66.6%SqlSugarClient db = new SqlSugarClient(new ConnectionConfig()
{
ConnectionString = Config.ConnectionString,//主库
DbType = DbType.SqlServer,
IsAutoCloseConnection = true,
//从库
SlaveConnectionConfigs = new List() {
new SlaveConnectionConfig() { HitRate=10, ConnectionString=Config.ConnectionString2 } ,
new SlaveConnectionConfig() { HitRate=10, ConnectionString=Config.ConnectionString2 }
}
});
2.强制走主库
新功能:5.0.8 用法和Queryable一样
Db.MasterQueryable().Where(x=>x.id==1).ToList() //强制走主库
//5.1.3.22修复了异步不会生效
事务
//事务中全部会走主库
通过配置走主库
//方式1.强制配置
db.Ado.IsDisableMasterSlaveSeparation=true
总结
综上所述,SqlSugar的高级查询功能提供了强大的数据筛选、排序和连表查询能力,而性能优化则通过缓存、SQL优化、批量操作等多种手段来提高数据库操作的效率。这些特性使得SqlSugar在.NET开发领域具有广泛的应用前景。
“笑对人生,智慧同行!博客新文出炉,微信订阅号更新更实时,等你笑纳~”