构建企业私有RAG大模型: (可商用)Qwen2.5开源模型vLLM部署及示例
在企业真实场景中,开发接口通常需要针对具体需求进行定制化处理,以更好地适配 RAG 应用系统的实际需求。相关代码后续会以 Git 仓库的形式分享。
本章将继续探讨开源大模型的部署。在 RAG 系统的架构中,大模型扮演着至关重要的角色,是整个流程的“最后一环”。知识库的构建、检索,以及知识的排序与整合,都是为了为大模型提供准确、完整的上下文知识。这种知识支撑可以显著降低大模型生成过程中的幻觉问题(如生成不可靠或错误答案)。因此,大模型的生成能力直接决定了 RAG 系统的服务质量,特别是在为用户问题生成答案时,精准性与可靠性尤为关键。
目前可商用的开源大模型主要包括:
- GLM-4-9B-Chat
- Qwen2.5-7B
- DeepSeek-7B-Chat
DeepSeekV3 近期备受瞩目,其多项测试指标超越了其他开源模型,甚至在某些方面达到或超过部分闭源大模型的水平。V3 模型体量巨大,尽管 vLLM、SGLang 和 LMDeploy 等加速框架已支持其部署,但仍有许多优化空间。此外,部署所需的 GPU 资源极为庞大,对企业硬件条件提出了较高要求。因此,我们计划在未来合适的时间分享其具体的部署实践与优化策略。
本篇主要介绍阿里Qwen2.5-7B模型的vLLM的部署与示例。
Qwen2.5介绍
Qwen2.5是Qwen家族的新成员,发布已经几个月了,具有以下特点:
- 密集、易于使用、仅解码器的语言模型,有0.5B、1.5B、3B、7B、14B、32B和72B大小以及基本和指示变体。
- 在我们最新的大规模数据集上进行预训练,涵盖多达18T 个标记。
- 在指令跟踪、生成长文本(超过 8K 个标记)、理解结构化数据(例如表格)以及生成结构化输出(尤其是 JSON)方面有显著改进。
- 更能适应系统提示的多样性,增强聊天机器人的角色扮演实现和条件设定。
- 上下文长度最多支持128K个token,最多可生成8K个token。
- 支持超过29种语言,包括中文、英语、法语、西班牙语、葡萄牙语、德语、意大利语、俄语、日语、韩语、越南语、泰语、阿拉伯语等。
vLLM介绍
接下来,将详细介绍如何通过 vLLM 部署 Qwen2.5 的具体步骤,以及在vLLM加速下验证聊天接口。
硬件与环境配置建议
企业可根据成本和业务需求选择硬件设备,以下是推荐配置:
- GPU建议
-
建议使用 NVIDIA 3090 或 4090 显卡。
-
若仅用于功能验证,一块 GPU 即可满足需求;实际部署可根据业务规模决定 GPU 数量。
- 操作系统
- Ubuntu 20.04 或更高版本。
- CUDA版本
- 需安装 CUDA 12.1 或更高版本。
- 深度学习框架
- PyTorch 2.1.0 或更高版本。
- Python版本
- 使用 Python 3.10 或更高版本(推荐使用 Conda 环境管理工具)。
确保环境与硬件兼容,是大模型高效运行的关键。
vLLM的安装
执行以下命令:conda的创建及依赖的安装
conda create -n vllm_qwen python=3.10``conda activate vllm_qwen``# 升级pip``python -m pip install --upgrade pip``pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple`` ``pip install vllm``pip install modelscope[framework]
直接安装 vLLM,默认会安装 支持CUDA 12.1及以上版本的vLLM,
如果我们需要在 CUDA 11.8 的环境下安装 vLLM,指定 vLLM 版本和 python 版本下载安装。
模型的下载
模型的下载可以使用以下两种方式:
- 使用ModelScope下载,执行以下命令,将模型下载到/qwen目录下。
git clone https://www.modelscope.cn/Qwen/Qwen2.5-7B-Instruct.git
- 使用HF国内的镜像下载,执行以下命令,将模型下载到/qwen目录下。
git clone https://hf-mirror.com/Qwen/Qwen2.5-7B-Instruct
下载完成后可以看到目录结构如下:
qwen/Qwen2.5-7B-Instruct/``|-- LICENSE``|-- README.md``|-- config.json``|-- configuration.json``|-- generation_config.json``|-- merges.txt``|-- model-00001-of-00004.safetensors``|-- model-00002-of-00004.safetensors``|-- model-00003-of-00004.safetensors``|-- model-00004-of-00004.safetensors``|-- model.safetensors.index.json``|-- tokenizer.json``|-- tokenizer_config.json````-- vocab.json `
代码准备
简单示例Python文件
在/qwen目录下创建vllm-run.py,创建完目录结构如下:
/qwen/``|-- Qwen2.5-7B-Instruct``| |-- LICENSE``| |-- README.md``| |-- config.json``| |-- configuration.json``| |-- generation_config.json``| |-- merges.txt``| |-- model-00001-of-00004.safetensors``| |-- model-00002-of-00004.safetensors``| |-- model-00003-of-00004.safetensors``| |-- model-00004-of-00004.safetensors``| |-- model.safetensors.index.json``| |-- tokenizer.json``| |-- tokenizer_config.json```| `-- vocab.json`````-- vllm_run.py `
vllm_run代码如下,通过示例代码可以快速熟悉 vLLM 引擎的使用方式。
from transformers import AutoTokenizer``from vllm import LLM, SamplingParams`` ``max_model_len, tp_size = 2048, 1``model_name = "./Qwen2.5-7B-Instruct"``prompt = [{"role": "user", "content": "你好,讲讲你是谁?"}]`` ``tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)``llm = LLM(` `model=model_name,` `tensor_parallel_size=tp_size,` `max_model_len=max_model_len,` `trust_remote_code=True,` `enforce_eager=True,` `enable_chunked_prefill=True,` `max_num_batched_tokens=2048``)``stop_token_ids = [151329, 151336, 151338]``sampling_params = SamplingParams(temperature=0.95, max_tokens=1024, stop_token_ids=stop_token_ids)`` ``inputs = tokenizer.apply_chat_template(prompt, tokenize=False, add_generation_prompt=True)``outputs = llm.generate(prompts=inputs, sampling_params=sampling_params)`` ``print(outputs[0].outputs[0].text)
执行以下命令:
# export CUDA_VISIBLE_DEVICES=3 ,如果不指定卡号,默认使用0卡``python vllm-run.py
执行结果:
INFO 01-11 04:21:12 model_runner.py:1099] Loading model weights took 14.2487 GB``INFO 01-11 04:21:13 worker.py:241] Memory profiling takes 0.69 seconds``INFO 01-11 04:21:13 worker.py:241] the current vLLM instance can use total_gpu_memory (23.64GiB) x gpu_memory_utilization (0.90) = 21.28GiB``INFO 01-11 04:21:13 worker.py:241] model weights take 14.25GiB; non_torch_memory takes 0.12GiB; PyTorch activation peak memory takes 1.40GiB; the rest of the memory reserved for KV Cache is 5.51GiB.``INFO 01-11 04:21:13 gpu_executor.py:76] # GPU blocks: 6443, # CPU blocks: 4681``INFO 01-11 04:21:13 gpu_executor.py:80] Maximum concurrency for 2048 tokens per request: 50.34x``INFO 01-11 04:21:17 llm_engine.py:431] init engine (profile, create kv cache, warmup model) took 4.89 seconds``Processed prompts: 100%|█████████████████████████████████████████| 1/1 [00:00<00:00, 1.01it/s, est. speed input: 36.52 toks/s, output: 53.76 toks/s]``你好!我是Qwen,我是由阿里云开发的一种超大规模语言模型。我被设计用来回答问题、提供信息、参与对话,旨在帮助用户获得所需的知识和信息。如果你有任何问题或需要帮助,都可以尝试和我交流。``
构建与 OpenAI 兼容的 API 服务
使用 vLLM 来构建与 OpenAI 兼容的 API 服务,包括工具使用支持。使用聊天模型启动服务器。
例如:在/qwen目录下执行以下命令:
export CUDA_VISIBLE_DEVICES=3 //指定GPU默是0卡``vllm serve Qwen2.5-7B-Instruct
通过 curl 命令查看当前API Server的模型列表。
curl http://localhost:8000/v1/models
查看结果如下:
{` `"object": "list",` `"data": [{` `"id": "Qwen2.5-7B-Instruct",` `"object": "model",` `"created": 1736570004,` `"owned_by": "vllm",` `"root": "Qwen2.5-7B-Instruct",` `"parent": null,` `"max_model_len": 32768,` `"permission": [{` `"id": "modelperm-62acae496e714754b5d8866fff32f0cb",` `"object": "model_permission",` `"created": 1736570004,` `"allow_create_engine": false,` `"allow_sampling": true,` `"allow_logprobs": true,` `"allow_search_indices": false,` `"allow_view": true,` `"allow_fine_tuning": false,` `"organization": "*",` `"group": null,` `"is_blocking": false` `}]` `}]``}
聊天对话接口,curl使用prompt调用
curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{` `"model": "Qwen2.5-7B-Instruct",` `"messages": [` `{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},` `{"role": "user", "content": "告诉我一些关于大型语言模型的事情。"}` `],` `"temperature": 0.7,` `"top_p": 0.8,` `"repetition_penalty": 1.05,` `"max_tokens": 512``}'
查看结果如下:
{` `"id": "chatcmpl-c774bbba1c5c47579a77dec6ef87d987",` `"object": "chat.completion",` `"created": 1736570396,` `"model": "Qwen2.5-7B-Instruct",` `"choices": [{` `"index": 0,` `"message": {` `"role": "assistant",` `"content": "当然,我很乐意为您介绍一些关于大型语言模型的知识!\n\n大型语言模型是一种深度学习模型,它通过处理大量的文本数据来学习人类语言的结构和规律。这些模型通常包含数以亿计甚至更多参数,因此被称为“大型”。它们能够生成连贯的文本、回答问题、翻译语言、创作故事等多种任务。\n\n### 1. 应用领域\n\n- **自然语言处理**:包括机器翻译、情感分析、文本分类等。\n- **对话系统**:如智能客服、虚拟助手等。\n- **内容生成**:包括文章写作、故事创作、诗歌生成等。\n- **代码生成**:帮助编程人员生成代码片段或完成代码补全。\n- **教育辅助**:提供个性化学习建议和教学材料。\n\n### 2. 技术原理\n\n大型语言模型主要基于神经网络架构,如Transformer模型。这些模型通过训练大量文本数据来学习语言模式,并使用复杂的算法优化其性能。训练过程需要大量的计算资源和时间,但现代云计算技术使得这一过程变得可行。\n\n### 3. 挑战与限制\n\n尽管大型语言模型在许多方面表现出色,但也存在一些挑战和限制:\n\n- **偏见问题**:模型可能会反映出训练数据中的偏见。\n- **安全性问题**:不当使用可能导致隐私泄露或生成有害信息。\n- **能耗问题**:训练和运行这些模型消耗大量能源。\n- **解释性不足**:模型内部的工作机制难以完全理解或解释。\n\n### 4. 发展趋势\n\n随着技术的进步,研究人员正在努力改进大型语言模型,使其更加高效、安全和可靠。这包括开发新的训练方法、优化模型结构以及增强对模型输出的控制能力。\n\n希望这些信息能帮助您更好地了解大型语言模型!如果您有任何具体的问题或需要更详细的信息,请随时告诉我。",` `"tool_calls": []` `},` `"logprobs": null,` `"finish_reason": "stop",` `"stop_reason": null` `}],` `"usage": {` `"prompt_tokens": 37,` `"total_tokens": 424,` `"completion_tokens": 387,` `"prompt_tokens_details": null` `},` `"prompt_logprobs": null``}
使用vLLM加速后模型的性能如下:
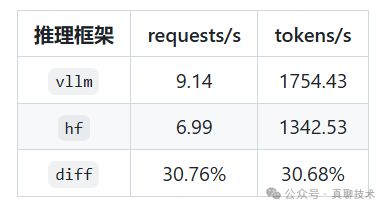
从这个性能对比中可以看到,vllm加速的能力相当可以,基本可以提升30%多。
写在最后
开源模型在应对 RAG 生成任务时表现不错,单卡 4090 足以支持单企业的多人并发 RAG 问答需求。如果业务量较大,可以采用多 GPU 部署,并结合 vLLM 提供的 Nginx 方案实现高效负载均衡。
然而,目前开源模型在知识图谱识别能力上仍有局限。对于 RAG 系统中知识图谱的建立功能,建议引入各大模型厂商的 API 服务进行调用,这样能够显著提升效果,确保数据更精准地满足业务需求。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

读者福利: CSDN大礼包:《最新AI大模型学习资源包》免费分享
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
1.大模型入门学习思维导图
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
2.AGI大模型配套视频
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。

3.大模型实际应用报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

4.大模型落地应用案例PPT
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)
5.大模型经典学习电子书
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)

6.大模型面试题&答案
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

学会后的收获:
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: CSDN大礼包:《最新AI大模型学习资源包》免费分享