Django:ORM,mysql,django中多数据库操作
目录
读写分离
1.构造表结构
2.对数据库数据的读取操作
简单版
基于router的改进版
按app划分
1.构造表结构
2.对数据库数据的读取操作
简单版
基于router的改进版
单app中的分库操作
1.构造表结构
2.对数据库数据的读写操作
简单版
基于router的改进版
最后总结一下router
读写分离
读写分离是让数据库的读写操作被分配到不同的数据库服务器上,从而提高可用性。
这种分库方式是,要各数据库的表结构要一致,但读写操作分离
注意:django不管读写一致,但可以基于组件做同步
1.构造表结构
终端执行:python manage.py makemigrations ,生成配置文件
终端执行:python manage.py migrate,默认是(python manage.py migrate --database==default),将配置文件提交到默认数据库进行表结构操作
终端执行:python manage.py migrate --database==db02 ,将配置文件提交到指定的数据库db02进行操作
2.对数据库数据的读取操作
简单版
Student.objects.using('default').create(name='DPT',age=100) #对默认数据库进行操作
res = Student.objects.using('db02').all() #对名为db02的数据库进行操作基于router的改进版
但django还提供了一种更为简便的方法,在项目的 app 目录下创建一个 db_router.py 文件,并定义一个数据库路由类。
class MasterSlaveDBRouter:
def db_for_read(self, model, **hints):
# 返回用于读操作的数据库名称
return 'db02'
def db_for_write(self, model, **hints):
# 返回用于写操作的数据库名称
return 'default'要在settings中配置该方法,
DATABASE_ROUTERS = ['app.db_router.MasterSlaveDBRouter']
之后读操作就自动操作db02数据库,写操作操作default数据库
按app划分
这种分库方式是要求各app都有自己的库,互不干扰
1.构造表结构
终端执行:python manage.py makemigrations ,生成配置文件
终端执行:python manage.py migrate app01 --database==default
终端执行:python manage.py migrate app02 --database==db02
将两个app的数据库分开
运行后在数据库中结构如下,
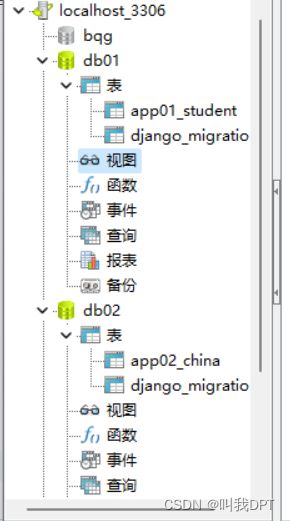
2.对数据库数据的读取操作
简单版
def index(request):
'''
根据app分库的普通方法
'''
res1 = a1.Student.objects.all()
print(res1)
# res2 = a2.China.objects.all() #直接只要写会报错
'''
(1146, "Table 'db01.app02_china' doesn't exist")
以为a1默认查询default数据库,但是default库中没有表China,所有要改为查询db02库中的China表
'''
res2 = a2.China.objects.using('db02').all() #运行成功
print(res2)
return HttpResponse('返回')基于router的改进版
router文件 ,一定要在settings中设置
class DBRouter:
def db_for_read(self, model, **hints):
if model._meta.app_label == 'app01':
return 'default'
elif model._meta.app_label == 'app02':
return 'db02'
views文件
def index(request):
'''
根据app分库的的基于router方法
'''
res1 = a1.Student.objects.all()
print(res1)
res2 = a2.China.objects.all()
print(res2)
return HttpResponse('返回')
单app中的分库操作
1.构造表结构
单app的分表要基于router
举个例子:将Student,Teacher放到default库,将Course放到db02库
models.py
from django.db import models
#default
class Student(models.Model):
name = models.CharField(max_length=16)
age = models.IntegerField()
#default
class Teacher(models.Model):
name = models.CharField(max_length=16)
age = models.IntegerField()
#db02
class Course(models.Model):
name = models.CharField(max_length=16)router.py
class dbRouter:
def allow_migrate(self, db, app_label, model_name=None, **hints):
'''
该方法要与命令行结合使用
python manage.py migrate app01 --database=default
python manage.py migrate app01 --database=db02
db表示数据default或db02
app_label表示app01
model_name表示models中的类名(表名)
'''
if db == 'default':
if model_name in ('student','teacher'): #modle_name自动将名称改为全部小写
return True
else:
return False
if db == 'db02':
if model_name in ('course'):
return True
else:
return False要与命令行结合着看,其实就是在dbRouter类中做一个判断,根据执行的命令行,先判断数据库,再判断对象名(表名)的逻辑进行分发。
可以想象一个场景,就是在一个app中有多个数据库,但是数据库都比较挑剔,default数据库只要student和teacher,db02只要course,当你在 python manage.py migrate app01 --database=default等命令行时,只能把符合要求的对象提交给数据库。
成功的数据库表结构如下,
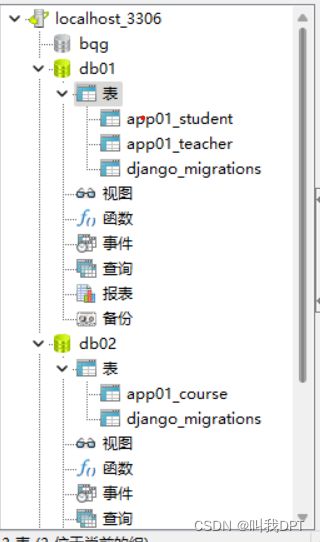
2.对数据库数据的读写操作
简单版
不再赘述
def index(request):
res1 = a1.Student.objects.all()
print(res1)
res2 = a1.Teacher.objects.all()
print(res2)
res3 = a1.Course.objects.using('db02').all()
print(res3)
return HttpResponse("返回")基于router的改进版
router.py中的db_for_read和db_for_write方法
router文件 ,一定要在settings中设置
def db_for_read(self, model, **hints):
if model._meta.model_name in ('student','teacher'):
return 'default'
elif model._meta.model_name in ('course'):
return 'db02'
def db_for_write(self, model, **hints):
if model._meta.model_name in ('student','teacher'):
return 'default'
elif model._meta.model_name in ('course'):
return 'db02'
views.py文件
def index(request):
'''
单app分库的的基于router方法
'''
res1 = a1.Student.objects.all()
print(res1)
res2 = a1.Teacher.objects.all()
print(res2)
res3 = a1.Course.objects.all()
print(res3)
return HttpResponse("返回")
最后总结一下router
Router 在 Django 中的作用是动态决定模型的数据库操作(如读写)应该映射到哪个数据库,以便实现复杂的数据库路由策略,如读写分离或分库分表。
其实,Router就是帮助我们根据模型(数据库表结构)和操作类型(读写操作)自动选择正确的数据库,以便进行读写分离或管理多个数据库。
本人也处于学习阶段,若有错误与不足请指出,关注DPT一起进步吧。