Chained Declustering
此论文描述了在无共享架构的多处理器机器上的数据库系统的数据冗余分布方法。该方法提高了系统的可用性,同时在单节点故障的情况下,可以很好的实现负载均衡。以下是论文的一些摘要,详细可以参见论文原文
Tandem’s Mirrored Disks Architecture
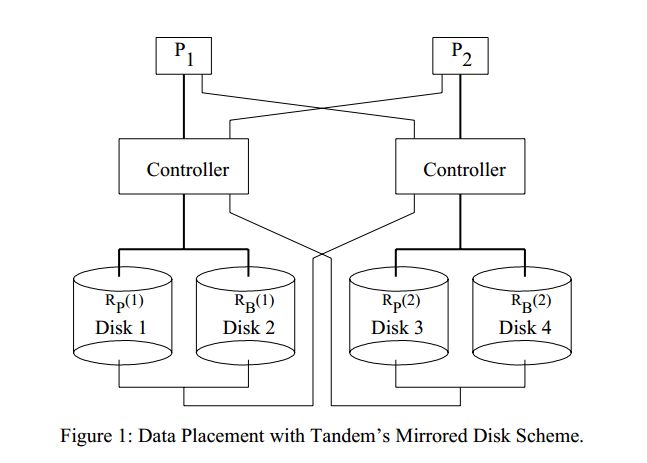
每个disk 分区都有一份copy
每个disk对应两个IO controller
每个controller对应两个Processors
单个disk fail只会影响读,不影响写
单个processor fail 对 cup bound应用影响
每个disk对应两个IO controller
每个controller对应两个Processors
单个disk fail只会影响读,不影响写
单个processor fail 对 cup bound应用影响
Teradata’s Data Clustering Scheme

每个分片通过key hash分布到各个磁盘。
每个分片有主分片和备分片
每个磁盘的备分片平均分配到其它磁盘,当某个磁盘故障时,其它磁盘可以均摊故障磁盘的压力。但是这种分布下,任意两个磁盘同时故障都会导致数据不可用。
只支持hash分区不支持range和round-robin.
RAID’s Data Storage Scheme
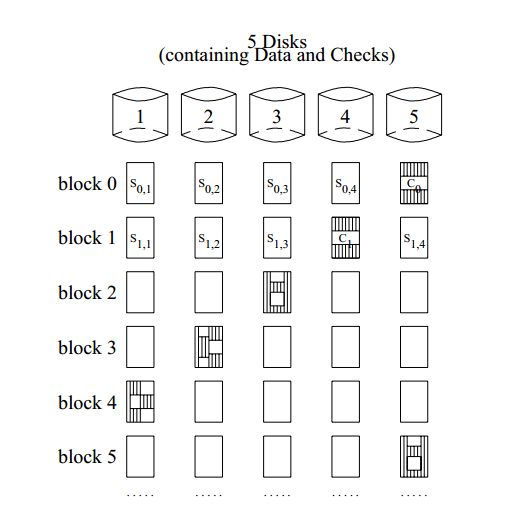
.png)
raid5,奇偶校验信息平均分布到各个磁盘,没次写入都要读取每个磁盘,算出校验信息。
读取只需要读相应的盘,但当出现一个坏盘是,读取需要读每个盘来恢复构造数据。因此raid坏盘是读取会有明显影响。
Chained Declustering Strategy
数据分片算法如下:
Assume that there are a total of M disks numbered from 1 to M. For every relation R, the i-th fragment of the primary copy is stored on the {[i-1+C(R)] mod M + 1}-th disk drive, and the i-th ragment of the backup copy will be stored on the {[i+C(R)] mod M + 1}-th disk drive;insuring that the primary and backup fragments are placed on different disk drives.

relation-cluster:如果节点数过多可以分组为多个relation-cluster;
chain-clusters:如果 relation-cluster中的节点数过多还可以将其分组为多个chain-cluster,单个节点故障后,在故障节点所在的chain-cluster内负载均衡。
下图8个节点组成一个relation-cluster,包含两个chain-cluster,每个chain-cluster包含4个节点
Availability and Load Balancing
集群中磁盘节点数越多,任意两个磁盘同时故障的概率越大。Chained Decluster分组后,只需计算组内的两个磁盘同时故障的概率,故障大大降低。
Responsible Range and Extent Map
active fragment table:每个节点都有主备数据,active fragment table用来就记录主备数据分别那部分数据用于当前访问。正常情况只访问主数据,此时active fragment table记录的只是主数据;只有当节点故障才访问备数据,此时active fragment table记录了主备数据的访问分配情况。
Responsible Range:对于range分区指定边界范围
对于hash分区指定fold范围
Extent Map:对于heap组织的数据指定extent的物理地址范围
Load Balancing Algorithm
Changing the Selection Predicate:
Adding a Selection Predicate
Using the Extent Map
文中举了三个例子,其中对于hash分区例子,通过分区值得到主数据所在节点,然后通过active fragment table确定访问主数据节点还是备数据节点。
Availability and Performance
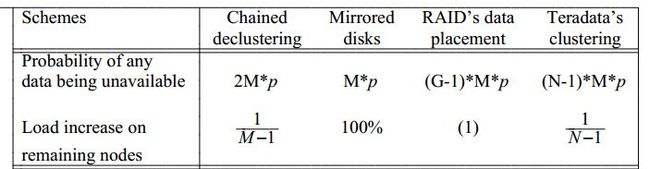
一些思考:
两个节点fail(不是逻辑相邻的节点)后如何分布:负载将不一定均衡,4节点是均衡的,5节点不军衡(1-5节点,2,4同时故障,3节点作为2和4的相邻节点,其主备数据都要完整访问,占整个数据的2/5,而实际上每个节点占1/3才平均)2/N=1/N-2=>N=4 故障节点只相邻一个节点情况下只有4节点是平衡的。其它情况6个节点2个故障也可以达到平衡。
active fragment table的维护代价:每个表可能有多个active fragment table
负载均衡算法只考虑读的情况,写本身是均衡的。均衡算法跟原始数据分布是否均匀有关,而且4.4的表格中还列了些均衡不可用的情况。
如何增加节点 ?
参考:
H.-I. Hsiao and D. J. DeWitt, “Chained declustering: A new availability strategy for multiprocessor database machines,”in roceedings of Sixth International Conference on Data Engineering (ICDE), pp. 456–465,Los Angeles, CA, November 1990.