深度学习理论基础(七)Transformer编码器和解码器
学习目录:
深度学习理论基础(一)Python及Torch基础篇
深度学习理论基础(二)深度神经网络DNN
深度学习理论基础(三)封装数据集及手写数字识别
深度学习理论基础(四)Parser命令行参数模块
深度学习理论基础(五)卷积神经网络CNN
深度学习理论基础(六)Transformer多头自注意力机制
深度学习理论基础(七)Transformer编码器和解码器
本文目录
- 学习目录:
- 前述: Transformer总体结构框图
-
- 1. 嵌入层:
- 2. 位置编码器
- 3. 多头注意力层
- 4. 规范化层
- 5. 残差连接
- 6. 前馈全连接层
- 一、编码器encoder
-
- 1. 编码器作用
- 2. 编码器部分
-
- (1)单个编码器层代码
- (2)编码器总体代码
- 二、解码器decoder
-
- 1. 解码器作用
- 2. 解码器部分
-
- (1)单个解码器层代码
- (2)解码器总体代码
- 三、Transformer
-
- 1. 框图
- 2. 代码
前述: Transformer总体结构框图
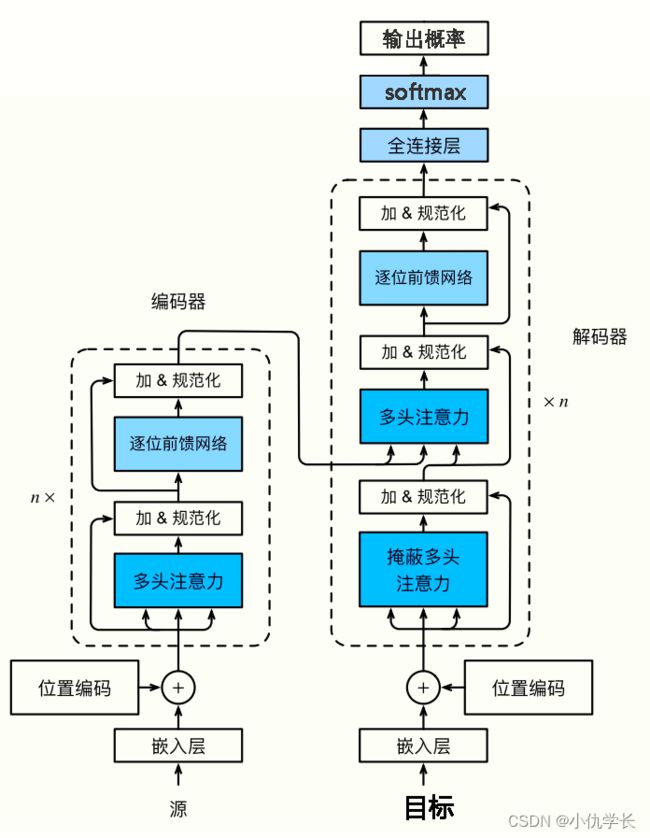
1. 嵌入层:
编码器的输入是一系列的词嵌入(Word Embeddings),它将文本中的每个词映射到一个高维空间中的向量表示。
嵌入层的作用是将离散符号转换为连续的向量表示,降低数据维度同时保留语义信息,提供词语的上下文信息以及初始化模型参数,从而为深度学习模型提供了有效的输入表示。
class Embeddings(nn.Module):
def __init__(self,d_model,vocab):
'''
类的初始化函数,有两个参数
d_model:指词嵌入的维度
vocab:指词表的大小
'''
#接着就是使用super的方式指明继承nn.Module的初始化函数,我们自己实现的所有层都会这样去调用
super(Embeddings,self).__init__()
#之后就是调用nn中预定义层Embedding,获得一个词嵌入对象self.lut
self.lut = nn.Embedding(vocab,d_model)
#最后就是将d_model传入类中
self.d_model = d_model
def forward(self,x):
'''
可以将其理解为该层的前向传播逻辑,所有层中都会有此函数
当传给该类的实例化对象参数时,自动调用该类函数
:param x: 因为Embedding层是首层,所以代表输入给模型的文本通过词汇映射后的数字张量
:return:
'''
#将x传给self.lut并与根号下self.d_module相乘作为结果返回
return self.lut(x) * math.sqrt(self.d_model)
2. 位置编码器
为了使 Transformer 能够处理序列信息,位置编码被引入到词嵌入中,以区分不同位置的词。通常使用正弦和余弦函数来生成位置编码。
一句话中同一个词,如果词语出现位置不同,意思可能发生翻天覆地的变化,就比如:我爱你 和 你爱我。这两句话的意思完全不一样。可见获取词语出现在句子中的位置信息是一件很重要的事情。但是Transformer 的是完全基于self-Attention地,而self-attention是不能获取词语位置信息的,就算打乱一句话中词语的位置,每个词还是能与其他词之间计算attention值,就相当于是一个功能强大的词袋模型,对结果没有任何影响。所以在我们输入的时候需要给每一个词向量添加位置编码。
位置编码是通过在输入序列的每个位置上添加一个与位置相关的固定向量来实现的。这个向量会在前向传播过程中与输入的词嵌入向量相加,以产生具有位置信息的新的向量表示。
●公式:
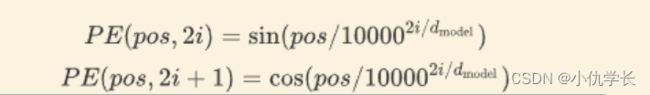
① PE:表示位置编码矩阵,可先使用 torch.zeros(行,列) 创建一个全0的矩阵,然后再通过操作将其中的某些元素赋值,形成含有位置信息的矩阵。
② pos:表示输入序列所在行的位置。范围0~输入序列矩阵行长度。
③ d_model :输入、输出向量的维度大小。
④ i:取值范围为 [ 0, d_model] ,但每次移动步长为2。 因为当 i 为偶数时,使用sin函数,当 i 为奇数时,使用cos函数。
●代码:
class PositionalEncoder(nn.Module):
def __init__(self, d_model, max_seq_len = 200, dropout = 0.1):
super().__init__()
self.d_model = d_model #输入维度
self.dropout = nn.Dropout(dropout)
pe = torch.zeros(max_seq_len, d_model) # 创建一个形状为 (max_seq_len, d_model) 的位置编码矩阵,元素权威0
for pos in range(max_seq_len):
for i in range(0, d_model, 2):
pe[pos, i] = math.sin(pos / (10000 ** ((2 * i)/d_model)))
pe[pos, i + 1] = math.cos(pos / (10000 ** ((2 * i)/d_model)))
pe = pe.unsqueeze(0) # 在第0维度上添加一个维度,变成 (1, max_seq_len, d_model)
# PE位置编码矩阵其中的元素修改好后,可以注册位置编码矩阵为模型的 buffer,即封装起来。
self.register_buffer('pe', pe)
def forward(self, x):
# 将输入乘以一个与模型维度相关的缩放因子
x = x * math.sqrt(self.d_model)
# 将位置编码添加到输入中
seq_len = x.size(1)
pe = self.pe[:, :seq_len].clone().detach() # 从缓冲区中获取位置编码
# if x.is_cuda:
# pe = pe.cuda() # 将位置编码移到GPU上,如果输入张量也在GPU上
x = x + pe # 输入向量,加上位置编码器。
return self.dropout(x) # 加上丢弃层,防止过拟合。
3. 多头注意力层
这是编码器的核心组件之一。它允许模型在输入序列中学习词与词之间的依赖关系,通过计算每个词对其他词的注意力权重来实现。多头机制允许模型在不同的表示空间中并行地学习多种关注方向。多头注意力层详情查看地址!
def attention(q, k, v, d_k, mask=None, dropout=None):
scores =