【自然语言处理(NLP)】序列数据研究(创建序列数据、简单的MLP模型、预测结果分析)
文章目录
- 介绍
- 序列数据研究
-
- 导包
- 安装d2l
- 创建序列数据
- 创建模型
- 开始训练
- 预测
- 多步预测
- 结论
个人主页:道友老李
欢迎加入社区:道友老李的学习社区
介绍
自然语言处理(Natural Language Processing,NLP)是计算机科学领域与人工智能领域中的一个重要方向。它研究的是人类(自然)语言与计算机之间的交互。NLP的目标是让计算机能够理解、解析、生成人类语言,并且能够以有意义的方式回应和操作这些信息。
NLP的任务可以分为多个层次,包括但不限于:
- 词法分析:将文本分解成单词或标记(token),并识别它们的词性(如名词、动词等)。
- 句法分析:分析句子结构,理解句子中词语的关系,比如主语、谓语、宾语等。
- 语义分析:试图理解句子的实际含义,超越字面意义,捕捉隐含的信息。
- 语用分析:考虑上下文和对话背景,理解话语在特定情境下的使用目的。
- 情感分析:检测文本中表达的情感倾向,例如正面、负面或中立。
- 机器翻译:将一种自然语言转换为另一种自然语言。
- 问答系统:构建可以回答用户问题的系统。
- 文本摘要:从大量文本中提取关键信息,生成简短的摘要。
- 命名实体识别(NER):识别文本中提到的特定实体,如人名、地名、组织名等。
- 语音识别:将人类的语音转换为计算机可读的文字格式。
NLP技术的发展依赖于算法的进步、计算能力的提升以及大规模标注数据集的可用性。近年来,深度学习方法,特别是基于神经网络的语言模型,如BERT、GPT系列等,在许多NLP任务上取得了显著的成功。随着技术的进步,NLP正在被应用到越来越多的领域,包括客户服务、智能搜索、内容推荐、医疗健康等。
序列数据研究
导包
# 导包
import torch
from torch import nn
import matplotlib.pyplot as plt
安装d2l
d2l 是一个与《动手学深度学习》(Dive into Deep Learning)一书配套的 Python 库,旨在为读者提供一个实践平台,以便他们能够更容易地理解和实现书中介绍的各种深度学习概念和算法。这个库简化了许多常见的深度学习任务,如数据加载、模型定义、训练循环等,并且提供了丰富的示例代码和教程。
pip install d2l -i https://pypi.tuna.tsinghua.edu.cn/simple
from d2l import torch as d2l
创建序列数据
# 创建序列
# 创建1000个点
T = 1000
time = torch.arange(1, T + 1, dtype=torch.float32)
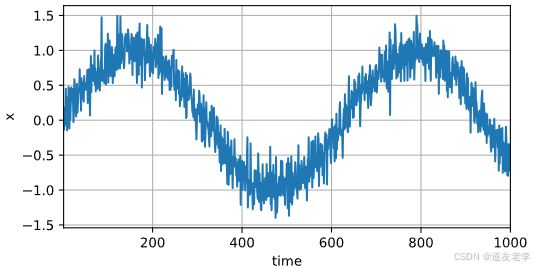
# 创建正弦数据, 加上噪声
x = torch.sin(0.01 * time) + torch.normal(0, 0.2, (T, ))
d2l.plot(time, [x], xlabel='time', ylabel='x', xlim=[1, 1000], figsize=(6, 3))
# plt.plot(time, x)
# plt.xlabel('time')
# plt.ylabel('x')
# plt.xlim(1, 1000)
# plt.grid()
X, y 自回归, X, y都是同一组序列数据, 只不过X是历史数据, y是将来数据.
# X, y 自回归, X, y都是同一组序列数据, 只不过X是历史数据, y是将来数据.
tau = 4
features = torch.zeros((T - tau, tau))
# features.shape
# 对features每一列进行赋值
for i in range(tau):
features[:, i] = x[i: T - tau + i ]
# print(i, T - tau + i)
# 创建labels
labels = x[tau:].reshape((-1, 1))
batch_size, n_train = 16, 600
# 生成dataset
train_iter = d2l.load_array((features[:n_train], labels[:n_train]), batch_size, is_train=True)
创建模型
初始化网络权重的函数、创建一个简单的多层神经网络(感知机)
# 初始化网络权重的函数
def init_weights(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
# 创建模型
# 创建一个简单的多层神经网络(感知机)
def get_net():
net = nn.Sequential(nn.Linear(4, 10),
nn.ReLU(),
nn.Linear(10, 1))
net.apply(init_weights)
return net
# 定义损失
# mse 均方误差
loss = nn.MSELoss()
开始训练
# 开始训练
def train(net, train_iter, loss, epochs, lr):
trainer = torch.optim.Adam(net.parameters(), lr)
for epoch in range(epochs):
for X, y in train_iter:
# 梯度归零=
trainer.zero_grad()
l = loss(net(X), y)
l.backward()
trainer.step()
print(f'epoch {epoch + 1}',
f'loss: {d2l.evaluate_loss(net, train_iter, loss):f}')
net = get_net()
train(net, train_iter, loss, 5, 0.01)
epoch 1 loss: 0.062547
epoch 2 loss: 0.054180
epoch 3 loss: 0.053983
epoch 4 loss: 0.051070
epoch 5 loss: 0.050659
预测
# 预测
onestep_preds = net(features)
# 预测结果和真实结果画在一起, 看一下预测的准不准.
d2l.plot([time, time[tau:]], [x.detach().numpy(), onestep_preds.detach().numpy()],
'time', 'x', legend=['data', '1-step preds'], xlim=[1, 1000], figsize=(6, 3))
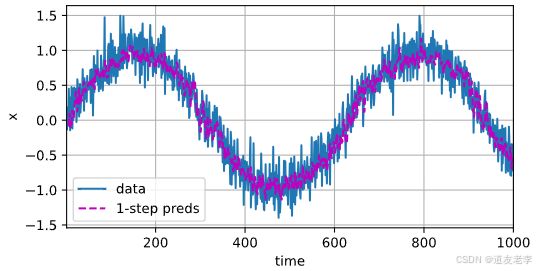
从图中可以看到,单步预测(蓝色线)与原始数据(橙色线)非常接近,特别是在训练集范围内,说明模型对于短期预测具有较高的准确性。
多步预测
# 多步预测
multistep_preds = torch.zeros(T)
# 原始数据
multistep_preds[:n_train + tau] = x[: n_train + tau]
for i in range(n_train + tau, T):
multistep_preds[i] = net(multistep_preds[i - tau: i].reshape((1, -1)))
# 画图
d2l.plot([time, time[tau:], time[n_train + tau:]],
[x.detach().numpy(), onestep_preds.detach().numpy(),
multistep_preds[n_train + tau:].detach().numpy()],
'time', 'x', legend=['data', '1-step preds', 'multistep preds'],
xlim=[0, 1000], figsize=(6, 3))
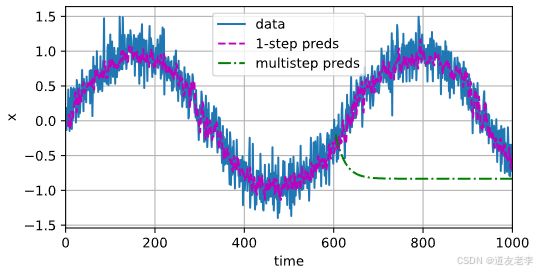
从上图可以看出,多步预测(绿色线)在较长时间段内开始偏离实际数据,尤其是在超出训练范围之后,这反映了模型对未来更远时间点的预测能力有限。
为了进一步理解多步预测的效果,展示不同步数(如1步、4步、16步和64步)预测之间的差异。
# 观察k步预测的结果
max_steps = 64
features = torch.zeros((T - tau - max_steps + 1, tau + max_steps))
# 给前面tau列赋值
for i in range(tau):
features[:, i] = x[i: i + T - tau - max_steps + 1]
# 再给后面tau 到 tau + max_steps列赋值
for i in range(tau, tau + max_steps):
features[:, i] = net(features[:, i - tau: i]).reshape(-1)
# k步
steps = (1, 4, 16, 64)
d2l.plot([time[tau + i -1 : T - max_steps + i] for i in steps],
[features[:, (tau + i - 1)].detach().numpy() for i in steps],
'time', 'x',
legend=[f'{i}-step preds' for i in steps], xlim=[5, 1000],
figsize=(6, 3))
观察k步预测的结果
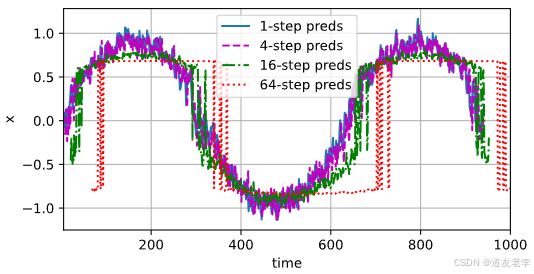
从这张图可以明显看出:
- 1步预测:几乎完全贴合实际数据,表明短期内预测效果很好。
- 4步预测:虽然有一定偏差,但仍然保持了大致的趋势。
- 16步预测:随着时间推移,预测结果逐渐远离实际数据,显示出更大的波动。
- 64步预测:几乎失去了与实际数据的相关性,预测曲线变得平坦或随机。
结论
- 单步预测:在单步预测中,模型每次只预测下一个时间点的值,并且使用真实的过去数据作为输入特征。这通常会给出较为准确的短期预测,因为模型可以直接基于实际的历史数据进行预测。
- 多步预测:当涉及到多步预测时,情况变得复杂。这里,模型需要根据之前预测出的结果来预测未来的值,而不是依赖于真实的历史数据。随着预测步数的增加,累积误差也会逐渐增大,导致预测精度下降。
通过以上分析可以看出,尽管简单的MLP模型可以在短期内提供相对准确的时间序列预测,但其多步预测性能较差,尤其是在没有真实历史数据的情况下。这是因为每一步预测中的小误差会在后续步骤中被放大,最终导致长期预测失效。对于需要进行长程预测的应用场景,可能需要考虑更加复杂的模型结构(例如RNN、LSTM、GRU等),或者采用其他策略来减缓误差累积的影响,比如滚动预测方法。此外,还可以探索增强模型表达能力的技术,如注意力机制,以改进对时间序列数据的理解和预测。